
第十三篇 爬虫-selenium
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
相关资源:
https://www.liaoxuefeng.com/wiki/1016959663602400/1183249464292448
Request文档链接:https://docs.python-requests.org/zh_CN/latest/user/quickstart.html#
selenium文档链接:https://selenium-python.readthedocs.io/
小技巧:
1 快速封装headers
正则替换-快速加引号(ctrl+r) (.*?):(.*) '$1':'$2', headers ={ 'referer':' https://www.cnblogs.com/huahuawang/p/14888490.html', 'sec-ch-ua':' " Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"', 'sec-ch-ua-mobile':' ?0', 'sec-fetch-dest':' empty', 'sec-fetch-mode':' cors', 'sec-fetch-site':' same-origin', 'user-agent':' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36', 'x-requested-with':' XMLHttpRequest', }
2 使用request获取cookie字典
import requests # cookie =requests.get("http://www.baidu.com").cookies cookie = requests.utils.dict_from_cookiejar(requests.get('https://beian.miit.gov.cn').cookies) print(cookie) #{'__jsluid_s': '2abf53f44acfc2f70e783cb757bc9833'}
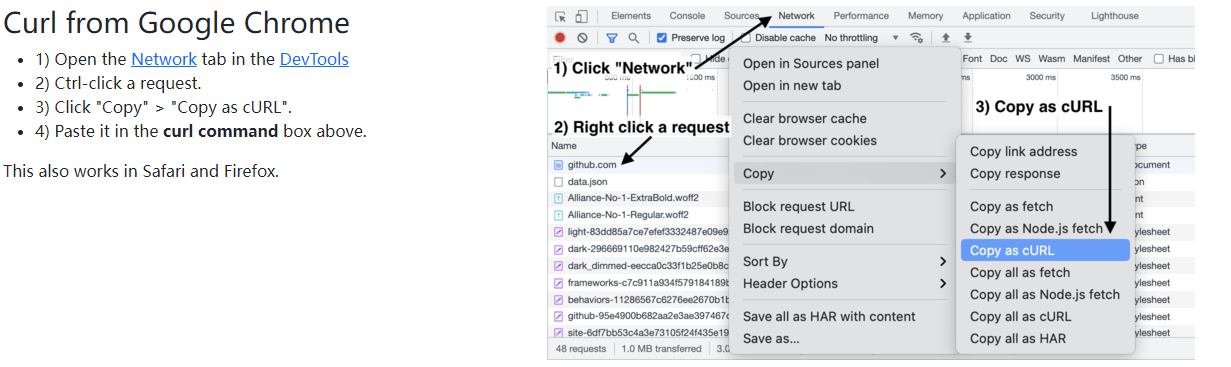
转换网站:https://curlconverter.com/#
使用方法:
5 类封装示例
技术:封装headers;反爬:爬取时间,timeout等;request封装


class BaseSpider(object): headers = { 'Accept': 'text/html,application/xhtml+xml,application/xml;' 'q=0.9,image/webp,image/apng,*/*;q=0.8', 'Accept-Encoding': 'gzip, deflate, br', 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8', 'Connection': 'keep-alive', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) ' 'AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/64.0.3282.119 Safari/537.36', 'Upgrade-Insecure-Requests': '1', } request_sleep = 0.7 _time_recode = 0 number = 0 def request(self, method='get', url=None, encoding=None, **kwargs): if not kwargs.get('headers'): kwargs['headers'] = self.headers if not kwargs.get('timeout'): kwargs['timeout'] = 5 rand_multi = random.uniform(0.8, 1.2) interval = time.time() - self._time_recode if interval < self.request_sleep: time.sleep((self.request_sleep - interval) * rand_multi) resp = getattr(requests, method)(url, **kwargs) self._time_recode = time.time() self.number = self.number + 1 if encoding: resp.encoding = encoding return resp.text class Job51Spider(BaseSpider, metaclass=SpiderMeta): request_sleep = 0 def run(self): conf = configparser.ConfigParser() conf.read('./spider/conf.ini') citycode = conf['citycode'][self.city] page = 1 # 获得总页数 url = "https://search.51job.com/list/{},000000,0100%252C2400%252C2700%252C2500,00,9,99,{},2," \ "{}.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99" \ "&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line" \ "=&specialarea=00&from=&welfare=".format(citycode, self.job, page) a = self.request(url=url, method='get', encoding='GBK') js = etree.HTML(a).xpath('/html/body/script[2]/text()')[0] # 注意解析变成html里的js变量了 jsonCode = js.partition('=')[2].strip() json_res = json.loads(jsonCode) maxpage = eval(json_res['total_page']) # 解析页数 while True: url = "https://search.51job.com/list/{},000000,0100%252C2400%252C2700%252C2500,00,9,99,{},2," \ "{}.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99" \ "&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line" \ "=&specialarea=00&from=&welfare=".format(citycode, self.job, page) self.get_urls(url) log.printlog('多线程+' + str(page) + '页完成--' + self.city + self.job) page = page + 1 if page == maxpage + 1: break return 'over' def get_urls(self, url): try: a = self.request(url=url, method='get', encoding='GBK') js = etree.HTML(a).xpath('/html/body/script[2]/text()')[0] # 注意解析变成html里的js变量了 jsonCode = js.partition('=')[2].strip() json_res = json.loads(jsonCode) urls = [i['job_href'] for i in json_res['engine_search_result']] if threading.activeCount() > 10: log.printlog(str(threading.activeCount()) + '线程存在,请注意检查程序外部阻塞原因') time.sleep(3) if self.threads: for i in urls: t = threading.Thread(target=self.get_job_detail, args=(i,)) t.start() time.sleep(0.03) else: for i in urls: self.get_job_detail(i) except Exception as e: traceback.print_exc() time.sleep(2) self.get_urls(url) def get_job_detail(self, url): if 'jobs' not in url: return try: while True: try: a = self.request(url=url, method='get', encoding='GBK') html = etree.HTML(a) break except: time.sleep(3) try: pay = html.xpath('/ html / body / div[3] / div[2] / div[2] / div / div[1] / strong/text()')[0].strip() except: pay = '' list1 = html.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/p[2]/@title')[0].split("|") list1 = [i.strip() for i in list1] if '招' in list1[2]: education = None else: education = list1[2] result = { 'keyword': self.job, 'provider': '前程无忧网', 'place': self.city, 'title': html.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/h1/text()')[0].strip(), 'salary': pay, 'experience': list1[1], 'education': education, 'companytype': html.xpath('/html/body/div[3]/div[2]/div[4]/div[1]/div[2]/p[1]/text()')[0].strip(), 'industry': html.xpath('/html/body/div[3]/div[2]/div[4]/div[1]/div[2]/p[3]/text()')[0].strip(), 'description': html.xpath(' / html / body / div[3] / div[2] / div[3] / div[1] / div')[0].xpath( 'string(.)').strip().replace('"', '').strip().replace('\t', '').replace('\r', '').replace('\n', '') } self.queue.put(result) return except: time.sleep(3) return
Requests基础
urllib(过时)
# 爬虫: 通过编写程序来获取到互联网上的资源 # 百度 # 需求: 用程序模拟浏览器. 输入一个网址. 从该网址中获取到资源或者内容 # python搞定以上需求. 特别简单 from urllib.request import urlopen url = "http://www.baidu.com" resp = urlopen(url) with open("mybaidu.html", mode="w",encoding='utf-8') as f: f.write(resp.read().decode("utf-8")) # 读取到网页的页面源代码 print("over!")
get请求
# 安装requests # pip install requests # 国内源 # pip install -i https://pypi.tuna.tsinghua.edu.cn/simple requests import requests from fake_useragent import UserAgent query = input("输入一个你喜欢的明星") url = f'https://www.sogou.com/web?query={query}' #UA = UserAgent().random # 获取随机的UA headers = {'User-Agent':UserAgent().random}
resp = requests.get(url, headers=headers) # 处理一个小小的反爬 print(resp.text) # 拿到页面源代码
post请求
import requests url = "https://fanyi.baidu.com/sug" s = input("请输入你要翻译的英文单词") date = {"kw": s} # 发送post请求, 发送的数据必须放在字典中, 通过data参数进行传递 resp = requests.post(url, data=date) print(resp.json()) # 将服务器返回的内容直接处理成json() => dict
get请求 -参数封装
import requests from fake_useragent import UserAgent url = "https://movie.douban.com/j/chart/top_list" # 重新封装参数 param = { "type": "24", "interval_id": "100:90", "action": "", "start": 0, "limit": 20, } headers = {'User-Agent': UserAgent().random}
# 核心代码: resp = requests.get(url=url, params=param, headers=headers) print(resp.json()) resp.close() # 关掉resp
get:示例:爬取搜狗图片(get,image,进度条,random时间等待)
import requests import random import time import json from tqdm import trange url = "https://pic.sogou.com/napi/pc/searchList" url_list =[] start =0 # 重新封装参数 param = { "mode": 1, "start": start, "xml_len": 48, "query": "运煤车" } headers = {'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36"} for i in trange(30): resp = requests.get(url=url, params=param, headers=headers) # resp.json()["data"]["items"] resp_img_list =[item["thumbUrl"] for item in resp.json()["data"]["items"]] param["start"]+=48 url_list.extend(resp_img_list) time.sleep(random.uniform(1,4)) #防止反爬,休息一下 print("当前爬取了图片个数为----", len(url_list)) # resp.close() # 关掉resp #保存url列表数据,防止加载失败 print("总共爬取了图片个数为----",len(url_list)) with open("img_list.txt","w",encoding="utf-8") as f: f.write(json.dumps(url_list)) # 开始发起请求,获取图片数据 for index,url in enumerate(url_list): try: img_obj =requests.get(url,headers=headers,timeout=5).content with open(f"sougou_pic/{index}.jpg", "wb") as f: f.write(img_obj) time.sleep(random.uniform(0, 1)) print(f"{index}.jpg--下载完毕!!") except Exception as e: print(e)
session请求
import requests from fake_useragent import UserAgent # 创建session对象 session = requests.session() # 设置请求头 session.headers = { "User-Agent": UserAgent().random } # 发起请求 res=session.get("https://shared.ydstatic.com/fanyi/newweb/v1.1.6/scripts/newweb/fanyi.min.js").content.decode() print(res)
文件处理为jsonl(eval方法)
#!\Users\Local\Programs\Python37 # -*- coding: utf-8 -*- import json def save_data_jsonl(data_dict_list,path="./new_id_source.jsonl"): """将数据保存为jsonl格式""" with open(path,mode='a',encoding="utf-8") as fp: for data_dict in data_dict_list: fp.write(json.dumps(data_dict,ensure_ascii=False)+"\n") def read_jsonl(path="./baidu.jsonl"): """读取jsonl文件,返回字典对象列表""" data_dict_list=[] with open(path,mode="r",encoding="utf-8") as fp: lines =fp.readlines() for line in lines: data_dict =json.loads(line) # eval函数 执行字符串表达式 :eval("{a:1}")-->{a:1} data_dict_list.append(data_dict) return data_dict_list
数据解析(正则-xpath-bs4)
聚焦爬虫:爬取页面中指定的页面内容。 - 编码流程: - 指定url - 发起请求 - 获取响应数据 - 数据解析 - 持久化存储 数据解析分类: - 正则 - bs4 - xpath(***) 数据解析原理概述: - 解析的局部的文本内容都会在标签之间或者标签对应的属性中进行存储 - 1.进行指定标签的定位 - 2.标签或者标签对应的属性中存储的数据值进行提取(解析) 正则解析: <div class="thumb"> <a href="/article/121721100" target="_blank"> <img src="//pic.qiushibaike.com/system/pictures/12172/121721100/medium/DNXDX9TZ8SDU6OK2.jpg" alt="指引我有前进的方向"> </a> </div> ex = '<div class="thumb">.*?<img src="(.*?)" alt.*?</div>' bs4进行数据解析 - 数据解析的原理: - 1.标签定位 - 2.提取标签、标签属性中存储的数据值 - bs4数据解析的原理: - 1.实例化一个BeautifulSoup对象,并且将页面源码数据加载到该对象中 - 2.通过调用BeautifulSoup对象中相关的属性或者方法进行标签定位和数据提取 - 环境安装: - pip install bs4 - pip install lxml - 如何实例化BeautifulSoup对象: - from bs4 import BeautifulSoup - 对象的实例化: - 1.将本地的html文档中的数据加载到该对象中 fp = open('./test.html','r',encoding='utf-8') soup = BeautifulSoup(fp,'lxml') - 2.将互联网上获取的页面源码加载到该对象中 page_text = response.text soup = BeatifulSoup(page_text,'lxml') - 提供的用于数据解析的方法和属性: - soup.tagName:返回的是文档中第一次出现的tagName对应的标签 - soup.find(): - find('tagName'):等同于soup.div - 属性定位: -soup.find('div',class_/id/attr='song') - soup.find_all('tagName'):返回符合要求的所有标签(列表) - select: - select('某种选择器(id,class,标签...选择器)'),返回的是一个列表。 - 层级选择器: - soup.select('.tang > ul > li > a'):>表示的是一个层级, 返回列表 - soup.select('.tang > ul a'):空格表示的多个层级 - 获取标签之间的文本数据: - soup.a.text/string/get_text() - text/get_text():可以获取某一个标签中所有的文本内容 - string:只可以获取该标签下面直系的文本内容 - 获取标签中属性值: - soup.a['href'] xpath解析:最常用且最便捷高效的一种解析方式。通用性。 - xpath解析原理: - 1.实例化一个etree的对象,且需要将被解析的页面源码数据加载到该对象中。 - 2.调用etree对象中的xpath方法结合着xpath表达式实现标签的定位和内容的捕获。 - 环境的安装: - pip install lxml - 如何实例化一个etree对象:from lxml import etree - 1.将本地的html文档中的源码数据加载到etree对象中: etree.parse(filePath) - 2.可以将从互联网上获取的源码数据加载到该对象中 etree.HTML('page_text') - xpath('xpath表达式') - xpath表达式: - /:表示的是从根节点开始定位。表示的是一个层级。 - //:表示的是多个层级。可以表示从任意位置开始定位。 - 属性定位://div[@class='song'] tag[@attrName="attrValue"] - 索引定位://div[@class="song"]/p[3] 索引是从1开始的。 - 取文本: - /text() 获取的是标签中直系的文本内容 - //text() 标签中非直系的文本内容(所有的文本内容) - 取属性: /@attrName ==>img/src - 过滤: car = self.browser.find_element_by_xpath("//li[contains(text(),'汽车')]") #标签内文本包含汽车 page_url_xml = xml.xpath('/html/body/div[5]/div/div[1]/div/div[3]//li[not(@class)]') # 过滤出 li标签没有类属性的
补充
re: # findall 匹配所有,返回列表 lst = re.findall(r"\d+", "我的电话号是:10086, 我女朋友的电话是:10010") print(lst) # ['10086', '10010'] xpath:
# 1 获取文本 ,注意返回的是一个列表,需[0]取出
text =item.xpath("./text()")[0]
# 2 子元素修饰 /bookstore/book[price>35.00] # 子元素price的值大于35 # 3 contains //li[contains(@id,"ww")] # 属性id包含"ww"文本 //li[contains(text(),'汽车')] ##文本包含汽车 //li[not(@class)] # 过滤出li标签没有类属性的
# 4 | (或)
//book/title | //book/price #选取book元素的所有 title 和 price 元素
综合练习(爬取百家号,腾讯新闻数据,以及相关数据处理)
#!\Users\Local\Programs\Python37 # -*- coding: utf-8 -*- """爬取百家号,腾讯新闻 对应数据源""" import requests from fake_useragent import UserAgent from lxml import etree import re UA = UserAgent().random # 获取随机的UA headers = { 'User-Agent': UA } def get_baidu_source(url): # url ="https://baijiahao.baidu.com/s?id=1696429717489273654&wfr=spider&for=pc" try: res =requests.get(url=url,headers=headers) xml =etree.HTML(res.text) source =xml.xpath("/html/body/div/div/div/div[2]/div[1]/div/div/div[2]/a/p/text()")[0] except Exception as e: print("baidu",e) return None return source def get_tencent_news_source(url="https://new.qq.com/rain/a/20210325A0BSXB00"): # url ="https://new.qq.com/rain/a/20210327A00UVK00" try: res = requests.get(url=url, headers=headers) s =res.text obj = re.compile(r'<script>window.DATA =.*"media": (?P<media>.*?),.*</script>', re.S) # re.S: 让.能匹配换行符 source =obj.search(s) if not source: return None except Exception as e: print("tencent",e) return None return source.group("media") if __name__ == '__main__': print(get_tencent_news_source())
#!\Users\Local\Programs\Python37 # -*- coding: utf-8 -*- from mysql_utils import sql_helper import json from crawl_source import get_tencent_news_source,get_baidu_source import time import random from concurrent.futures import ThreadPoolExecutor """将数据保存为jsonl格式""" def save_data_jsonl(data_dict_list,path="./new_id_source.jsonl"): with open(path,mode='a',encoding="utf-8") as fp: for data_dict in data_dict_list: fp.write(json.dumps(data_dict,ensure_ascii=False)+"\n") """读取jsonl文件,返回字典对象列表""" def read_jsonl(path="./baidu.jsonl"): data_dict_list=[] with open(path,mode="r",encoding="utf-8") as fp: lines =fp.readlines() for line in lines: data_dict =json.loads(line) data_dict_list.append(data_dict) return data_dict_list """获取排除baijiahao & tencent 新闻数据源列表""" def get_data_source_list(data_dict_list): source_list =[] bjh_str = "baijiahao.baidu.com" tencent_news_str = "new.qq.com" for data_dict in data_dict_list: url =data_dict.get("url") if bjh_str not in url and tencent_news_str not in url: source =data_dict.get("source") source_list.append(source) all_source_list=source_list source_list=list(set(source_list)) return source_list,all_source_list """对新闻源数据进行统计,排序...""" def get_source_count(): count_source_list = [] data_list = read_jsonl("./new_id_source.jsonl") source_list, all_source_list = get_data_source_list(data_list) for item in source_list: data_count_dict = {} count = all_source_list.count(item) data_count_dict["count"] = count data_count_dict["source"] = item count_source_list.append(data_count_dict) print("新闻源数据总数为:",len(source_list)) print("排序前的数据:\n",count_source_list) count_source_list.sort(key=lambda source: source["count"],reverse=True) # 按照count进行排序(降序) print("排好序后新数据:\n{}".format(count_source_list)) #按照count进行排序[{'count': 3, 'source': 'www.zhicheng.com'}, {'count': 1, 'source': 'szsb.sznews.com'}, {'count': 1, 'source': 'futures.eastmoney.com'}] save_data_jsonl(count_source_list, path="sort_source.jsonl") """根据sql获取所有新闻详情数据""" def get_data(): sql ='SELECT * from news_detail WHERE web_source="baidu" AND pred != "";' data_dict_list =sql_helper.SQLHelper.fetch_all_dict_list(sql) return data_dict_list """多线程爬取""" def download_data(data_dict): # 原始数据 url = data_dict.get("url") id = data_dict.get("id") bjh_str = "baijiahao.baidu.com" tencent_news_str = "new.qq.com" # 新数据 data_obj = {} data_obj["id"] = id data_obj["url"] = url if bjh_str in url: source = get_baidu_source(url) elif tencent_news_str in url: print(url) source = get_tencent_news_source(url) else: source = url.split("/")[2] data_obj["source"] = source id_data_list.append(data_obj) """单线程爬取""" def get_new_data_list(path ="./baidu.jsonl"): id_source_list = [] data_dict_list = read_jsonl(path) for data_dict in data_dict_list: # 原始数据 url = data_dict.get("url") id = data_dict.get("id") bjh_str = "baijiahao.baidu.com" tencent_news_str = "new.qq.com" # 新数据 data_obj = {} data_obj["id"] = id data_obj["url"] = url if bjh_str in url: source = get_baidu_source(url) elif tencent_news_str in url: print(url) source = get_tencent_news_source(url) else: source = url.split("/")[2] data_obj["source"] = source id_source_list.append(data_obj) return id_source_list """启动函数--开始多线程爬取""" def start_tasks(): data_list = read_jsonl() global id_data_list id_data_list = [] # 创建线程池 with ThreadPoolExecutor(50) as t: for data_dict in data_list: # 把下载任务提交给线程池 t.submit(download_data, data_dict) save_data_jsonl(data_dict_list=id_data_list) print("全部下载完毕!") # 测试 def get_company_news_count(): baidu_statics_list =[] """获取百度新闻的数据总数""" company_list =read_jsonl(path="../news_crawl/42公司列表_with_id.jsonl") print(company_list) #[{'short_name': '大悦城', 'full_name': '大悦城控股集团股份有限公司', 'id': 25}, {'short_name': '格林美', 'full_name': '格林美股份有限公司', 'id': 794}] for company_obj in company_list: company_id =company_obj["id"] sql =f"SELECT company as id,count(*)as baidu_news_count FROM news_detail WHERE web_source='baidu' AND company= {company_id};" data_dict =sql_helper.SQLHelper.fetch_all_dict_list(sql)[0] data_dict["company"] =company_obj["short_name"] baidu_statics_list.append(data_dict) save_data_jsonl(baidu_statics_list, path="./baidu_statics.jsonl") # data_dict_list = sql_helper.SQLHelper.fetch_all_list_dict(sql) if __name__ == '__main__': # get_source_count() # start_tasks() # data_list =get_data() # save_data_jsonl(data_list,path="./baidu.jsonl") get_company_news_count()
re
# 1. 定位到2020必看片 # 2. 从2020必看片中提取到子页面的链接地址 # 3. 请求子页面的链接地址. 拿到我们想要的下载地址.... import requests import re domain = "https://www.dytt89.com/" resp = requests.get(domain, verify=False) # verify=False 去掉安全验证 resp.encoding = 'gb2312' # 指定字符集 # print(resp.text) # # 拿到ul里面的li obj1 = re.compile(r"2020必看热片.*?<ul>(?P<ul>.*?)</ul>", re.S) obj2 = re.compile(r"<a href='(?P<href>.*?)'", re.S) obj3 = re.compile(r'◎片 名(?P<movie>.*?)<br />.*?<td ' r'style="WORD-WRAP: break-word" bgcolor="#fdfddf"><a href="(?P<download>.*?)">', re.S) result1 = obj1.finditer(resp.text) child_href_list = [] for it in result1: ul = it.group('ul') # 提取子页面链接: result2 = obj2.finditer(ul) for itt in result2: # 拼接子页面的url地址: 域名 + 子页面地址 child_href = domain + itt.group('href').strip("/") child_href_list.append(child_href) # 把子页面链接保存起来 # 提取子页面内容 for href in child_href_list: child_resp = requests.get(href, verify=False) child_resp.encoding = 'gb2312' result3 = obj3.search(child_resp.text) print(result3.group("movie")) print(result3.group("download")) # break # 测试用
# 拿到页面源代码. requests # 通过re来提取想要的有效信息 re import requests import re import csv url = "https://movie.douban.com/top250" headers = { "user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.192 Safari/537.36" } resp = requests.get(url, headers=headers) page_content = resp.text # 解析数据 obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)' r'</span>.*?<p class="">.*?<br>(?P<year>.*?) .*?<span ' r'class="rating_num" property="v:average">(?P<score>.*?)</span>.*?' r'<span>(?P<num>.*?)人评价</span>', re.S) # 开始匹配 result = obj.finditer(page_content) f = open("data.csv", mode="w",encoding='utf-8') csvwriter = csv.writer(f) for it in result: # print(it,type(it)) # print(it.group("name")) # print(it.group("score")) # print(it.group("num")) # print(it.group("year").strip()) dic = it.groupdict() dic['year'] = dic['year'].strip() csvwriter.writerow(dic.values()) f.close() print("over!")
bs4
官方文档:https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/#id7
# 安装 # pip install bs4 -i 清华 # 1. 拿到页面源代码 # 2. 使用bs4进行解析. 拿到数据 import requests from bs4 import BeautifulSoup import csv url = "http://www.xinfadi.com.cn/marketanalysis/0/list/1.shtml" resp = requests.get(url) f = open("菜价.csv", mode="w",encoding='utf-8') csvwriter = csv.writer(f) # 解析数据 # 1. 把页面源代码交给BeautifulSoup进行处理, 生成bs对象 page = BeautifulSoup(resp.text, "html.parser") # 指定html解析器 # 2. 从bs对象中查找数据 # find(标签, 属性=值) # find_all(标签, 属性=值) # table = page.find("table", class_="hq_table") # class是python的关键字 table = page.find("table", attrs={"class": "hq_table"}) # 和上一行是一个意思. 此时可以避免class # 拿到所有数据行 trs = table.find_all("tr")[1:] for tr in trs: # 每一行 tds = tr.find_all("td") # 拿到每行中的所有td name = tds[0].text # .text 表示拿到被标签标记的内容 low = tds[1].text # .text 表示拿到被标签标记的内容 avg = tds[2].text # .text 表示拿到被标签标记的内容 high = tds[3].text # .text 表示拿到被标签标记的内容 gui = tds[4].text # .text 表示拿到被标签标记的内容 kind = tds[5].text # .text 表示拿到被标签标记的内容 date = tds[6].text # .text 表示拿到被标签标记的内容 csvwriter.writerow([name, low, avg, high, gui, kind, date]) f.close() print("over1!!!!")
# 1.拿到主页面的源代码. 然后提取到子页面的链接地址, href # 2.通过href拿到子页面的内容. 从子页面中找到图片的下载地址 img -> src # 3.下载图片 import requests from bs4 import BeautifulSoup import time url = "https://www.umei.cc/bizhitupian/weimeibizhi/" resp = requests.get(url) resp.encoding = 'utf-8' # 处理乱码 # print(resp.text) # 把源代码交给bs main_page = BeautifulSoup(resp.text, "html.parser") alist = main_page.find("div", class_="TypeList").find_all("a") # print(alist) for a in alist: href = a.get('href') # 直接通过get就可以拿到属性的值 # 拿到子页面的源代码 child_page_resp = requests.get(href) child_page_resp.encoding = 'utf-8' child_page_text = child_page_resp.text # 从子页面中拿到图片的下载路径 child_page = BeautifulSoup(child_page_text, "html.parser") p = child_page.find("p", align="center") img = p.find("img") src = img.get("src") # 下载图片 img_resp = requests.get(src) # img_resp.content # 这里拿到的是字节 img_name = src.split("/")[-1] # 拿到url中的最后一个/以后的内容 with open("img/"+img_name, mode="wb") as f: f.write(img_resp.content) # 图片内容写入文件 print("over!!!", img_name) time.sleep(1) print("all over!!!")
xpath
# xpath 是在XML文档中搜索内容的一门语言 # html是xml的一个子集 """ <book> <id>1</id> <name>野花遍地香</name> <price>1.23</price> <author> <nick>周大强</nick> <nick>周芷若</nick> </author> </book> """ # 安装lxml模块 # pip install lxml -i xxxxxx # xpath解析 from lxml import etree xml = """ <book> <id>1</id> <name>野花遍地香</name> <price>1.23</price> <nick>臭豆腐</nick> <author> <nick id="10086">周大强</nick> <nick id="10010">周芷若</nick> <nick class="joy">周杰伦</nick> <nick class="jolin">蔡依林</nick> <div> <nick>热热热热热1</nick> </div> <span> <nick>热热热热热2</nick> </span> </author> <partner> <nick id="ppc">胖胖陈</nick> <nick id="ppbc">胖胖不陈</nick> </partner> </book> """ tree = etree.XML(xml) # result = tree.xpath("/book") # /表示层级关系. 第一个/是根节点 # result = tree.xpath("/book/name") # result = tree.xpath("/book/name/text()") # text() 拿文本 # result = tree.xpath("/book/author//nick/text()") # // 后代 # result = tree.xpath("/book/author/*/nick/text()") # * 任意的节点. 通配符(会儿) result = tree.xpath("/book//nick/text()") print(result)
from lxml import etree tree = etree.parse("b.html") # result = tree.xpath('/html') # result = tree.xpath("/html/body/ul/li/a/text()") # result = tree.xpath("/html/body/ul/li[1]/a/text()") # xpath的顺序是从1开始数的, []表示索引 # result = tree.xpath("/html/body/ol/li/a[@href='dapao']/text()") # [@xxx=xxx] 属性的筛选 # print(result) # ol_li_list = tree.xpath("/html/body/ol/li") # # for li in ol_li_list: # # 从每一个li中提取到文字信息 # result = li.xpath("./a/text()") # 在li中继续去寻找. 相对查找 # print(result) # result2 = li.xpath("./a/@href") # 拿到属性值: @属性 # print(result2) # # print(tree.xpath("/html/body/ul/li/a/@href")) # print(tree.xpath('/html/body/div[1]/text()')) # print(tree.xpath('/html/body/ol/li/a/text()')) ############# selenium xpath解析 ########## # # car = self.browser.find_element_by_xpath("//li[contains(text(),'汽车')]") #标签内文本包含 # page_url_xml = xml.xpath('/html/body/div[5]/div/div[1]/div/div[3]//li[not(@class)]') # 过滤出 li标签没有类属性的
# 拿到页面源代码 # 提取和解析数据 import requests from lxml import etree url = "https://beijing.zbj.com/search/f/?type=new&kw=saas" resp = requests.get(url) # print(resp.text) # 解析 html = etree.HTML(resp.text) # 拿到每一个服务商的div divs = html.xpath("/html/body/div[6]/div/div/div[2]/div[4]/div[1]/div") for div in divs: # 每一个服务商信息 price = div.xpath("./div/div/a[1]/div[2]/div[1]/span[1]/text()")[0].strip("¥") title = "saas".join(div.xpath("./div/div/a[1]/div[2]/div[2]/p/text()")) com_name = div.xpath("./div/div/a[2]/div[1]/p/text()")[0] location = div.xpath("./div/div/a[2]/div[1]/div/span/text()")[0] print(com_name) print(price)
防盗链-代理-cookie
# 登录 -> 得到cookie # 带着cookie 去请求到书架url -> 书架上的内容 # 必须得把上面的两个操作连起来 # 我们可以使用session进行请求 -> session你可以认为是一连串的请求. 在这个过程中的cookie不会丢失 import requests # # 会话 # session = requests.session() # data = { # "loginName": "18614075987", # "password": "q6035945" # } # # # 1. 登录 # url = "https://passport.17k.com/ck/user/login" # session.post(url, data=data) # # print(resp.text) # # print(resp.cookies) # 看cookie # # # 2. 拿书架上的数据 # # 刚才的那个session中是有cookie的 # resp = session.get('https://user.17k.com/ck/author/shelf?page=1&appKey=2406394919') # # print(resp.json()) resp = requests.get("https://user.17k.com/ck/author/shelf?page=1&appKey=2406394919", headers={ "Cookie":"GUID=bbb5f65a-2fa2-40a0-ac87-49840eae4ad1; c_channel=0; c_csc=web; UM_distinctid=17700bddefba54-0a914fc70f1ede-326d7006-1fa400-17700bddefc9e3; Hm_lvt_9793f42b498361373512340937deb2a0=1614327827; accessToken=avatarUrl%3Dhttps%253A%252F%252Fcdn.static.17k.com%252Fuser%252Favatar%252F16%252F16%252F64%252F75836416.jpg-88x88%253Fv%253D1610625030000%26id%3D75836416%26nickname%3D%25E9%25BA%25BB%25E8%25BE%25A3%25E5%2587%25A0%25E4%25B8%259D%26e%3D1629888002%26s%3D63b8b7687fc8a717; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2275836416%22%2C%22%24device_id%22%3A%2217700ba9c71257-035a42ce449776-326d7006-2073600-17700ba9c728de%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%2C%22first_id%22%3A%22bbb5f65a-2fa2-40a0-ac87-49840eae4ad1%22%7D; Hm_lpvt_9793f42b498361373512340937deb2a0=1614336271" }) print(resp.text)
# 1. 拿到contId # 2. 拿到videoStatus返回的json. -> srcURL # 3. srcURL里面的内容进行修整 # 4. 下载视频 import requests # 拉取视频的网址 url = "https://www.pearvideo.com/video_1725137" contId = url.split("_")[1] videoStatusUrl = f"https://www.pearvideo.com/videoStatus.jsp?contId={contId}" headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.192 Safari/537.36", # 防盗链: 溯源, 当前本次请求的上一级是谁 "Referer": url } resp = requests.get(videoStatusUrl, headers=headers) dic = resp.json() srcUrl = dic['videoInfo']['videos']['srcUrl'] systemTime = dic['systemTime'] srcUrl = srcUrl.replace(systemTime, f"cont-{contId}") # 下载视频 with open("a.mp4", mode="wb") as f: f.write(requests.get(srcUrl).content)
# 原理. 通过第三方的一个机器去发送请求 import requests # 118.186.63.71:8080 proxies = { "https": "https://118.186.63.71:8080" } resp = requests.get("https://www.baidu.com", proxies=proxies) resp.encoding = 'utf-8' print(resp.text)
# 1. 找到未加密的参数 # window.arsea(参数, xxxx,xxx,xxx) # 2. 想办法把参数进行加密(必须参考网易的逻辑), params => encText, encSecKey => encSecKey # 3. 请求到网易. 拿到评论信息 # 需要安装pycrypto: pip install pycrypto """ pip3 install pycryptodome, 对应的import的代码应更改为from Crypto.Cipher import AES; 同时在加密函数那一块的代码还要做如下更改:data=bytes(to_16(data), "utf-8") """ from Crypto.Cipher import AES from base64 import b64encode import requests import json url = "https://music.163.com/weapi/comment/resource/comments/get?csrf_token=" # 请求方式是POST data = { "csrf_token": "", "cursor": "-1", "offset": "0", "orderType": "1", "pageNo": "1", "pageSize": "20", "rid": "R_SO_4_1325905146", "threadId": "R_SO_4_1325905146" } # 服务于d的 f = "00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7" g = "0CoJUm6Qyw8W8jud" e = "010001" i = "d5bpgMn9byrHNtAh" # 手动固定的. -> 人家函数中是随机的 def get_encSecKey(): # 由于i是固定的. 那么encSecText就是固定的. c()函数的结果就是固定的 return "1b5c4ad466aabcfb713940efed0c99a1030bce2456462c73d8383c60e751b069c24f82e60386186d4413e9d7f7a9c7cf89fb06e40e52f28b84b8786b476738a12b81ac60a3ff70e00b085c886a6600c012b61dbf418af84eb0be5b735988addafbd7221903c44d027b2696f1cd50c49917e515398bcc6080233c71142d226ebb" # 把参数进行加密 def get_params(data): # 默认这里接收到的是字符串 first = enc_params(data, g) second = enc_params(first, i) return second # 返回的就是params # 转化成16的倍数, 位下方的加密算法服务 def to_16(data): pad = 16 - len(data) % 16 data += chr(pad) * pad return data # 加密过程 def enc_params(data, key): iv = "0102030405060708" data = to_16(data) aes = AES.new(key=key.encode("utf-8"), IV=iv.encode('utf-8'), mode=AES.MODE_CBC) # 创建加密器 bs = aes.encrypt(data.encode("utf-8")) # 加密, 加密的内容的长度必须是16的倍数 return str(b64encode(bs), "utf-8") # 转化成字符串返回, # 处理加密过程 """ function a(a = 16) { # 随机的16位字符串 var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = ""; for (d = 0; a > d; d += 1) # 循环16次 e = Math.random() * b.length, # 随机数 1.2345 e = Math.floor(e), # 取整 1 c += b.charAt(e); # 去字符串中的xxx位置 b return c } function b(a, b) { # a是要加密的内容, var c = CryptoJS.enc.Utf8.parse(b) # # b是秘钥 , d = CryptoJS.enc.Utf8.parse("0102030405060708") , e = CryptoJS.enc.Utf8.parse(a) # e是数据 , f = CryptoJS.AES.encrypt(e, c, { # c 加密的秘钥 iv: d, # 偏移量 mode: CryptoJS.mode.CBC # 模式: cbc }); return f.toString() } function c(a, b, c) { # c里面不产生随机数 var d, e; return setMaxDigits(131), d = new RSAKeyPair(b,"",c), e = encryptedString(d, a) } function d(d, e, f, g) { d: 数据, e: 010001, f: 很长, g: 0CoJUm6Qyw8W8jud var h = {} # 空对象 , i = a(16); # i就是一个16位的随机值, 把i设置成定值 h.encText = b(d, g) # g秘钥 h.encText = b(h.encText, i) # 返回的就是params i也是秘钥 h.encSecKey = c(i, e, f) # 得到的就是encSecKey, e和f是定死的 ,如果此时我把i固定, 得到的key一定是固定的 return h } 两次加密: 数据+g => b => 第一次加密+i => b = params """ # 发送请求. 得到评论结果 resp = requests.post(url, data={ "params": get_params(json.dumps(data)), "encSecKey": get_encSecKey() }) print(resp.text)
异步高效爬取
# 1. 如何提取单个页面的数据 # 2. 上线程池,多个页面同时抓取 import requests from lxml import etree import csv from concurrent.futures import ThreadPoolExecutor f = open("data.csv", mode="w", encoding="utf-8") csvwriter = csv.writer(f) def download_one_page(url): # 拿到页面源代码 resp = requests.get(url) html = etree.HTML(resp.text) table = html.xpath("/html/body/div[2]/div[4]/div[1]/table")[0] # trs = table.xpath("./tr")[1:] trs = table.xpath("./tr[position()>1]") # 拿到每个tr for tr in trs: txt = tr.xpath("./td/text()") # 对数据做简单的处理: \\ / 去掉 txt = (item.replace("\\", "").replace("/", "") for item in txt) # 把数据存放在文件中 csvwriter.writerow(txt) print(url, "提取完毕!") if __name__ == '__main__': # for i in range(1, 14870): # 效率及其低下 # download_one_page(f"http://www.xinfadi.com.cn/marketanalysis/0/list/{i}.shtml") # 创建线程池 with ThreadPoolExecutor(50) as t: for i in range(1, 100): # 199 * 20 = 3980 # 把下载任务提交给线程池 t.submit(download_one_page, f"http://www.xinfadi.com.cn/marketanalysis/0/list/{i}.shtml") print("全部下载完毕!")
# import time # # # def func(): # print("我爱黎明") # time.sleep(3) # 让当前的线程处于阻塞状态. CPU是不为我工作的 # print("我真的爱黎明") # # # if __name__ == '__main__': # func() # # """ # # input() 程序也是处于阻塞状态 # # requests.get(bilibili) 在网络请求返回数据之前, 程序也是处于阻塞状态的 # # 一般情况下, 当程序处于 IO操作的时候. 线程都会处于阻塞状态 # # # 协程: 当程序遇见了IO操作的时候. 可以选择性的切换到其他任务上. # # 在微观上是一个任务一个任务的进行切换. 切换条件一般就是IO操作 # # 在宏观上,我们能看到的其实是多个任务一起在执行 # # 多任务异步操作 # # # 上方所讲的一切. 都是在单线程的条件下 # """ # python编写协程的程序 import asyncio import time # async def func(): # print("你好啊, 我叫赛利亚") # # # if __name__ == '__main__': # g = func() # 此时的函数是异步协程函数. 此时函数执行得到的是一个协程对象 # # print(g) # asyncio.run(g) # 协程程序运行需要asyncio模块的支持 # async def func1(): # print("你好啊, 我叫潘金莲") # # time.sleep(3) # 当程序出现了同步操作的时候. 异步就中断了 # await asyncio.sleep(3) # 异步操作的代码 # print("你好啊, 我叫潘金莲") # # # async def func2(): # print("你好啊, 我叫王建国") # # time.sleep(2) # await asyncio.sleep(2) # print("你好啊, 我叫王建国") # # # async def func3(): # print("你好啊, 我叫李雪琴") # await asyncio.sleep(4) # print("你好啊, 我叫李雪琴") # # # if __name__ == '__main__': # f1 = func1() # f2 = func2() # f3 = func3() # tasks = [ # f1, f2, f3 # ] # t1 = time.time() # # 一次性启动多个任务(协程) # asyncio.run(asyncio.wait(tasks)) # t2 = time.time() # print(t2 - t1) async def func1(): print("你好啊, 我叫潘金莲") await asyncio.sleep(3) print("你好啊, 我叫潘金莲") async def func2(): print("你好啊, 我叫王建国") await asyncio.sleep(2) print("你好啊, 我叫王建国") async def func3(): print("你好啊, 我叫李雪琴") await asyncio.sleep(4) print("你好啊, 我叫李雪琴") async def main(): # 第一种写法 # f1 = func1() # await f1 # 一般await挂起操作放在协程对象前面 # 第二种写法(推荐) tasks = [ asyncio.create_task(func1()), # py3.8以后加上asyncio.create_task() asyncio.create_task(func2()), asyncio.create_task(func3()) ] await asyncio.wait(tasks) if __name__ == '__main__': t1 = time.time() # 一次性启动多个任务(协程) asyncio.run(main()) t2 = time.time() print(t2 - t1) # # 在爬虫领域的应用 # async def download(url): # print("准备开始下载") # await asyncio.sleep(2) # 网络请求 requests.get() # print("下载完成") # # # async def main(): # urls = [ # "http://www.baidu.com", # "http://www.bilibili.com", # "http://www.163.com" # ] # # # 准备异步协程对象列表 # tasks = [] # for url in urls: # d = asycio.create_task(download(url)) # tasks.append(d) # # # tasks = [asyncio.create_task(download(url)) for url in urls] # 这么干也行哦~ # # # 一次性把所有任务都执行 # await asyncio.wait(tasks) # # if __name__ == '__main__': # asyncio.run(main())
# requests.get() 同步的代码 -> 异步操作aiohttp # pip install aiohttp import asyncio import aiohttp urls = [ "http://kr.shanghai-jiuxin.com/file/2020/1031/191468637cab2f0206f7d1d9b175ac81.jpg", "http://kr.shanghai-jiuxin.com/file/2020/1031/563337d07af599a9ea64e620729f367e.jpg", "http://kr.shanghai-jiuxin.com/file/2020/1031/774218be86d832f359637ab120eba52d.jpg" ] async def aiodownload(url): # 发送请求. # 得到图片内容 # 保存到文件 name = url.rsplit("/", 1)[1] # 从右边切, 切一次. 得到[1]位置的内容 async with aiohttp.ClientSession() as session: # requests async with session.get(url) as resp: # resp = requests.get() # 请求回来了. 写入文件 # 可以自己去学习一个模块, aiofiles with open(name, mode="wb") as f: # 创建文件 f.write(await resp.content.read()) # 读取内容是异步的. 需要await挂起, resp.text() print(name, "搞定") async def main(): tasks = [] for url in urls: tasks.append(aiodownload(url)) await asyncio.wait(tasks) if __name__ == '__main__': asyncio.run(main())
# https://boxnovel.baidu.com/boxnovel/wiseapi/chapterList?bookid=4306063500 # http://dushu.baidu.com/api/pc/getCatalog?data={"book_id":"4306063500"} => 所有章节的内容(名称, cid) # 章节内部的内容 # http://dushu.baidu.com/api/pc/getChapterContent?data={"book_id":"4306063500","cid":"4306063500|11348571","need_bookinfo":1} import requests import asyncio import aiohttp import aiofiles import json """ 1. 同步操作: 访问getCatalog 拿到所有章节的cid和名称 2. 异步操作: 访问getChapterContent 下载所有的文章内容 """ async def aiodownload(cid, b_id, title): data = { "book_id":b_id, "cid":f"{b_id}|{cid}", "need_bookinfo":1 } data = json.dumps(data) url = f"http://dushu.baidu.com/api/pc/getChapterContent?data={data}" async with aiohttp.ClientSession() as session: async with session.get(url) as resp: dic = await resp.json() async with aiofiles.open(f'novel/{title}', mode="w", encoding="utf-8") as f: await f.write(dic['data']['novel']['content']) # 把小说内容写出 async def getCatalog(url): resp = requests.get(url) dic = resp.json() tasks = [] for item in dic['data']['novel']['items']: # item就是对应每一个章节的名称和cid title = item['title'] cid = item['cid'] # 准备异步任务 tasks.append(aiodownload(cid, b_id, title)) await asyncio.wait(tasks) if __name__ == '__main__': b_id = "4306063500" url = 'http://dushu.baidu.com/api/pc/getCatalog?data={"book_id":"' + b_id + '"}' asyncio.run(getCatalog(url))
视频
# <video src="不能播的视频.mp4"></video> # 一般的视频网站是怎么做的? # 用户上传 -> 转码(把视频做处理, 2K, 1080, 标清) -> 切片处理(把单个的文件进行拆分) 60 # 用户在进行拉动进度条的时候 # ================================= # 需要一个文件记录: 1.视频播放顺序, 2.视频存放的路径. # M3U8 txt json => 文本 # 想要抓取一个视频: # 1. 找到m3u8 (各种手段) # 2. 通过m3u8下载到ts文件 # 3. 可以通过各种手段(不仅是编程手段) 把ts文件合并为一个mp4文件
""" 流程: 1. 拿到548121-1-1.html的页面源代码 2. 从源代码中提取到m3u8的url 3. 下载m3u8 4. 读取m3u8文件, 下载视频 5. 合并视频 """ import requests import re # headers = { # "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.192 Safari/537.36" # } # # obj = re.compile(r"url: '(?P<url>.*?)',", re.S) # 用来提取m3u8的url地址 # # url = "https://www.91kanju.com/vod-play/54812-1-1.html" # # resp = requests.get(url, headers=headers) # m3u8_url = obj.search(resp.text).group("url") # 拿到m3u8的地址 # # # print(m3u8_url) # resp.close() # # # 下载m3u8文件 # resp2 = requests.get(m3u8_url, headers=headers) # # with open("哲仁王后.m3u8", mode="wb") as f: # f.write(resp2.content) # # resp2.close() # print("下载完毕") # 解析m3u8文件 n = 1 with open("哲仁王后.m3u8", mode="r", encoding="utf-8") as f: for line in f: line = line.strip() # 先去掉空格, 空白, 换行符 if line.startswith("#"): # 如果以#开头. 我不要 continue # 下载视频片段 resp3 = requests.get(line) f = open(f"video/{n}.ts", mode="wb") f.write(resp3.content) f.close() resp3.close() n += 1 print("完成了1个")
""" 思路: 1. 拿到主页面的页面源代码, 找到iframe 2. 从iframe的页面源代码中拿到m3u8文件的地址 3. 下载第一层m3u8文件 -> 下载第二层m3u8文件(视频存放路径) 4. 下载视频 5. 下载秘钥, 进行解密操作 6. 合并所有ts文件为一个mp4文件 """ import requests from bs4 import BeautifulSoup import re import asyncio import aiohttp import aiofiles from Crypto.Cipher import AES # pycryptodome import os def get_iframe_src(url): resp = requests.get(url) main_page = BeautifulSoup(resp.text, "html.parser") src = main_page.find("iframe").get("src") return src # return "https://boba.52kuyun.com/share/xfPs9NPHvYGhNzFp" # 为了测试 def get_first_m3u8_url(url): resp = requests.get(url) # print(resp.text) obj = re.compile(r'var main = "(?P<m3u8_url>.*?)"', re.S) m3u8_url = obj.search(resp.text).group("m3u8_url") # print(m3u8_url) return m3u8_url def download_m3u8_file(url, name): resp = requests.get(url) with open(name, mode="wb") as f: f.write(resp.content) async def download_ts(url, name, session): async with session.get(url) as resp: async with aiofiles.open(f"video2/{name}", mode="wb") as f: await f.write(await resp.content.read()) # 把下载到的内容写入到文件中 print(f"{name}下载完毕") async def aio_download(up_url): # https://boba.52kuyun.com/20170906/Moh2l9zV/hls/ tasks = [] async with aiohttp.ClientSession() as session: # 提前准备好session async with aiofiles.open("越狱第一季第一集_second_m3u8.txt", mode="r", encoding='utf-8') as f: async for line in f: if line.startswith("#"): continue # line就是xxxxx.ts line = line.strip() # 去掉没用的空格和换行 # 拼接真正的ts路径 ts_url = up_url + line task = asyncio.create_task(download_ts(ts_url, line, session)) # 创建任务 tasks.append(task) await asyncio.wait(tasks) # 等待任务结束 def get_key(url): resp = requests.get(url) return resp.text async def dec_ts(name, key): aes = AES.new(key=key, IV=b"0000000000000000", mode=AES.MODE_CBC) async with aiofiles.open(f"video2/{name}", mode="rb") as f1,\ aiofiles.open(f"video2/temp_{name}", mode="wb") as f2: bs = await f1.read() # 从源文件读取内容 await f2.write(aes.decrypt(bs)) # 把解密好的内容写入文件 print(f"{name}处理完毕") async def aio_dec(key): # 解密 tasks = [] async with aiofiles.open("越狱第一季第一集_second_m3u8.txt", mode="r", encoding="utf-8") as f: async for line in f: if line.startswith("#"): continue line = line.strip() # 开始创建异步任务 task = asyncio.create_task(dec_ts(line, key)) tasks.append(task) await asyncio.wait(tasks) def merge_ts(): # mac: cat 1.ts 2.ts 3.ts > xxx.mp4 # windows: copy /b 1.ts+2.ts+3.ts xxx.mp4 lst = [] with open("越狱第一季第一集_second_m3u8.txt", mode="r", encoding="utf-8") as f: for line in f: if line.startswith("#"): continue line = line.strip() lst.append(f"video2/temp_{line}") s = " ".join(lst) # 1.ts 2.ts 3.ts os.system(f"cat {s} > movie.mp4") print("搞定!") def main(url): # 1. 拿到主页面的页面源代码, 找到iframe对应的url iframe_src = get_iframe_src(url) # 2. 拿到第一层的m3u8文件的下载地址 first_m3u8_url = get_first_m3u8_url(iframe_src) # 拿到iframe的域名 # "https://boba.52kuyun.com/share/xfPs9NPHvYGhNzFp" iframe_domain = iframe_src.split("/share")[0] # 拼接出真正的m3u8的下载路径 first_m3u8_url = iframe_domain+first_m3u8_url # https://boba.52kuyun.com/20170906/Moh2l9zV/index.m3u8?sign=548ae366a075f0f9e7c76af215aa18e1 # print(first_m3u8_url) # 3.1 下载第一层m3u8文件 download_m3u8_file(first_m3u8_url, "越狱第一季第一集_first_m3u8.txt") # 3.2 下载第二层m3u8文件 with open("越狱第一季第一集_first_m3u8.txt", mode="r", encoding="utf-8") as f: for line in f: if line.startswith("#"): continue else: line = line.strip() # 去掉空白或者换行符 hls/index.m3u8 # 准备拼接第二层m3u8的下载路径 # https://boba.52kuyun.com/20170906/Moh2l9zV/ + hls/index.m3u8 # https://boba.52kuyun.com/20170906/Moh2l9zV/hls/index.m3u8 # https://boba.52kuyun.com/20170906/Moh2l9zV/hls/cFN8o3436000.ts second_m3u8_url = first_m3u8_url.split("index.m3u8")[0] + line download_m3u8_file(second_m3u8_url, "越狱第一季第一集_second_m3u8.txt") print("m3u8文件下载完毕") # 4. 下载视频 second_m3u8_url_up = second_m3u8_url.replace("index.m3u8", "") # 异步协程 asyncio.run(aio_download(second_m3u8_url_up)) # 测试的使用可以注释掉 # 5.1 拿到秘钥 key_url = second_m3u8_url_up + "key.key" # 偷懒写法, 正常应该去m3u8文件里去找 key = get_key(key_url) # 5.2 解密 asyncio.run(aio_dec(key)) # 6. 合并ts文件为mp4文件 merge_ts() if __name__ == '__main__': url = "https://www.91kanju.com/vod-play/541-2-1.html" main(url) # 简单的问题复杂化, 复杂的问题简单化 # 秒杀()
火狐浏览器爬取百度图片示例
火狐驱动器链接:https://github.com/mozilla/geckodriver/tags
from selenium.webdriver import Firefox import requests import time headers = { 'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36" } web =Firefox(executable_path="./geckodriver.exe") web.get("https://image.baidu.com/search/index?tn=baiduimage&ps=1&ct=201326592&lm=-1&cl=2&nc=1&ie=utf-8&dyTabStr=MCwyLDMsOCwxLDYsNCw1LDcsOQ%3D%3D&word=%E8%BF%90%E7%85%A4%E8%BD%A6") # 执行js脚本,滑动下拉 for i in range(20): web.execute_script('window.scrollBy(0,document.body.scrollHeight)') time.sleep(1) # 解析获取图片,并保存 def scrapy_image(): img_objs = web.find_elements_by_class_name("main_img") for index,img in enumerate(img_objs): url =img.get_attribute("src") print(url) try: img_obj = requests.get(url,headers=headers).content with open(f"crack_pic/{index}.jpg", 'wb') as f: f.write(img_obj) except Exception as e: print(e) scrapy_image() print("爬取完毕!!")
selenium(环境搭建-浏览器驱动镜像源-简单使用)
web.page_source # 网页源代码
web.current_url #当前标签url
web.close() # 关闭当前标签
web.quit() # 关闭浏览器
web.forward() # 页面前进
web.back() # 页面后退
web.save_screenshot(img_name) # 页面截图
from selenium import webdriver from selenium.webdriver.chrome.options import Options # 实例化opt opt = Options() #无头模式 opt.add_argument('--headless') opt.add_argument("--disbale-gpu") ## 禁用GPU加速 # 规避检测 opt.add_experimental_option('excludeSwitches', ['enable-automation']) # 不加载图片 opt.add_argument('--blink-settings=imagesEnabled=false') # 设置窗口大小, 窗口大小会有影响. opt.add_argument('--window-size=1280,1024') # 设置请求头的User-Agent opt.add_argument(' --user-agent="" ') # 禁用浏览器正在被自动化程序控制的提示 opt.add_argument('--disable-infobars') # 隐藏滚动条, 应对一些特殊页面 options.add_argument('--hide-scrollbars') web =Chrome(options=opt)
from selenium.webdriver import Chrome from selenium.webdriver.chrome.options import Options # 实例化opt opt = Options() # opt.add_argument('--headless') # 无头模式 opt.add_argument("--disbale-gpu") opt.add_experimental_option('excludeSwitches', ['enable-automation']) opt.add_argument('--blink-settings=imagesEnabled=false') opt.add_argument('--window-size=1300,1000') web =Chrome(options=opt) web.get("http://www.baidu.com") print(web.get_cookies()[0])
# 安装selenium:
pip install selenium
# 下载浏览器驱动:
https://npm.taobao.org/mirrors/chromedriver #把解压缩的浏览器驱动 chromedriver 放在python解释器所在的文件夹
# 基本使用
from selenium.webdriver import Chrome # 1.创建浏览器对象 web = Chrome() # 2.打开一个网址 web.get("http://www.baidu.com") print(web.title)
#3 获取cookie
cookie_dict =web.get_cookies()[0]
# 4 获取文本内容和属性值
ret=web.find_elements_by_link_text("新闻")
# print(ret)
print(ret[0].get_attribute("href"))
print(ret[0].text)
# 关闭窗口
web.close()
from selenium.webdriver import Chrome from selenium.webdriver.common.keys import Keys import time web = Chrome() web.get("http://lagou.com") # 找到某个元素. 点击它 el = web.find_element_by_xpath('//*[@id="changeCityBox"]/ul/li[1]/a') el.click() # 点击事件 # time.sleep(1) # 让浏览器缓一会儿 # 找到输入框. 输入python => 输入回车/点击搜索按钮 web.find_element_by_xpath('//*[@id="search_input"]').send_keys("python", Keys.ENTER) time.sleep(1) # 查找存放数据的位置. 进行数据提取 # 找到页面中存放数据的所有的li li_list = web.find_elements_by_xpath('//*[@id="s_position_list"]/ul/li') for li in li_list: job_name = li.find_element_by_tag_name("h3").text job_price = li.find_element_by_xpath("./div/div/div[2]/div/span").text company_name = li.find_element_by_xpath('./div/div[2]/div/a').text print(company_name, job_name, job_price)
from selenium.webdriver import Chrome from selenium.webdriver.common.keys import Keys import time web = Chrome() # web.get("http://lagou.com") # # web.find_element_by_xpath('//*[@id="cboxClose"]').click() # # time.sleep(1) # # web.find_element_by_xpath('//*[@id="search_input"]').send_keys("python", Keys.ENTER) # # time.sleep(1) # # web.find_element_by_xpath('//*[@id="s_position_list"]/ul/li[1]/div[1]/div[1]/div[1]/a/h3').click() # # # 如何进入到进窗口中进行提取 # # 注意, 在selenium的眼中. 新窗口默认是不切换过来的. # web.switch_to.window(web.window_handles[-1]) # # # 在新窗口中提取内容 # job_detail = web.find_element_by_xpath('//*[@id="job_detail"]/dd[2]/div').text # print(job_detail) # # # # 关掉子窗口 # web.close() # # 变更selenium的窗口视角. 回到原来的窗口中 # web.switch_to.window(web.window_handles[0]) # print(web.find_element_by_xpath('//*[@id="s_position_list"]/ul/li[1]/div[1]/div[1]/div[1]/a/h3').text) # 如果页面中遇到了 iframe如何处理 web.get("https://www.91kanju.com/vod-play/541-2-1.html") # 处理iframe的话. 必须先拿到iframe. 然后切换视角到iframe . 再然后才可以拿数据 iframe = web.find_element_by_xpath('//*[@id="player_iframe"]') web.switch_to.frame(iframe) # 切换到iframe # web.switch_to.default_content() # 切换回原页面 tx = web.find_element_by_xpath('//*[@id="main"]/h3[1]').text print(tx)
from selenium.webdriver import Chrome from selenium.webdriver.chrome.options import Options from selenium.webdriver.support.select import Select import time # 准备好参数配置 opt = Options() opt.add_argument("--headless") opt.add_argument("--disbale-gpu") web = Chrome(options=opt) # 把参数配置设置到浏览器中 web.get("https://www.endata.com.cn/BoxOffice/BO/Year/index.html") # time.sleep(2) # # 定位到下拉列表 # sel_el = web.find_element_by_xpath('//*[@id="OptionDate"]') # # 对元素进行包装, 包装成下拉菜单 # sel = Select(sel_el) # # 让浏览器进行调整选项 # for i in range(len(sel.options)): # i就是每一个下拉框选项的索引位置 # sel.select_by_index(i) # 按照索引进行切换 # time.sleep(2) # table = web.find_element_by_xpath('//*[@id="TableList"]/table') # print(table.text) # 打印所有文本信息 # print("===================================") # # print("运行完毕. ") # web.close() # 如何拿到页面代码Elements(经过数据加载以及js执行之后的结果的html内容) print(web.page_source)
rom selenium import webdriver from selenium.webdriver.chrome.options import Options ops = Options() ops.add_argument('--user-agent=%s' % ua) # 设置代理 ops.add_argument('--proxy-server=http://%s' % proxy) driver = webdriver.Chrome(executable_path=r"/root/chromedriver", chrome_options=ops) driver.get("http://httpbin.org/") print(driver.page_source) driver.quit()
""" 隐式等待告诉 WebDriver 在尝试查找任何不立即可用的元素(或多个元素)时轮询 DOM 一段时间。默认设置为 0(零) """ from selenium import webdriver driver = webdriver.Chrome() # 最长等待时间 driver.implicitly_wait(10) # seconds driver.get("http://somedomain/url_that_delays_loading") myDynamicElement = driver.find_element_by_id("myDynamicElement")
from selenium import webdriver from time import sleep # 后面是你的浏览器驱动位置,记得前面加r'','r'是防止字符转义的 driver = webdriver.Chrome(r'./chromedriver') # 用get打开百度页面 driver.get("http://www.baidu.com") # 获取页面源码 print(driver.page_source.encode('utf-8')) # 查找页面的“设置”选项,并进行点击 driver.find_elements_by_link_text('设置')[0].click() sleep(2) # # 打开设置后找到“搜索设置”选项,设置为每页显示50条 driver.find_elements_by_link_text('搜索设置')[0].click() sleep(2) # 选中每页显示50条 m = driver.find_element_by_id('nr') sleep(2) m.find_element_by_xpath('//*[@id="nr"]/option[3]').click() m.find_element_by_xpath('.//option[3]').click() sleep(2) # 点击保存设置 driver.find_elements_by_class_name("prefpanelgo")[0].click() sleep(2) # 处理弹出的警告页面 确定accept() 和 取消dismiss() driver.switch_to_alert().accept() sleep(2) # 找到百度的输入框,并输入 美女 driver.find_element_by_id('kw').send_keys('美女') sleep(2) # 点击搜索按钮 driver.find_element_by_id('su').click() sleep(2) # 在打开的页面中找到“Selenium - 开源中国社区”,并打开这个页面 driver.find_elements_by_link_text('美女_百度图片')[0].click() sleep(3) # 执行js脚本,滑动下拉 driver.execute_script("window.scrollBy(0,2000)") driver.execute_script('window.scrollTo(0,document.body.scrollHeight)') # 执行一组js脚本 # 关闭浏览器 driver.quit()
#!\Users\Local\Programs\Python37 # -*- coding: utf-8 -*- from selenium import webdriver from lxml import etree from time import sleep bro =webdriver.Chrome('./Chromedriver.exe') bro.get('http://scxk.nmpa.gov.cn:81/xk/') page_text =bro.page_source tree = etree.HTML(page_text) li_list = tree.xpath('//ul[@id="gzlist"]/li') for li in li_list: name = li.xpath('./dl/@title')[0] print(name) sleep(3) bro.quit()
#!\Users\Local\Programs\Python37 # -*- coding: utf-8 -*- from selenium import webdriver from time import sleep bro = webdriver.Chrome('./chromedriver.exe') bro.get('https://www.taobao.com/') search_input = bro.find_element_by_id('q') search_input.send_keys('华为手机') bro.execute_script('window.scrollTo(0,document.body.scrollHeight)') # 执行一组js脚本 btn =bro.find_element_by_css_selector('.btn-search') btn.click() # 点击搜索按钮 sleep(2) bro.get('https://www.baidu.com') sleep(2) bro.back()#回退 sleep(2) bro.forward()#前进 sleep(2) bro.quit()
from selenium import webdriver from time import sleep #导入动作链对应的类 from selenium.webdriver import ActionChains bro = webdriver.Chrome(executable_path='./chromedriver') bro.get('https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable') #如果定位的标签是存在于iframe标签之中的则必须通过如下操作在进行标签定位 bro.switch_to.frame('iframeResult')#切换浏览器标签定位的作用域 div = bro.find_element_by_id('draggable') #动作链 action = ActionChains(bro) #点击长按指定的标签 action.click_and_hold(div) for i in range(5): #perform()立即执行动作链操作 #move_by_offset(x,y):x水平方向 y竖直方向 action.move_by_offset(17,0).perform() sleep(0.5) #释放动作链 action.release() bro.quit()
#!\Users\Local\Programs\Python37 # -*- coding: utf-8 -*- from selenium import webdriver from time import sleep bro = webdriver.Chrome('./chromedriver.exe') bro.get('https://qzone.qq.com/') bro.switch_to.frame('login_frame') a_tag =bro.find_element_by_id('switcher_plogin') a_tag.click() input_user =bro.find_element_by_id('u') input_pwd =bro.find_element_by_id('p') input_user.send_keys('12344') sleep(1) input_pwd.send_keys('12334') sleep(2) submit_btn =bro.find_element_by_id('login_button') submit_btn.click() sleep(2) bro.quit()
from selenium import webdriver from time import sleep from selenium.webdriver.chrome.options import Options from selenium.webdriver import ChromeOptions #实现无可视化界面的操作 chrome_options = Options() chrome_options.add_argument('--headless') chrome_options.add_argument('--disable-gpu') #实现规避检测 option = ChromeOptions() option.add_experimental_option('excludeSwitches', ['enable-automation']) #实现让selenium规避被检测到的风险 bro = webdriver.Chrome(executable_path='./chromedriver',chrome_options=chrome_options,options=option) bro.get('https://www.baidu.com') print(bro.page_source.encode('utf-8')) sleep(2) bro.quit()
#!\Users\Local\Programs\Python37 # -*- coding: utf-8 -*- import requests from hashlib import md5 from selenium import webdriver import time from PIL import Image from selenium.webdriver import ActionChains class Chaojiying_Client(object): def __init__(self, username, password, soft_id): self.username = username password = password.encode('utf8') self.password = md5(password).hexdigest() self.soft_id = soft_id self.base_params = { 'user': self.username, 'pass2': self.password, 'softid': self.soft_id, } self.headers = { 'Connection': 'Keep-Alive', 'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)', } def PostPic(self, im, codetype): """ im: 图片字节 codetype: 题目类型 参考 http://www.chaojiying.com/price.html """ params = { 'codetype': codetype, } params.update(self.base_params) files = {'userfile': ('ccc.jpg', im)} r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers) return r.json() def ReportError(self, im_id): """ im_id:报错题目的图片ID """ params = { 'id': im_id, } params.update(self.base_params) r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers) return r.json() bro = webdriver.Chrome(executable_path='./chromedriver') bro.get('https://kyfw.12306.cn/otn/login/init') time.sleep(1) # bro.maximize_window() bro.set_window_size(1280, 1024) #设置窗口大小 bro.save_screenshot('12306截图.png') #确定验证码图片对应的左上角和右下角的坐标(裁剪的区域就确定) code_img_ele = bro.find_element_by_xpath('//*[@id="loginForm"]/div/ul[2]/li[4]/div/div/div[3]/img') location = code_img_ele.location size = code_img_ele.size rangle = ( int(location['x']), int(location['y']), int(location['x'] + size['width']), int(location['y'] + size['height'])) #crop根据指定区域进行图片裁剪 i = Image.open('./12306截图.png') code_img_name = './code.png' frame = i.crop(rangle) frame.save(code_img_name) # 将验证码图片提交给超级鹰进行识别,并模拟登录 def Identification_verification_code(): # chaojiying = Chaojiying_Client('超级鹰用户名', '超级鹰用户名的密码', '96001') #用户中心>>软件ID 生成一个替换 96001 chaojiying = Chaojiying_Client('xxxx', 'huawang', ' 911813') im = open('code.png', 'rb').read() result = chaojiying.PostPic(im, 9004)['pic_str'] all_list = [] #要存储即将被点击的点的坐标 [[x1,y1],[x2,y2]] if '|' in result: list_1 = result.split('|') count_1 = len(list_1) for i in range(count_1): xy_list = [] x = int(list_1[i].split(',')[0]) y = int(list_1[i].split(',')[1]) xy_list.append(x) xy_list.append(y) all_list.append(xy_list) else: x = int(result.split(',')[0]) y = int(result.split(',')[1]) xy_list = [] xy_list.append(x) xy_list.append(y) all_list.append(xy_list) print(all_list) #遍历列表,使用动作链对每一个列表元素对应的x,y指定的位置进行点击操作 for l in all_list: x = l[0] y = l[1] ActionChains(bro).move_to_element_with_offset(code_img_ele, x, y).click().perform() time.sleep(0.5) bro.find_element_by_id('username').send_keys('www.zhangbowudi@qq.com') time.sleep(2) bro.find_element_by_id('password').send_keys('15027900535') time.sleep(2) bro.find_element_by_id('loginSub').click() time.sleep(3) bro.quit() Identification_verification_code()
破解验证码(chaojiying)
#!/usr/bin/env python # coding:utf-8 import requests from hashlib import md5 class Chaojiying_Client(object): def __init__(self, username, password, soft_id): self.username = username password = password.encode('utf8') self.password = md5(password).hexdigest() self.soft_id = soft_id self.base_params = { 'user': self.username, 'pass2': self.password, 'softid': self.soft_id, } self.headers = { 'Connection': 'Keep-Alive', 'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)', } def PostPic(self, im, codetype): """ im: 图片字节 codetype: 题目类型 参考 http://www.chaojiying.com/price.html """ params = { 'codetype': codetype, } params.update(self.base_params) files = {'userfile': ('ccc.jpg', im)} r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers) return r.json() def ReportError(self, im_id): """ im_id:报错题目的图片ID """ params = { 'id': im_id, } params.update(self.base_params) r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers) return r.json() if __name__ == '__main__': # 用户中心>>软件ID 生成一个替换 96001 chaojiying = Chaojiying_Client('18614075987', '6035945', '914467') # 本地图片文件路径 来替换 a.jpg 有时WIN系统须要// im = open('code.png', 'rb').read() # im就是图片的所有字节(图片) # 1902 验证码类型 官方网站>>价格体系 print(chaojiying.PostPic(im, 1902))
from selenium.webdriver import Chrome from chaojiying import Chaojiying_Client import time web = Chrome() web.get("http://www.chaojiying.com/user/login/") # 处理验证码 img = web.find_element_by_xpath('/html/body/div[3]/div/div[3]/div[1]/form/div/img').screenshot_as_png chaojiying = Chaojiying_Client('18614075987', '6035945', '914467') dic = chaojiying.PostPic(img, 1902) verify_code = dic['pic_str'] # 向页面中填入用户名, 密码, 验证码 web.find_element_by_xpath('/html/body/div[3]/div/div[3]/div[1]/form/p[1]/input').send_keys("18614075987") web.find_element_by_xpath('/html/body/div[3]/div/div[3]/div[1]/form/p[2]/input').send_keys("6035945") web.find_element_by_xpath('/html/body/div[3]/div/div[3]/div[1]/form/p[3]/input').send_keys(verify_code) time.sleep(5) # 点击登录 web.find_element_by_xpath('/html/body/div[3]/div/div[3]/div[1]/form/p[4]/input').click()
from selenium.webdriver import Chrome from selenium.webdriver.common.action_chains import ActionChains from selenium.webdriver.chrome.options import Options from chaojiying import Chaojiying_Client import time # 初始化超级鹰 chaojiying = Chaojiying_Client('18614075987', '6035945', '914467') # 如果你的程序被识别到了怎么办? # 1.chrome的版本号如果小于88 在你启动浏览器的时候(此时没有加载任何网页内容), 向页面嵌入js代码. 去掉webdriver # web = Chrome() # # web.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", { # "source": """ # navigator.webdriver = undefined # Object.defineProperty(navigator, 'webdriver', { # get: () => undefined # }) # """ # }) # web.get(xxxxxxx) # 2.chrome的版本大于等于88 option = Options() # option.add_experimental_option('excludeSwitches', ['enable-automation']) option.add_argument('--disable-blink-features=AutomationControlled') web = Chrome(options=option) web.get("https://kyfw.12306.cn/otn/resources/login.html") time.sleep(2) web.find_element_by_xpath('/html/body/div[2]/div[2]/ul/li[2]/a').click() time.sleep(3) # 先处理验证码 verify_img_element = web.find_element_by_xpath('//*[@id="J-loginImg"]') # 用超级鹰去识别验证码 dic = chaojiying.PostPic(verify_img_element.screenshot_as_png, 9004) result = dic['pic_str'] # x1,y1|x2,y2|x3,y3 rs_list = result.split("|") for rs in rs_list: # x1,y1 p_temp = rs.split(",") x = int(p_temp[0]) y = int(p_temp[1]) # 要让鼠标移动到某一个位置. 然后进行点击 # 醒了 -> 掀开被子 -> 坐起来 -> 穿鞋子 -> 穿衣服 -> 开始执行动作 ActionChains(web).move_to_element_with_offset(verify_img_element, x, y).click().perform() time.sleep(1) # 输入用户名和密码 web.find_element_by_xpath('//*[@id="J-userName"]').send_keys("123456789") web.find_element_by_xpath('//*[@id="J-password"]').send_keys("12346789") # 点击登录 web.find_element_by_xpath('//*[@id="J-login"]').click() time.sleep(5) # 拖拽 btn = web.find_element_by_xpath('//*[@id="nc_1_n1z"]') ActionChains(web).drag_and_drop_by_offset(btn, 300, 0).perform()
基础使用
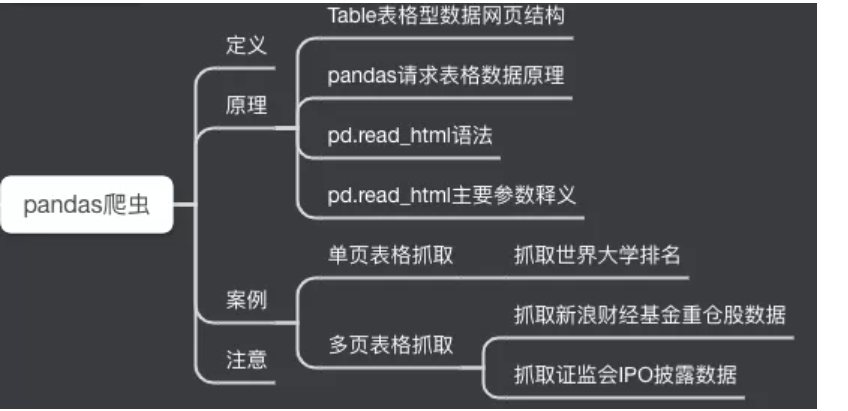
# 一.案例1:抓取世界大学排名(1页数据) import pandas as pd url1 = 'http://www.compassedu.hk/qs' df1 = pd.read_html(url1)[0] #0表示网页中的第一个Table df1.to_csv('世界大学综合排名.csv',index=False) # 不加索引
# 二.案例2:抓取新浪财经基金重仓股数据(6页数据) # import pandas as pd # import csv # df2 = pd.DataFrame() # for i in range(6): # url2 = 'http://vip.stock.finance.sina.com.cn/q/go.php/vComStockHold/kind/jjzc/index.phtml?p={page}'.format(page=i+1) # df2 = pd.concat([df2,pd.read_html(url2)[0]]) # print('第{page}页抓取完成'.format(page = i + 1)) # df2.to_csv('./新浪财经数据.csv',encoding='utf-8',index=False)
# 三.案例3:抓取证监会披露的IPO数据(217页数据) import pandas as pd from pandas import DataFrame import csv import time start = time.time() #计时 df3 = DataFrame(data=None,columns=['公司名称','披露日期','上市地和板块','披露类型','查看PDF资料']) #添加列名 for i in range(1,218): url3 ='http://eid.csrc.gov.cn/ipo/infoDisplay.action?pageNo=%s&temp=&temp1=&blockType=byTime'%str(i) df3_1 = pd.read_html(url3,encoding='utf-8')[2] #必须加utf-8,否则乱码 df3_2 = df3_1.iloc[1:len(df3_1)-1,0:-1] #过滤掉最后一行和最后一列(NaN列) df3_2.columns=['公司名称','披露日期','上市地和板块','披露类型','查看PDF资料'] #新的df添加列名 df3 = pd.concat([df3,df3_2]) #数据合并 print('第{page}页抓取完成'.format(page=i)) df3.to_csv('./上市公司IPO信息.csv', encoding='utf-8',index=True) #保存数据到csv文件 end = time.time() print ('共抓取',len(df3),'家公司,' + '用时',round((end-start)/60,2),'分钟')
from selenium import webdriver from selenium.webdriver.chrome.options import Options from lxml import etree import time import json import random # from testMysql import db_init,getData,updateData,insertData from util import MyHTMLParser import datetime """ 36kr => 汽车 下拉一定程度需点击型 """ class kr36(): def __init__(self,company_name): self.latest_news = [] self.company_name =company_name self.url = f"https://36kr.com/search/articles/{company_name}" self.pages = 1 chrome_driver = "D:\chromedriver_win\chromedriver" chrome_options = Options() #chrome_options.add_argument('--headless') #无头模式 chrome_options.add_experimental_option('excludeSwitches', ['enable-automation']) chrome_options.add_argument('--window-size=1300,1000') # 设置窗口大小, 窗口大小会有影响. prefs = {"profile.managed_default_content_settings.images": 2, 'permissions.default.stylesheet': 2, 'download.prompt_for_download': True, 'safebrowsing': True} # 禁止加载图片和css chrome_options.add_experimental_option("prefs", prefs) self.browser = webdriver.Chrome( executable_path=chrome_driver, options=chrome_options) def get_page_url_list(self): print('爬取公司:',self.company_name) self.browser.get(self.url) page = self.browser.find_elements_by_xpath("//div[@class='kr-loading-more-button show']") for i in range(10): self.browser.execute_script("window.scrollBy(0,2000)") time.sleep(random.uniform(0.5, 1.5)) for i in range(self.pages): try: page[0].click() time.sleep(1) page = self.browser.find_elements_by_xpath("//div[@class='kr-loading-more-button show']") except Exception as e: print(e) with open('./error_logs/company_error_log','a',encoding='utf-8') as f: f.write(f"{self.company_name}--爬取遇到的错误日志--{e}\n") xml = etree.HTML(self.browser.page_source) # oldNews = getData("qichezhizao") # 获取当前已保存的最新5条新闻 # print("oldNews", oldNews) page_url_xml = xml.xpath("//p[@class='title-wrapper ellipsis-2']/a") page_url_list = [] for index,item in enumerate(page_url_xml): if index < 5: print(item.xpath("./text()")[0]) self.latest_news.append(item.xpath("./text()")[0].replace("\"", "“").replace("'","’")) for item in page_url_xml: # if item.xpath("./text()")[0].replace("\"", "“").replace("'","’") not in oldNews: page_url = "https://36kr.com" + item.xpath("./@href")[0] # print(page_url) page_title = item.xpath("./text()")[0].replace("\"", "“").replace("'","’") page_url_list.append( { "title": page_title, "url": page_url } ) print(f"爬取{self.company_name}:",page_url_list) # else: # break return page_url_list def get_page_content(self): page_url_list = self.get_page_url_list()# [{'title': '到2025年谁将是特斯拉最大的竞争对手?', 'url': 'https://36kr.com/p/1182455808770306'}, {'title': '福特「电马」对决Model Y,能砍疼特斯拉吗?'] for page_url in page_url_list: try: time.sleep(random.uniform(0.2,1)) self.browser.get(page_url["url"]) xml = etree.HTML(self.browser.page_source) # title = xml.xpath("//h1[@id='title']/text()")[0].replace("\"", "“").replace("'","’") # print(title) time_box = ''.join(xml.xpath("//span[@class='title-icon-item item-time']/descendant::text()")).split("\xa0")[2] print("time_box", time_box) if "前" in time_box: release_time = datetime.datetime.now().strftime("%Y-%m-%d") elif "昨天" in time_box: release_time = (datetime.datetime.now()+datetime.timedelta(days=-1)).strftime("%Y-%m-%d") else: release_time = time_box # release_time = xml.xpath("//span[@class='date']/text()")[0] source = xml.xpath("//a[@class='title-icon-item item-a']/text()")[0] print(f"release_time:{release_time}###source:{source}") # box_text = ''.join(xml.xpath("//div[@class='box-l']/descendant::text()")) # # source = # print("box_text",box_text) # if "来源" in box_text: # source = box_text.split("来源:")[1] # else: # source = "" # # content_list = xml.xpath("//div[@class='content']/p/text()") # content_list = xml.xpath("//div[@class='common-width content articleDetailContent kr-rich-text-wrapper']/descendant::text()") # content = "" # for i in content_list: # content += "<p>" + i + "</p>" # content = content.replace("\"", "“").replace("'","’") content_list = xml.xpath("//div[@class='common-width content articleDetailContent kr-rich-text-wrapper']")[0] content = etree.tostring(content_list, encoding="utf-8").decode('utf-8') # str_Arr = "" parser = MyHTMLParser() parser.feed(parser.pre_handle(content)) content = parser.get_str() data = {"url": page_url["url"], "title": page_url["title"], "release_time": release_time, "source": source, "content": content, "web_source": "36kr", "source_type": 0} print(data) # insertData(data) with open(f"./download_news/newsList_special_{self.company_name}.jsonl", "a",encoding='utf-8') as f: f.write(json.dumps(data, ensure_ascii=False) + "\n") except Exception as e: print("ERROR",e) # with open("./error_log/error_36kr.jsonl", "a") as f: # f.write(json.dumps(str(e) + "-----" + time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())) + "-----" + page_url["title"] , ensure_ascii=False) + "\n") continue # print(content) print("self.latest_news", self.latest_news) # updateData(self.latest_news, 'qichezhizao') self.browser.close() return True def get_page_content_one(self,url): try: time.sleep(random.uniform(0.2,1)) self.browser.get(url) xml = etree.HTML(self.browser.page_source) # title = xml.xpath("//h1[@id='title']/text()")[0].replace("\"", "“").replace("'","’") # print(title) time_box = ''.join(xml.xpath("//span[@class='title-icon-item item-time']/descendant::text()")).split("\xa0")[2] print("time_box", time_box) if "前" in time_box: release_time = datetime.datetime.now().strftime("%Y-%m-%d") elif "昨天" in time_box: release_time = (datetime.datetime.now()+datetime.timedelta(days=-1)).strftime("%Y-%m-%d") else: release_time = time_box # release_time = xml.xpath("//span[@class='date']/text()")[0] print(release_time) source = xml.xpath("//a[@class='title-icon-item item-a']/text()")[0] content_list = xml.xpath("//div[@class='common-width content articleDetailContent kr-rich-text-wrapper']")[0] content = etree.tostring(content_list, encoding="utf-8").decode('utf-8') # str_Arr = "" parser = MyHTMLParser() parser.feed(parser.pre_handle(content)) content = parser.get_str() self.browser.close() return content except Exception as e: print("ERROR",e) self.browser.close() if __name__ == "__main__": # kr36().get_page_content() f = open("./宝安区首批用户企业_v1.jsonl", "r", encoding="utf-8") lines = f.readlines() for line in lines: dic = json.loads(line) company_name = dic["short_name"] kr36(company_name).get_page_content() # kr36(company_name).get_page_url_list() # kr36().get_page_url_list()
import json # from selenium import webdriver from selenium.webdriver.chrome.options import Options from lxml import etree from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.common.by import By from selenium.webdriver.common.action_chains import ActionChains from selenium.common.exceptions import UnexpectedAlertPresentException from selenium.webdriver.support import expected_conditions as EC import jsonlines import re import time import datetime import selenium import json import random from mysql_utils.testMysql import check_news # from testMysql import db_init,get_latest_data,updateData,insertData # from util import MyHTMLParser # import sys # sys.path.append("./Bayes") # from ana import getType # from util import MyHTMLParser ''' 百度新闻 => 公司相关新闻 点击翻页型 ''' def format_date(date): if "前" in date: date_format = datetime.datetime.now().strftime("%Y-%m-%d %H:%M") else: date_format = date.replace("年", "-").replace("月", "-").replace("日", "") year = date_format.split("-")[0] month = date_format.split("-")[1] day = date_format.split("-")[2].split(" ")[0] time = date_format.split("-")[2].split(" ")[1] # print(month + "_" + day) if int(month) < 10: month = "0" + month if int(day) < 10: day = "0" + day # print(month + "_" + day) date_format = year + "-" + month + "-" + day + " " + time return date_format class BaiduNews(): def __init__(self,company_name): self.latest_news = [] self.company_name = company_name self.url = "http://news.baidu.com/" self.pages = 20 chrome_driver = "E:\chromedriver_win\chromedriver" chrome_options = Options() chrome_options.add_experimental_option('excludeSwitches', ['enable-automation']) chrome_options.add_argument('--window-size=1300,1000') # 设置窗口大小, 窗口大小会有影响. prefs = {"profile.managed_default_content_settings.images": 2, 'permissions.default.stylesheet': 2, 'download.prompt_for_download': True, 'safebrowsing': True} # 禁止加载图片和css chrome_options.add_experimental_option("prefs", prefs) self.browser = webdriver.Chrome(executable_path=chrome_driver, options=chrome_options) def get_page_url_list(self, company): print(">>>>>>开始爬取<<<<<<") # self.url = "https://www.baidu.com/s?ie=utf-8&medium=0&rtt=1&bsst=1&rsv_dl=news_b_pn&cl=2&wd=%E6%AC%A3%E6%97%BA%E8%BE%BE&tn=news&rsv_bp=1&rsv_sug3=2&oq=&rsv_sug1=1&rsv_sug7=100&rsv_btype=t&f=8&inputT=646&rsv_sug4=1590&x_bfe_rqs=03E80&x_bfe_tjscore=0.100000&tngroupname=organic_news&newVideo=12&pn=0" page_url_list = [] page_url_list_temp = [] # self.browser.get(self.url) # 字段 source for index in range(self.pages): # print("click") self.url = "https://www.baidu.com/s?ie=utf-8&medium=0&rtt=1&bsst=1&rsv_dl=news_b_pn&cl=2&wd="+\ company["short_name"] +\ "&tn=news&rsv_bp=1&rsv_sug3=2&oq=&rsv_sug1=1&rsv_sug7=100&rsv_btype=t&f=8&inputT=646&rsv_sug4=1590&x_bfe_rqs=03E80&x_bfe_tjscore=0.100000&tngroupname=organic_news&newVideo=12&pn=" \ + str(index*10) self.browser.get(self.url) time.sleep(random.uniform(0.5, 1.5)) # if index > self.pages -8: xml = etree.HTML(self.browser.page_source) page_url_xml = xml.xpath("//div[@class='result-op c-container xpath-log new-pmd']") for index, item in enumerate(page_url_xml): try: title = ''.join(item.xpath(".//h3[@class='news-title_1YtI1']/a/descendant::text()")) release_time = format_date(item.xpath(".//span[@class='c-color-gray2 c-font-normal']/text()")[0]) # print("title", title) if release_time < "2021-01-01 00:00": break if check_news(title, "baidu") == 0: # print("新增上市公司新闻", title) news = { "title": title, "url": item.xpath(".//h3[@class='news-title_1YtI1']/a/@href")[0], "release_time": release_time, "web_source": "baidu", "company": company["full_name"], "source":item.xpath("/html/body/div[1]/div[3]/div[1]/div[4]/div[2]/div[3]/div/div/div/div/span[1]/text()")[0] } # insertData(news) with open(f"./baidu_download_news/{self.company_name}2.jsonl", "a", encoding="utf-8") as f_o: f_o.write(json.dumps(news, ensure_ascii=False) + "\n") print(news) else: break except Exception as e: print("ERROR", e) # page = self.browser.find_elements_by_xpath("//div[@class='page-inner']/a[(text()='下一页')]") # print(page) # page[0].click() # print(page_url_list_temp) # for i in page_url_list_temp: # with open("./test.jsonl", "a+", encoding="utf-8") as f: # f.write(json.dumps(i, ensure_ascii=False) + "\n") self.browser.close() # print(page_url_list_temp) # return page_url_list_temp if __name__ == "__main__": company_name_list = [] def Baidu_spider(company_name): #开始爬取任务 BaiduNews(company_name).get_page_url_list(company_dic) f = open("42公司列表_with_id.jsonl", "r", encoding="utf-8") lines = f.readlines() for line in lines: """获取所要爬取的公司列表""" company_dic = json.loads(line) #{'short_name': '信隆健康', 'full_name': '深圳信隆健康产业发展股份有限公司', 'id': 562} company_name = company_dic["short_name"] Baidu_spider(company_name) # 爬取单条 # company_dic ={"short_name": "汇创达", "full_name": "深圳市汇创达科技股份 有限公司", "id": 2338} # Baidu_spider("汇创达")
#!\Users\Local\Programs\Python37 # -*- coding: utf-8 -*- """ 1 获取公司简称列表 2 循环爬取 3 解析-过滤 4 存储 """ from selenium import webdriver from selenium.webdriver.chrome.options import Options from lxml import etree import time import datetime import selenium import random from mysql_utils.testMysql import check_news import json from fake_useragent import UserAgent import functools # def get_company_name_list(path): # # 获取所要爬取的公司简称列表 # company_name_list = [] # with open(file=path, mode='r', encoding='utf-8') as fp: # lines_list = fp.readlines() # for line in lines_list: # line_dict = json.loads(line) # short_name = line_dict["short_name"] # company_name_list.append(short_name) # return company_name_list # # def _init(keyword,page=15): # UA = UserAgent().random # 获取随机的UA # param =f"q={keyword}&c=news&from=index&col=&range=all&source=&country=&size=10&stime=&etime=&time=&dpc=0&a=&ps=0&pf=0&page={page}" # url = f"https://search.sina.com.cn/{param}" # headers = { # 'User-Agent': UA # } # def download_news(company_name_list): # for company_name in company_name_list: # resp =_init(company_name) # 初始化 class SinaNews(): def __init__(self, company_dic): self.company_dic = company_dic self.company_name = company_dic["short_name"] self.url = "https://search.sina.com.cn/" self.pages = 20 chrome_driver = "E:\chromedriver_win\chromedriver" chrome_options = Options() chrome_options.add_experimental_option('excludeSwitches', ['enable-automation']) chrome_options.add_argument('--window-size=1300,1000') # 设置窗口大小, 窗口大小会有影响. prefs = {"profile.managed_default_content_settings.images": 2, 'permissions.default.stylesheet': 2, 'download.prompt_for_download': True, 'safebrowsing': True} # 禁止加载图片和css chrome_options.add_experimental_option("prefs", prefs) self.browser = webdriver.Chrome(executable_path=chrome_driver, options=chrome_options) def download_news(self): # print(f">>>>>>开始进行{self.company_name}----Sina新闻数据的爬取<<<<<<") print() for page in range(1, self.pages): self.url = f"https://search.sina.com.cn/?q={self.company_name}&c=news&from=home&col=&range=all&source=&country=&size=10&stime=&etime=&time=&dpc=0&a=&ps=0&pf=0&page={page}" self.browser.get(self.url) time.sleep(random.uniform(0.5, 1.5)) xml = etree.HTML(self.browser.page_source) news_div_list = xml.xpath('/html/body/div[4]/div/div[1]/div[@class="box-result clearfix"]') # print(news_div_list) for news_item in news_div_list: try: title = ''.join(news_item.xpath('.//h2/a//text()')) url = news_item.xpath('.//h2/a/@href')[0] release_time = news_item.xpath('.//h2/span/text()')[0].split(" ", 1)[1] # ['金融界', '2021-03-30 08:28:32'] source =news_item.xpath('.//h2/span/text()')[0].split(" ", 1)[0] # 进行 时间日期&&新闻标题 的过滤 if release_time < "2021-01-01 00:00": break if self.company_name not in title: break news = { "title": title, "url": url, "release_time": release_time, "web_source": "sina", "source":source, "company": self.company_dic["full_name"] } with open(f"./sina_download_news/{self.company_name}.jsonl", "a", encoding="utf-8") as fp: fp.write(json.dumps(news, ensure_ascii=False) + "\n") except Exception as e: print(self.company_name, "RERROR", e) self.browser.close() def progress(percent): # 打印进度条 if percent > 1: percent = 1 res = int(50 * percent) * '#' # print('\r>>>>>>开始进行--%s--Sina新闻数据的爬取 正在进行中。。。 总进度达到:[%-50s] %d%%' % (company_dic["short_name"],res, int(100 * percent)), end='') print('\r\033[0;30;41m\t>>>>>>正在进行--%s--Sina新闻数据的爬取 爬取成功后总进度可达到:[%-50s] %d%% \033[0m' % (company_dic["short_name"],res, int(100 * percent)), end='') def wrapper_process(func): # 添加进度条的功能 @functools.wraps(func) def inner(*args, **kwargs): complete_line = count percent = complete_line / total_lines progress(percent) progress(percent) func(*args, **kwargs) return return inner @wrapper_process def Sina_spider(company_dic): # 开始爬取任务 SinaNews(company_dic).download_news() def start_spider(): print("开始爬取公司,请等待......") f = open("42公司列表_with_id.jsonl", "r", encoding="utf-8") lines = f.readlines() global count global total_lines count = 0 total_lines=len(lines) for line in lines: """获取所要爬取的公司列表""" global company_dic company_dic = json.loads(line) # {'short_name': '信隆健康', 'full_name': '深圳信隆健康产业发展股份有限公司', 'id': 562} count += 1 Sina_spider(company_dic) if __name__ == '__main__': start_spider() print("搞定!!!!!!!!!!") # 测试 # company_dic = {'short_name': '信隆健康', 'full_name': '深圳信隆健康产业发展股份有限公司', 'id': 562} # # SinaNews(company_dic).download_news()
import json from html.parser import HTMLParser import re ''' 保留 </p><br><br/> h1 h2 h3 h4 h5 h6 ol ul li dl dt dd p div hr center pre br table form ''' tag_list = ["h1","h2","h3","h3","h4","h5","h6","ol","ul","li","dl","dt","dd","p","div","hr","center","pre","br","table","from"] str_Arr = "" class MyHTMLParser(HTMLParser): def pre_handle(self, content): global str_Arr styleTagAndText = re.findall("(<style.*?>.*?</style>)", content) scriptTagAndText = re.findall("(<script.*?>.*?</script>)", content) # print(styleTagAndText) for i in styleTagAndText: content = content.replace(i,"",1) for i in scriptTagAndText: content = content.replace(i,"",1) return content def handle_starttag(self, tag, attrs): global str_Arr # print("Encountered a start tag:", tag) # if tag in tag_list: # str_Arr += "<p>" def handle_data(self, data): global str_Arr # print("Encountered some data :", data) # if '&' not in data and 'sp' not in data and data != ' ' and data != '': if data != '': # 不占位置的空格 str_Arr += data.strip() def handle_endtag(self, tag): global str_Arr # print("Encountered an end tag :", tag) if tag in tag_list: str_Arr += "<br>" def get_str(self): global str_Arr # styleTagAndText = re.findall("(<style.*?>.*?</style>)", str_Arr) # scriptTagAndText = re.findall("(<script.*?>.*?</script>)", str_Arr) # for i in styleTagAndText: # str_Arr = str_Arr.replace(i,"",1) # for i in scriptTagAndText: # str_Arr = str_Arr.replace(i,"",1) str_temp = str_Arr.replace("\n", "").replace("\t", "").replace("\"","“").replace(" ", "").replace("<br><br><br><br><br><br>", "<br><br>").replace("<br><br><br><br><br>", "<br><br>").replace("<br><br><br><br>", "<br><br>").replace("<br><br><br>", "<br><br>") str_Arr = "" return str_temp # s = "<p>sssssss</p><style>xxxxxxxxx</style><p>sssssss</p></p><style>aaaaaaaaaa</style>" # c = re.findall("(<style>.*?</style>)", s) # # c = s.replace("<p>", "ppp", 1) # print(c)
content_list = xml.xpath("//div[@id='the_content']")[0] content = etree.tostring(content_list, encoding="utf-8").decode('utf-8') parser = MyHTMLParser() parser.feed(parser.pre_handle(content))
content = parser.get_str()
作后格式文章段落以<br>分割
# pip install js2py import js2py import requests # 创建js执行环境 context = js2py.EvalJs() # 加载js文件 headers = { 'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36", "Cookie": "OUTFOX_SEARCH_USER_ID=1048814593@10.169.0.84; JSESSIONID=aaaVVVocreU2nc3E4MrPx; OUTFOX_SEARCH_USER_ID_NCOO=1427677174.0338545; fanyi-ad-id=112781; fanyi-ad-closed=1; ___rl__test__cookies=1624867925192", } fan_js_url = "https://passport.baidu.com/passApi/js/wrapper.js?cdnversion=1624878946930&_=1624878946517" fan_js = requests.get(fan_js_url, headers=headers).content.decode() context.execute(fan_js) context.n = {"class": "python"} print(context.n, type(context.n))
