
2 Python自动化办公"案例"
自动化办公案例
需求一:


#读取目标文本文件 def get_str(path): f = open(path,encoding="utf-8") data = f.read() f.close() return data import re #正则获取文本号码 def get_phone_number(str): res = re.findall(r'(13\d{9}|14[5|7]\d{8}|15\d{9}|166{\d{8}|17[3|6|7]{\d{8}|18\d{9})', str) return res #保存得到号码 def save_res(res,save_path): save_file = open(save_path, 'w') for phone in res: save_file.write(phone) save_file.write('\n') save_file.write('\n号码共计:'+str(len(res))) save_file.close() print('号码读取OK,号码共计:'+str(len(res))) # 调用代码 path=input("请输入文件路径:") save_path=input("请输入文件保存路径:") #read_str=get_str(path) res=get_phone_number(get_str(path)) save_res(res,save_path)
import xlwt #读取目标文本文件 def get_str(path): f = open(path,encoding="utf-8") data = f.read() f.close() return data #保存为Excel文件 def save_excel(save_path,sheetname,column_name_list,read_list): workbook = xlwt.Workbook() sheet1 = workbook.add_sheet(sheetname=sheetname) for i in range(0,len(column_name_list)): sheet1.write(0,i,column_name_list[i]) i=1 for v in read_list: kval=v.split(':') for j in range(0,len(kval)): sheet1.write(i+1,j,kval[j]) i=i+1 workbook.save(save_path) print('信息保存 OK,记录条数共计:'+str(len(read_list))) # 调用代码 path=input("请输入文件路径:") save_path=input("请输入文件保存路径:") sheet_name=input("请输入sheetname:") column_name=input("请输入列名,并且使用英文逗号隔开:") column_name_list=column_name.split(',') read_str=get_str(path) read_list=read_str.split('\n') save_excel(save_path,sheet_name,column_name_list,read_list)
import re #正则获取目标信息 def get_re_str(str): res = re.findall(r'^[A-Za-z0-9\u4e00-\u9fa5]+@[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)+$', str) return res #读取目标文本文件 def get_str(path): f = open(path,encoding="utf-8") data = f.read() f.close() return data #保存得到的信息 def save_res(res,save_path): save_file = open(save_path, 'w') for phone in res: save_file.write(phone) save_file.write('\n') save_file.close() print('信息读取OK,信息共计:'+str(len(res))) path=input("请输入文件路径:") save_path=input("请输入文件保存路径:") #read_str=get_str(path) res=get_re_str(get_str(path)) save_res(res,save_path)
#安装好 opencv 库 import cv2 import os path=input("请输入需要加水印的文件夹路径:") file_list = os.listdir(path) for filename in file_list: img1 = cv2.imread(path+filename,cv2.IMREAD_COLOR) cv2.putText(img1,'CSDN',(10,10) , 1, 1, (255,255,255),1) #图片,文字,位置,字体,字号,颜色,厚度 cv2.imwrite(path+filename, img1)
#如何去删除重复文件呢?没错,是使用文件的 md5 值进行对照,相同文件的 #md5 值一样,只需要遍历该目录的文件 md5 值,若出现重复 md5 则删除#该文件即可 import hashlib,os def getMD5(filepath): f = open(filepath,'rb') md5obj = hashlib.md5() md5obj.update(f.read()) hash = md5obj.hexdigest() f.close() return str(hash).upper() path=input("请输入需要重复文件过滤文件夹路径:") file_list = os.listdir(path) file_md5=[] for filename in file_list: md5val=getMD5(path+filename) if md5val in file_md5: os.remove(path+filename) else: file_md5.append(md5val) print("处理完毕...")
#读取目标文本文件 def get_str(path): f = open(path) data = f.read() f.close() return data path=input("请输入文件路径:") word=re.findall('([\u4e00-\u9fa5])',get_str(path)) print("中文字符,除特殊字符外共:",len(word))
import qrcode qr = qrcode.QRCode( version=2,#尺寸 error_correction=qrcode.constants.ERROR_CORRECT_L,#容错信息当前为 7% 容错 box_size=10,#每个格子的像素大小 border=1#边框格子宽度 )#设置二维码的大小 qr.add_data("https://www.csdn.net/")#指定 url img = qr.make_image()#生成二维码图片 img.save("F:\work\day7\csdn.png")#保存
import imageio image_list = [r'F:\work\day4\1.png', r'F:\work\day4\2.png'] gif_name = r'F:\work\day4\gif.gif' frames = [] for image_name in image_list: frames.append(imageio.imread(image_name)) #gif_name 保存路径信息、frames 图片信息、‘GIF’ 生成图片类型以及 gif #图的切换秒数 duration 参数为 2 imageio.mimsave(gif_name, frames, 'GIF', duration=2)
from translate import Translator translator = Translator(to_lang="Chinese") def get_str(path): f = open(path) data = f.read() f.close() return data path=input("请输入文件路径:") text=get_str(path) translation = translator.translate(text) print(translation)
#对视频进行操作可以使用 moviepy 库 from moviepy.editor import AudioFileClip #随后使用 AudioFileClip 获取视频信息 my_audio_clip = AudioFileClip("E:\PyVedio\py02.mp4") #视频的音频写入到文件 my_audio_clip.write_audiofile("E:\PyVedio\py02.wav")
需求二:
多个Excel合并
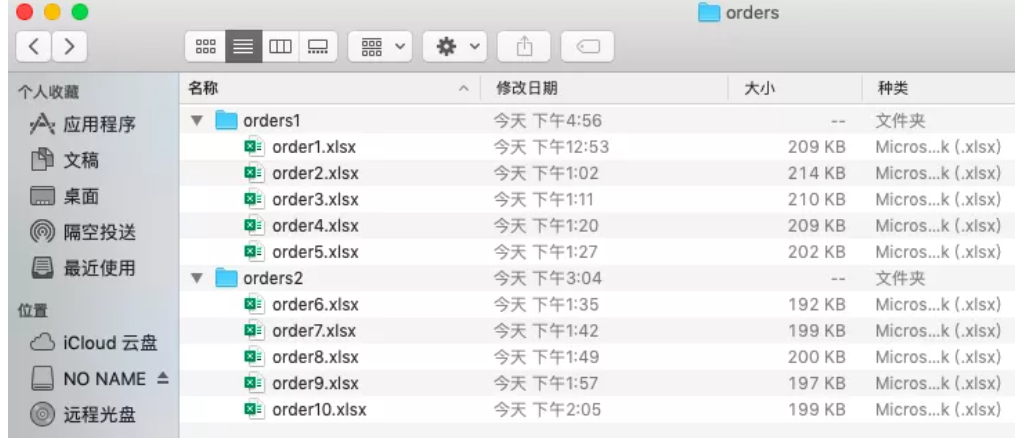
1.合并指定目录下的所有订单表;
import pandas as pd from pathlib import Path files = Path("orders/orders1").glob("*.xlsx") dfs = [pd.read_excel(f) for f in files] df = pd.concat(dfs) df.to_excel("result2.xlsx",index = False)
2.合并指定目录下的指定订单表;
dfs = [pd.read_excel(f) for f in ('orders/orders1/order1.xlsx','orders/orders1/order2.xlsx')] df = pd.concat(dfs) df.to_excel("result3.xlsx",index = False)
3.合并指定目录下的指定订单表的指定字段;
table1 = pd.read_excel("orders/orders1/order1.xlsx") table2 = pd.read_excel('orders/orders1/order2.xlsx') part1 = table1.iloc[:,2] #取order1.xlsx第3列的所有行 part2 = table2.iloc[:,[8,9]] #取order2.xlsx的第9、10列的所有行 result4 = pd.concat([part1,part2],axis = 1 ) #合并
4.合并所有目录下的所有订单表。
import pandas as pd import os file_list = os.walk("./") result = [] for dir_path,dirs,files in file_list: for f in files: file_path = os.path.join(dir_path,f) #重构文件路径 print(file_path) if 'xlsx' in f: #只要xlsx文件 df = pd.read_excel(file_path) #将Excel转成DataFrame result.append(df) print(result) df = pd.concat(result) #多个DataFrame合成一个 df.to_excel("result4.xlsx",index=False) #导入到一个新的Excel中
需求三:
在一个局域网内,共享一个文件夹里内容
IP地址:192.168.0.111 共享文件夹:file
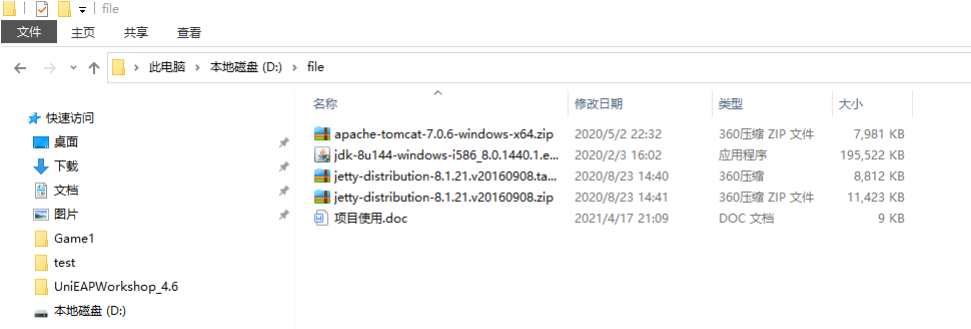
实现:
#python一键共享 PS D:\file> python -m http.server 9090
#通过http直接访问
浏览器打开 http://192.168.0.111:9090
作者:华王
博客:https://www.cnblogs.com/huahuawang/

