
Java问题
Java相关
基础
Java Collections
Map(都可以插入Null)
HashMap
数据结构:底层采用数组➕链表➕红黑树的结构,通过散列映射存储键值对
扩容情况: 默认的threshold为0.75,如果存储元素的个数大于75%的阈值,那么会触发扩容操作。
- 创建一个原来数组两倍的新数组
- 1.7采用Entry的重新hash运算,1.8采用高于运算
put详情:
查看数组是否为空,是的话初始化数组,不是的话直接通过hash值和索引数组长度进行索引确定,查看当前数组中这个节点是否为null,为null,直接插入,不是的话,查看key是否equals,是的话直接重新赋值,不是的话,看是tree or list,list直接插入,插入完之后查看是否为个数大于8个且数组长度大于64个,大于的话树化为treeNode,如果是红黑树的话,直接进行插入。之后再查看是否大于threshold,大于的话直接进行resize,扩大为原来的两倍。
在hashmap的rehash中,如果是链表的话,会将链表分为两个链表,在分别放入新的数组中,如果是红黑树的话,就分成两个字数放入新的数组中。
hashMap的长度为什么要一直是2^N
因为要进行hash运算,需要位运算,找到2^N的余数,这样会更快一点
ConcurrentHashMap
通过设置Synchronized和cas操作并发稳定。
TreeMap
红黑树实现,能够比较大小,不允许nullkey,但是允许null值
Set
HashSet
底层就是hashmap,允许插入null
TreeSet
红黑树实现,不允许null
Queue
PriorityQueue
使用小堆实现的
List
ArrayList
底层基于数组实现随机查找和便利,但是插入删除较慢。初始为10,之后扩容会扩容到1.5倍。
LinkedList:
基于双向链表实现的,能够提供快速的顺序访问和插入删除。但是对于随机查找来说就很慢。
Same:两个都是线程不安全的。
CopyOnWriteList
线程安全,保证了线程的安全性。在写的时候进行加锁,读的操作不许要加锁。采用一种写时复制的方法保证现成安全。
fast-fail and fast-safe
fail-fast保证在多并发的时候,便利集合能够快速失败,通过查看modCount属性来查看是否能够快速失败。
fail-safe:是先通过复制集合的元素,再在复制的集合上进行便利,之后的写的无法看见。
HashMap的原理以及扩容机制
hashmap是数组加链表或者红黑树实现的。当两个K-V具有相同的hash值的时候,会用链表挂载上一个节点上。当节点超过8个之后会,将list变为红黑树。
为什么是8个?
在八个的时候,list的查询效率就小于红黑树了。从树到list是6个的限制。log(n) n
扩容机制
会在容量达到一定阈值之后,会进行扩容。一般是扩容为两倍,对所有的k-v进行重新hash并且放入新的数组中。如果是单个节点直接放入,如果不是单个节点,是list,会分为两个list,一个是hash值和之前oldCapacity与之后为1的list,另一个就不是了,将这两个重新放入新的数组中。如果是红黑树,会将调用Split方法,对红黑树进行分裂。
ArrayList和LinkedList的区别
arraylist底层是数组,linkedList底层是双向链表。linkedlist根据索引访问会比较慢,只能从头或者尾开始查找。arraylist会动态扩容,一般会扩容到1.5倍。arraylist插入和删除比较慢,因为是数组,需要对之后的元素进行复制或移动。
JVM的内存区域
JVM基础入门
堆、方法区、虚拟机栈、本地方栈、程序计数器、常量池(在方法区中)、元空间(类型信息),直接内存。堆和方法区共享的,其他是线程私有的,字符串常量池在堆上。
堆就是新建对象就在堆中分配内存,垃圾回收也主要在这个地方。方法区存放类型信息、静态变量、常量等信息。
对象创建过程

对象有限分配在Eden区,当Eden区没有足够空间分配之后,会执行Minor GC,回收对象。存活下来的对象回到Survivor的from区,放不下会存到old区。
大对象直接分配在old区,防止eden和survivor之间发生大量的内存拷贝。新生代采取复制算法。
长期存活的放入老年代,每个对象有一个Age Count,大于默认值15会进入old,
并且会有动态年龄判定,大于幸存区的一半,将当前对象的age作为新的阈值
每次Minor GC或者大对象直接进入老年区时,JVM会计算所需要的空间,不够的话,会进行Full GC。
- 类型检查:查看这个类有没有被加载,没有的话,会执行类加载过程。
- 分配内存:为对象分配内存
- 初始化零值:会将所有的值复制为0值,保证没有初始化也可以使用
- 设置对象头:
- 执行init方法:初始化阶段
JVM垃圾回收
-
引用计数:没有个地方使用以后用计数,就当引用时加1,引用失效时,减1.
-
可达性分析:通过一系列的GC Roots作为起始点,从这些七点开始向下搜索,不可达的需要收集。
-
标记清理算法(CMS):会造成内存碎片化
-
标记整理算法(Old):时间较长,
-
标记复制算法(Young):会浪费空间
-
分代收集:分为老年代、新生代。
JVM调优
MinorGC 在年轻代空间不足的时候发生,
MajorGC 指的是老年代的 GC,出现 MajorGC 一般经常伴有 MinorGC。
FullGC 1、当老年代无法再分配内存的时候;2、元空间不足的时候;3、显示调用 System.gc 的时候。另外,像 CMS 一类的垃圾回收器,在 MinorGC 出现 promotion failure 的时候也会发生 FullGC。
要查看GC日志,通过JVM添加+printGCDetails查看GC日志。
jps:查看java进程和相关信息。
jinfo:查看JVM参数。
jstat:查看JVM运行状态,内存状态垃圾回收等
jstack:查看现成出现卡顿的原因
jmap:dump内存快照,查看是为什么会有内存问题。
Minor GC主要是Eden区空间不足,可以通过增加Minor GC的方法进行优化。Major GC表示一直在进行老年代的GC,通过GC查看是哪里的问题。主要的可能是,可能是因为进入老年代的阈值动态调整的过小,可以调整升代限制。
Full Gc是因为老年代空间不足,或者meta空间无法新的类型。查看Gc日志,然后分析,空间不足,看能不能增加空间。优化代码,减少大对象的创建。
垃圾回收器
-
JDK3 Serial Parnew 单线程收集,会直接STW Parnew 多线程版本
-
JDK5 Parallel Scavenge
-
JDK8 CMS(OLD) 四个阶段 初始标记->并发标记->最终标记->标记清理(会有大量的内存碎片)
-
JDK9 G1 表示整理。垃圾回收期。将整个内存区域划分为多个相同大小的区域,在其中分为Eden,Survive,Old(大对象直接放入老年代中)。然后回在垃圾回收的根据预期的停顿时间执行垃圾回收。初始->并发->最终->复制
-
JDK11 ZGC 将内存区域分为不同大小的区域,类似与G1,但是能够做到更好的并发,初始标记->并发标记->在标记->并发转移准备->初始转移->并发转移。使用了三色技术。在每个指针的前面三位上实现了染色指针,表明这个引用有没有被标记。
JMM
主要包括了主内存和本地内存。主内存是共享的,本地内存是私有的。
Java内存模型
原子性:表示针对32为的类型读和写具有原子性
可见性:通过volatile关键字进行可见性的保证
有序性:happen-before原则保证。
线程池的七个参数,工作过程以及提供的四个已有线程池
core_size : 核心线程数量
max_size : 表示最大线程数量
abort_strategy: 当无法再接受任务之后应该怎么办
time : 非活跃时间,达到这个时间之后会销毁线程(非核心线程)
time_uint : 时间的单位
thread_factory: 创建线程工厂,主要是设置线程的名字
workQueue : 阻塞队列,当core现成无法放入新的任务是,任务会放入队列中。
任务流程:
1、送入submit的Runnale或者Callable会变为FutureTask()
2、都会执行execute送入线程池中。
3、如果核心线数没有满,那么添加到core thread中,如果满了,就添加到queue中,如果queue中不接受了,那么就添加到非Core thread中,之后,总的size满了,就直接调用拒绝策略进行拒绝。
现成池状态:
NEW -> SHUTDOWN -> STOP -> TIDING -> TERMINTED
最开始时new, 表示可以接受任务并且处理任务,然后是SHUTDOWN,表示不再接受任务,但是会执行任务,STOP直接不允许执行任务(通过终端线程进行取消),也不接受任务。TIDING表示所有任务已经完成,所有的工作线程已经终结,之后调用TERMINTED方法,会变到TERMINTED状态。
回收线程:
通过processWorkerExit进行实现,将线程直接退出。
线程池核心参数设置的技巧
Integer缓冲机制
对于已经一定范围内的Integer,会复用之前的对象。在Integer中有一个缓冲池,里面有-127~128,如果需要,直接返回这个池中的对象
synchronized 、AQS 、volatile
Synchronized表示是mutex lock,当Synchronized锁方法体的时候,是以当前的对象为锁,锁方法的时候,也是以对象为锁,也可以直接将对象做为锁,锁静态方法或者方法体的时候,锁的是当前类的class对象。Synchronized表示的是锁,通过monitor实现的,在方法的开始会有monitorenter,之后退出会有monitorexit,Synchronized具有可重入锁的功能,但是无法设置时间。Synchronized有三种等级的锁,一种是偏向锁,一种是轻量锁,一种是重量级锁,这三种锁只能升级,无法降级。偏向锁是在对象的mask word上存储获得锁的线程id,最开始,尝试竞争锁,会使用cas设置,成功表示获得了锁,或者查看当前锁存储的线程id和当前的线程id是否相同,相同可以重入。有其他锁进行偏向锁会导致锁的升级。会先释放掉锁,然后升级为轻量级锁,会在每个线程的栈帧主生成一个displaced mask word区域,会保存对象的mask word区域,并将对象的mask word区域改编为指向displaced mask word的一个指针。当通过cas设置成功之后,就表示获得锁成功了。之后释放锁,就是将对象的mask word替换会原始的,如果成功,表示释放锁成功吗,如果失败,表示需要锁升级,就升级为重量锁,有操作系统进行调度。
AQS:abscrtactqueuesychronied 主要通过一个volatile int state和cas操作实现线程之间的同步。可以实现shared和exelcusive两种模式的资源共享。一个是互斥,一个是共享。当没有获得锁的线程,会生成一个node,放入其中的sycn queue中去,这是一个variable CLH queue,是一个双向队列,通过查看每个节点的前一个节点查看是否已经获取到锁,来判断,他是否能够获得锁,能够获取到相对应的锁。
volatile:可见性关键字,用来保证某个线程更新某个值之后,所有的之后的其他线程都能够看到更新。主要是将本地内存直接刷新回到主内存中。
CurrentHashMap的原理
currentHashMap是一个线程安全的HashMap,整体的构成和hashmap类似,但实际在放入元素的时候,会对node中的节点进行加锁,如果为null,那么直接cas放入,不为空,就要锁住第一个顶点,然后往里面添加,类似于hashmap,查过8个会进行树化。并且,因为是多线程,rehash的过程会有多个线程参加,所以每个线程负责一定区域的rehash。
动态代理
深入浅出代理模式和事务管理
JVM动态代理: 可以通过jvm自带的动态代理实现。通过或Proxy.newInstance()送入classloader和InvocationHander和接口class,实现动态代理,可以在InvoicationHander中实现要代理的功能。这个只能代理接口,不能代理类,因为他要继承一个proxy类。
GLIBC : 可以通过可以直接修改类,但是无法修改final方法。
Spring主要通过Java原生自带和GLIBC实现。
Spring 事务管理
Spring的事务管理是依据动态代理模式实现的,
注解型
@Transactional(rollbackFor = Exception.class, value = "事务管理器", propagation = "事务的传播行为", isolation = "隔离级别", readOnly = "读写或者只读事务")
Propagation.REQUIRED:如果存在事务,则加入事务,不存在,则新建事务。
Propagation.SUPPORTS:如果存在,则加入,不存在,不以事务的方式进行。
Propagation.MANDATORY:存在事务,加入事务,不存在,抛出异常
Propagation.REQUIRED_NEW:重新建一个新的事务,存在事务,则暂停事务,重新新的事务。
Propagation.NOT_SUPPORTED:非事务
Propagation.NEVER:以非事务进行,存在事务,抛出异常
Propagation.NESTED:和REUQIRED一样
Spring事务管理失效
- 同一个类内一个非事务方法调用事务方法,即使事务出现异常,也不会回滚。因为是采用动态代理的部分,如果调用了这个方法并不会产生代理类。
- 不是public方法,会失败
- try-catch了异常,会导致事务失效
中间件相关
Mysql的ACID原则
A:atomicity:原子性 表示事务不可分割
C:consistency:一致性:事务前后一定都是一致性状态
I:isolation:独立性:每一个事务的执行不会互相干扰,各自独立执行
D:durability:持久性:会永久的存到磁盘上,即使是服务重启或者其他原因
Mysql聚簇索引和非聚簇索引(覆盖索引)
聚簇索引是通过主键建立的索引,通过B+树实现索引,每一个B+树的叶子节点上都有对应的记录,如果没有主键,那么就通过第一个唯一键进行建立,两个都没有通过innodb的引擎自己隐藏的主键建立。每一个表中都有聚簇索引。其他的索引统称为非聚簇索引,非聚簇索引的每个叶子节点上包含的是主键的值,也就是对应了在聚簇索引上的值。如果在SELECT查询语句中,查询条件的索引能够覆盖了要输出的东西,那么就无需进行主键索引的查询,也就无需进行回表。
SELECT name, age FROM students WHERE name = 'k%' and age = 20
在这条语句中,如果students表中有联合索引key(name, age)那么就无需进行回表进行得到结果。
SELECT id, name, age FROM students WHERE name = 'k%' and age = 20
这个也不需要,因为这种非狙索索引包含了主键的值。
SELECT id, name, age, gender FROM students WHERE name = 'k%' and age = 20
需要回表,gender在聚集索引中存储着。
无需回表叫做覆盖索引,能够进行索引的优化,减少回表的操作,也就是io的操作。
索引下推(Index Conditin Pushdown, ICP)
索引下推
主要思想是将查询中的where条件应用到扫描中,如果建立了联合索引的话。
B+树的特点,与B树、红黑树的区别
B+树平衡n叉树,只有在叶子结点才有真正的记录,每一个非叶子结点主要是都有只想下一层的指针,每一个节点的磁盘大小是相同。叶子节点之间通过了指针进行和连接,所以b+树可以随机访问也可以顺序访问。这种树作为索引主要是减少了磁盘IO的次数。相对于B树来说,B树每个节点都存储了对应的值,和只想下个节点的指针,并且,叶子结点之间没有连接起来。红黑树是一种弱平衡二叉树,相对于B+树来说,如果作为索引的话,因为每个节点只有两个子节点,所以访问磁盘io的次数会很多,导致整体查询较慢。
MVCC原理
Innodb在每一行的记录上还会有三个隐藏的值,一个是隐藏主键,一个是创建/最后一次修改的事务id,一个是上一条记录的undo日志的指针。然后每一条undo日志和这个类似。当在进行SELECT的时候,会保存一个当前的view list,里面有正在进行的事务id,通过和当前正在执行的事务的id进行比较,根据当前的Isolation使用当前读还是快照读。首先查看当前的事务id是否小于view list中最小的事务id,如果小于,那么就可以读当前这条记录(小于当前活跃的事务id,所以可以随便读,因为只在read view生成之前commit,可以RC)。根据当前事务的id查看view list的最小值是否大于引擎将要生成的事务id,如果是,那么就无法读,因为这是在生成read view之后的commit,无法读,直接读上一条记录,还不行查看是否在这个list中,如果在,表示还未提交,无法读,不在,表示可以读。
RR和RC主要是读的快照读还是当前读
索引的原理
索引是通过建立B+树建立的,B+树的索引会根据建立索引的顺序建立,也就是会满足最左匹配原子,如果where子句中左侧没有索引,那么就不会进行索引使用。
事务的隔离级别
None, read_commit, read_repeatable, serialize。
read_commit保证了只允许读取别人已经提交了的,无法防止不可重复读,和第二类并发更新丢失。
read_repeatable表示了可重复读,可以解决第二类并发更新,但是无法解决幻读的问题。
serialize表示完全的穿行话,可以防止任任何。
索引失效的场景
没有满足最左匹配,用了not in ,<>或者范围查询。
左连接和右连接的区别
慢查询优化
md
MySQL的锁
DML, DDL: DML databse manipulation language DDL databse definition language
锁的分类
- 全局锁:
- 在DB级别对整个数据库的实例进行加锁。是的数据库处于只读状态阻塞对数据库的增删改以及DDL语句。
- 加锁方式: Lock Flush Tables Withs Read Lock; Unlock Tables;
- 表锁:(意向锁为表锁)
- 对操作的整张表进行加锁,加锁开销小,不会出现死锁,并发读较低。分为表共享锁,表排他
- 加锁方式:Lock Tables {tb_name} Read/Write , Unlock Table
- 行锁:
- 锁的颗粒度较小,并发读较高,加锁开销大,并发读低。Innodb主要锁住的是索引项。
- 加锁方式: 1) Select ... (不加锁) 2) Insert、Update、Delete。 3) Select ... Lock In SHARED MODE 4) SELECT ... FOR UPDATE
- 提交(commit)/回滚(rollback)
在申请行锁(例如读锁、写锁)的时候,会先添加意向锁。
Redis的五种数据结构
sds, list, set, zset, hash
sds使用char*表示不同的结果,里面会有值来表示这个字符有多少个。最后还是以一个'\0'设置的,这样的话, 就能够保证这个字符串是二进制安全的。并且,不会发生溢出。
list:表示一个链表,是一个双向链表
set:底层使用intset和hashset实现的,也就是hash值
zset:底层是同过skiplist或者ziplist实现的
skiplist是跳表,每个节点保存可只想后面多个的指针,整个跳表有一个整个跳表的level,还有就是整个看了能够快速的查找并且实现,还有一个之前前一个节点的指针。skiplist可以进行范围性查找。
hash: hash是由两个字典形成的,第一个字典用来存储值,第二个字典用来进行rehash。这个rehash是一个渐进式rehash的过程,当用到某个元素的时候,才会对这个元素进行rehash。
判断dict是否正在rehashing,只有是,才能继续往下进行,否则已经结束哈希过程,直接返回。
接着是分n步进行的渐进式哈希主体部分(n由函数参数传入),在while的条件里面加入对.used旧表中剩余元素数目的观察,增加安全性。
一个runtime的断言保证一下渐进式哈希的索引没有越界。
接下来一个小while是为了跳过空桶,同时更新剩余可以访问的空桶数,empty_visits这个变量的作用之前已经说过了。
现在我们来到了当前的bucket,在下一个while(de)中把其中的所有元素都迁移到ht[1]中,索引值是辅助了哈希表的大小掩码计算出来的,可以保证不会越界。同时更新了两张表的当前元素数目。
每一步rehash结束,都要增加索引值,并且把旧表中已经迁移完毕的bucket置为空指针。
最后判断一下旧表是否全部迁移完毕,若是,则回收空间,重置旧表,重置渐进式哈希的索引,否则用返回值告诉调用方,dict内仍然有数据未迁移。
缓存穿透、缓存击穿、缓存雪崩
缓存雪崩:统一时间大量的key失效,直接打到了服务器。可以设置不同的过期时间。
缓存穿透:不存在的值,一直查询。可以通过布隆过滤器设置,看看存不存在,不存在直接不查。或者在缓存中设置值,查不到直接返回null
缓存击穿:热点数据失效,攻击数据库。设置热点数据永不过时。设置互斥锁,一个查询结束之后,在混存中存储下来。
Redis实现分布式锁的原理
通过或SETNX实现分布式锁,设置成功表示获得,并且要设置过期时间。对应多态服务器的话,就要获得多态redis锁的,在可以执行步骤。一定要在完成之后释放锁,并且一定要设置锁。
使用缓存的方式
使用缓存的类型
缓存设计
cache-aside Read-Through Write-through, Write-Behind
-
Cache-Aside:
- 读:如果缓存中存在,那么就从缓存汇总读取,不过不存在,那就从数据库读取,在更新到缓存中。
- 更新:如果缓存汇总也有数据的话,会导致不一致
- 缓存失效:需要将缓存中的值进行删除,下次查询的时候重新从数据库中进行查询
- 缓存更新:或者可以通过在更新数据库的时候也更新缓存
-
Read-Through
- 读取数据会从缓存中读取,但是,如果缓存中没有,那就去读取数据库.这部分交给了缓存去处理。
-
Write-Through
- 所有的写会同时写缓存和数据库,保证两个操作都在一个事务中完成。保证了事务的一致性。如果没有命中缓存,就更新数据库,如果命中了缓存,就要要两个一起更新。
-
Write-Behind
- 不会同时写入缓存和数据库,而是异步的写入数据库。会导致数据的不一致性。
如何保证Redis与MySQL的数据一致性
主要存在的是写的问题腾讯缓存一致性问题
更新数据库后更新缓存
在写写并发中,更新数据库和更新缓存的执行顺序可能不同,导致了脏数据。
更新数据库前更新缓存
不应该使用,很有可能会导致数据库更新失败,导致错误数据。这个不应该使用。
更新数据库后删除缓存
在写读并发中,更新数据库后,还没有删除缓存,会导致脏数据。可以使用延迟双删策略进行处理。
更新数据库前删除缓存
会导致读写并发出现问题,可能写,删除缓存,还没有更新到数据库,一个读请求,读到了脏数据,导致了问题。可以使用延迟双删的策略进行处理。主要是延迟的策略问题。
| 策略 | 并发场景 | 潜在问题 | 解决方法 |
|---|---|---|---|
| 更新数据库,更新缓存 | 读,写 | 会导致读可能读到脏数据 | 忽略 |
| 写,写 | 可能导致缓存中的数据与数据库中的数据不一致,有可能数据库是a->b,缓存是b->a | ||
| 更新缓存,更新数据库 | 没有并发 | 如果更新数据库失败,会导致错误数据 | 使用MQ确保更新数据库成功 |
| 写写 | 可能导致更新缓存为a->b,数据库为b->a | 分布式锁 | |
| 删除缓存值,更新数据库 | 写读 | 先删除了,但是没有写,此时读会是脏数据 | 延迟双删 |
| 更新数据库,删除缓存 | 写+读(缓存命中了) | 会导致A更新了数据库,但没来的及删除缓存,导致了b读取了脏数据 | 忽略 |
| 写+读(缓存未命中) | 会导致读不从数据库中查询,但是此时,写已经删除过缓存了,这时候读将旧的值放入缓存中,导致出现错误数据,可能会导致不一致 | 分布式锁 |
- 针对大部分读多写少场景,建议选择更新数据库后删除缓存的策略。
- 针对读写相当或者写多读少的场景,建议选择更新数据库后更新缓存的策略。
最终一致性:
设置缓存过期时间
采用MQ保存和推送更新redis key的信息
订阅mysql的binlog,达到mysql的效果
Redis的持久化
RDB和AOF。RDB是通过快照方式进行存储。AOF是存储每一条命令。RDB快,但可能有数据丢失。AOF慢,但准确点。
Redis的分片集群
Redis的高可用,主要通过主从复制机制以及Sentinel集群来实现。
主从复制 分为两个阶段,首先,当从服务器发起SYNC命令后,主服务器会生成最新的RDB文件发送给从服务器,并使用一个缓冲区来记录从此刻开始主服务器执行的所有写命令;待RDB文件传输完之后,再将该缓冲区的数据再发送给从服务器,这样就完成了复制。旧的Redis版本有个缺陷是,如果在第二个阶段发生失败,需要从第一个阶段重新开始同步,而这个阶段的操作会消耗大量的CPU、内存和磁盘I/O以及网络带宽资源,太过耗费资源。所以从2.8版本开始,实现了部分重同步,通过主从服务器各维护一个复制偏移量来实现。
Sentinel 由一个或多个Sentinel实例组成的哨兵系统,可以监视任意多个主从服务器,并完成Failover的操作。Sentinal其实是一个运行在特殊模式下的Redis服务器,运行期间,会与各服务器建立网络连接,以检测服务器的状态;同时会与其它Sentinel服务器创建连接,完成信息交换,比如发现某个主服务器心跳异常时,会互相询问心跳结果,当超过一定数量时即可判定为客观下线;一旦主服务器被判定为客观下线状态,那么Sentinel集群会通过raft协议选举,选出一个Leader来执行Failover。
Failover 一般来说,会先选出优先级最高的从服务器,然后再从中选出复制偏移量最大的实例,作为新的主服务器;最后将其它从和旧的主都切换为新主的从。
当从服务器有2个或者多个时,Redis的主从架构可以有两种形式。一种是,所有的从服务器直接挂在主服务器上,这种模式的优点是,所有从服务器复制的延迟相对较低,而缺点在于加大了主服务器的复制压力;另一种形式,是采用级联的方式,S1从M复制,S2从S1复制,以此类推,这种模式的优点是,将主服务器的复制压力分摊到多个服务器上,而缺点在于越处于级联下游的从实例,复制延迟就越大。
从主从复制模式可以看出,Redis的数据只能保证最终一致,不能保证强一致性
Redis的大key和热key
Big Key:将key拆分
Hot Key:进行多个备份,限流,或者使用旧的数据。
Redis限流
流量控制效果:漏桶限流 > 令牌桶限流 > 滑动窗口限流 > 计数器限流;
资源隔离限流会将对应的资源按照指定的类型进行隔离,比如线程池和信号量。
计数器限流,例如5秒内技术1000请求,超数后限流,未超数重新计数;(SETNX实现)
滑动窗口限流,解决计数器不够精确的问题,把一个窗口拆分多滚动窗口;(通过ZSET实现,socre表示为时间戳,可以实现范围之内有多少个请求)
令牌桶限流,类似景区售票,售票的速度是固定的,拿到令牌才能去处理请求;(list pop push)
漏桶限流,生产者消费者模型,实现了恒定速度处理请求,能够绝对防止突发流量;(Lua脚本实现)
唯一id设置
最常见的几种区分方式通常有如下几类:
- 全随机(可读性差,文字组合其实也可以当成一种全随机的特殊情况)
例如UUID(结构示例如下:6B29FC40-CA47-1067-B31D-00DD010662DA)
该方式经常用于小范围数据区分
该方式通常不会单独使用,一般会结合树形结构来实现一些目录区分 - 顺序递增的数值结构
该方式形式简单,索引方便
例如:数据库的自增主键、计算机内存的物理地址、Excel表的序号 - 树形结构区分
组织方式方便直观,便于索引
例如:文件目录结构、关系型数据库数据组织方式、编程语言的多层结构体 - 分布式ID生成方式
例如雪花算法,该算法的分段标记其实有点树形结构的结合,但其增长方式又有数值的使用便利 - 其他:以上方式的结合
很多其他的唯一性区分通常都表现成以上方式的结合
例如:URL
URL的域名以及Path,本身就存在树形结构的引子(虽然其本身指向的资源存储不一定是该方式);
Path中的每一小段,都是区分性命名,世界范围内看,都是随机和不确定的。
如何保证幂等
每次请求设置唯一标识,在API借口上设置每一标识,保证在业务上的唯一性。
写入性数据的幂等
通过增加一个unique key,可能有各种组成,如果UserId, 操作类型,biz_id组成。当unique key冲突的时候,查询关键信息那里出现冲突,直接返回这个问题。
更新型幂等
可以使用状态机设定。或者增加幂等表
删除型幂等
进行逻辑删除,而不是物理删除
分布式CAP原则
A:availability:可用性:服务一直可用,而且是正常响应时间。
C:Consistency:一致性:表示数据的一致性
P:Partition Tolerance:分区容错性:分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务。
MQ模式
- 点对点模式,不可重复消费
多个生产者可以向同一个消息队列发送消息,一个消息在被一个消息者消费成功后,这条消息会被移除,其他消费者无法处理该消息。如果消费者处理一个消息失败了,那么这条消息会重新被消费 - 发布/订阅模式
发布订阅模式需要进行注册、订阅,根据注册消费对应的消息。多个生产者可以将消息写到同一个 Topic 中,多种消息可以被同一个消费者消费。一个生产者生产的消息,同样也可以被多个消费者消费,只要他们进行过消息订阅
MQ应用场景
异步通信:可以用于业务系统内部的异步通信,也可以用于分布式系统信息交互。
系统解耦:将不同性质的业务进行隔离切分,提升性能,主附流程分层,按照重要性进行隔离,减少异常影响。
流量削峰:间歇性突刺流量分散处理,减少系统压力,提升系统可用性。
分布式事务一致性:RocketMQ提供的事务消息功能可以处理分布式事务一致性(如电商订单场景)。当然,也可以使用分布式事务中间件。
消息顺序收发:这是最基础的功能,先进先出,消息队列必备。
延时消息:延迟触发的业务场景,如下单后延迟取消未支付订单等。
大数据处理:日志处理,kafka。
分布式缓存同步:消费MySQLbinlog日志进行缓存同步,或者业务变动直接推送到MQ消费。
如何保证消息的顺序性
MQ如何保证消息有序
Rabbit:在单一的broker上使用队列进行存储,保证了顺序性。即使是多个副本,其他副本只是进行复制,无需进行担心。但在高并发的时候,无法保证多个消费者消费信息的一致性。
kafka:没有队列的概念。信息的收发依赖于topic。kafka不保证不同partition中顺序的一致性。所以,需要保证顺序性的话,需要想同一个partition中发送消息。
RocketMQ:只保证了RocketMQ中单独队列的一致性。
MQ如何消息不丢失
-
生产者发送信息不丢失
通过消息发送确认机制(ACK),对于客户端来说,发送消息要接收到ACK信号。 -
消息中间件消息不丢失
每个不同的中间件实现不同-
Rabbit MQ
- 消息发送开启confirm模式,所有消息是否发送成功都会返回给proudcer
- 开始消息队列的持久化
- RabbitMQ通过镜像队列保证消息队列的高可用,只有Master对外提供服务,当Master待机之后,会从Slave中重新选出Master。
- Master的消息的更新会同步到其他Salve中
-
RocketMQ:
- 三种方式发送消息 1)同步(Sync) 2)异步(Async) 3)单向
- 进行同步刷盘机制
- 具体的RocketMQ内部设计的HA机制是主从同步机制,消息发送到Topic下并具体消息队列的Master Broker中后,会将消息同步到Slave。只有Master Broker才可以接收生产者发送的消息。而消费者,可以从Master也可以从Slave拉取并消费消息。
-
Kafka:
- 分区副本方式的设计保证消息的高可用,在创建topic的时候都可以设置分区副本的数量;
- 生产者可以选择接收不同类型的确认(ACK),比如在消息被完全提交时候(写入所有同步副本)的确认,或者在消息被写入首领副本时的确认,或者在消息被发送到网络时确认;
- Kafka的消息,写入分区的时候仅仅是保存在某几个分区副本文件系统内存中,并不是直接刷到磁盘了,因此宕机时候,单个副本仍然可能丢失数据。Kafka不能保证单个分区副本的数据一定不丢失,而是靠分区副本机制来确保消息的完善性(分布到不同的broker上)。
-
-
消费消息不丢失
消息消费时候,也要开启相应的ACK机制,消息消费成功即ACK(对于Kafka就是更新消费的offset);
对于RocketMQ这种有消息重新消费设计的,需要设置最大消费次数,尝试失败的消息重复消费。
MQ如何保证高性能
在磁盘上进行顺序存储
使用PaheCache缓存
消息堆积的解决方法
Kafka对于topic下的数据,有容量上限、时间上限两种消息存储上限规则,触发其中任何一个规则,都会删除淘汰之前的消息。这个尤其需要注意。
RocketMQ,消息在服务器存储时间也有上限,达到上限的消息将会被删除。也需要做相应的考量。
受持久化磁盘容量的影响,存储积压的数据不能超过磁盘的上限。
如果业务消费有异常,需要给足充足的冗余量,避免因为消费不及时而丢失数据。
如何避免消费重复消息
使用唯一标识来标记这个消息是否被消费过了。
计算机基础
进程的组成
进程由数据段、程序段和PCB组成。PCB是进程存在的唯一标识。
线程和进程的区别
进程是操作系统分配资源的基本单位,线程的小进程,是CPU执行的最小单位。每个进程有自己的虚拟地址,自己的内存空间,自己的上下文。而线程在进程中,标识了独立的自己的内存空间,各个线程之间也有共享空间。线程的切换比进程的切换要高效。
线程/进程通信方式
通过管道、消息队列、共享内存、socket套接字、信号等。
线程之间可以通过共享内存。
线程比进程高效的原理
BIO/NIO/AIO
- 同步/异步
- 阻塞/非阻塞
同步I/O和异步I/O的区别:是否需要进程自己再调用I/O读写函数。同步需要,异步不需要。
发起I/O请求的线程不等I/O操作完成,就继续执行随后的代码,I/O结果用其他方式通知发起I/O请求的程序。wiki
在阻塞I/O下,只要I/O不可用,会直接将线程挂起,无法充分利用多线程的优势。
在非阻塞IO模式下,读写操作都是立即返回,此时当前进程并不会被挂起,这样就可以充分的使用CPU,非阻塞I/O通常会和多路I/O复用配合着一起使用,从而实现多个客户端请求的并发处理。
多路I/O复用实现了多个客户端连接的同时监听,大大提升了程序感知客户端连接可读写状态变化的效率。在Linux下多路I/O复用的系统调用为select、poll、epoll。
通过注册SIGIO信号的处理函数,实现了一个I/O就绪的通知机制,在SIGIO信号的处理函数再进行读写操作,从而避免了低效的I/O是否就绪的轮询操作。
前面的4种I/O模型都是同步IO,最后一种I/O模型是异步IO。异步I/O就是先向操作系统注册读写述求,然后就立马返回,进程不会被挂起。操作系统在完成读写操作之后,再调用进程之前注册读写述求时指定的回调函数,或者触发指定的信号。
五种IO方式:
同步阻塞IO(BIO)、同步非阻塞IO、同步I/O复用、同步信号驱动I/O、异步I/O
- BIO: 阻塞同步IO:发起调用,Read/Write会直接阻塞到完成。
- NIO: IO多路复用:通过向其中进行注册,检查每个当前就需的IO(Read、Write),在处理的时候会进行阻塞(从内核态复制到用户态导致了阻塞)
- Server,Channl,Buffer
- AIO: 异步IO:从内核态到用户太有单独的处理。无需阻塞用户线程。
- Java NIO通过设定继承
,实现在对应的Accept,Read,Write中执行的操作。会在开始的时候就创建N个线程。Thread-0阻塞在EPoll.wait()方法上,Thread-1.. Thread-n阻塞在BlockingQueue中获取任务。主要分为注册事件(向EPoll中注册事件)、监听事件(通过EPoll.wait监听事件)、处理事件(通过回调函数进行执行处理事件)。由于内核态无法直接调用用户态,所以,本质上,AIO不太理想。Linux中Epoll,Windows是IOCP,Mac KQueue。
- Java NIO通过设定继承
死锁的原因以及解决方法
循环依赖:a依赖b,b依赖a,两个就会死锁。
不可剥夺:别人想要获取,不会释放,只能由自己进行释放。
互斥共享:涉及的资源是非共享的,即一次只能有一个进程使用。如果有另一个进程申请该资源,那么申请进程必须等待,直到该资源被释放。
占有并等待(部分分配):进程每次申请它所需要的一部分资源。在等待一新资源的同时,进程继续占用已分配到的资源。
预防死锁
破坏必要条件。
检测死锁
当有可能发生死锁的时候,就直接不分配资源
接触死锁
释放资源,关闭进程,重启。
CopyOnWrite机制Linux I/O
零拷贝:
- mmap+write:mmap标识从内核态缓冲区不直接拷贝到用户态缓冲区,而是直接进行虚拟地址的映射。
- sendfile:专门用来进行sendFile,直接在内核态将文件发送给另一个缓存
- splice:类似于sednFile,但是使用的是两个文件之间
- Direct I/O(针对这种问题有不同的效果,很难去实现,因为地址对齐)异步I/O:
- 大文件进行拷贝会导致PageCache占满,使得效率变差。所以。可以使用Direct I/O,直接将文件复制到用户缓存中去。
CpoyOnWrite机制,写入复制。是一种计算机程序设计领域的优化策略。其核心思想是,如果有多个调用者(callers)同时请求相同资源(如内存或磁盘上的数据存储),他们会共同获取相同的指针指向相同的资源,直到某个调用者试图修改资源的内容时,系统才会真正复制一份专用副本(private copy)给该调用者,而其他调用者所见到的最初的资源仍然保持不变。这过程对其他的调用者都是透明的。此作法主要的优点是如果调用者没有修改该资源,就不会有副本(private copy)被创建,因此多个调用者只是读取操作时可以共享同一份资源。比如在Fork()或者Join()创建父子进程的时候,会有这种效果。Redis使用在RDB持久化的时候实现了COW机制。
TCP和UDP的区别
应用->表示->会话->传输->网络->数据链路层->物理层
TCP是可靠的、面向连接的、双向的网络层协议。可以是的传输的信息有序并且无差错、不重复。基于字节的。端口号为2^16 - 1
UDP是不可靠的,无链接的,可以实现一对一,一对多,多对多。基于数据纸。
TCP实现可靠传输的原理
TCP通过会对信息分片,分片有递增的序列,保证到达的最后是正确的顺序。有重发机制,接受方法会发送ACK信号,保证信息的准确接受。并且有流量控制窗口,能够避免消息的丢失和网络的拥堵。
TCP的握手和挥手
三次握手,四次挥手。
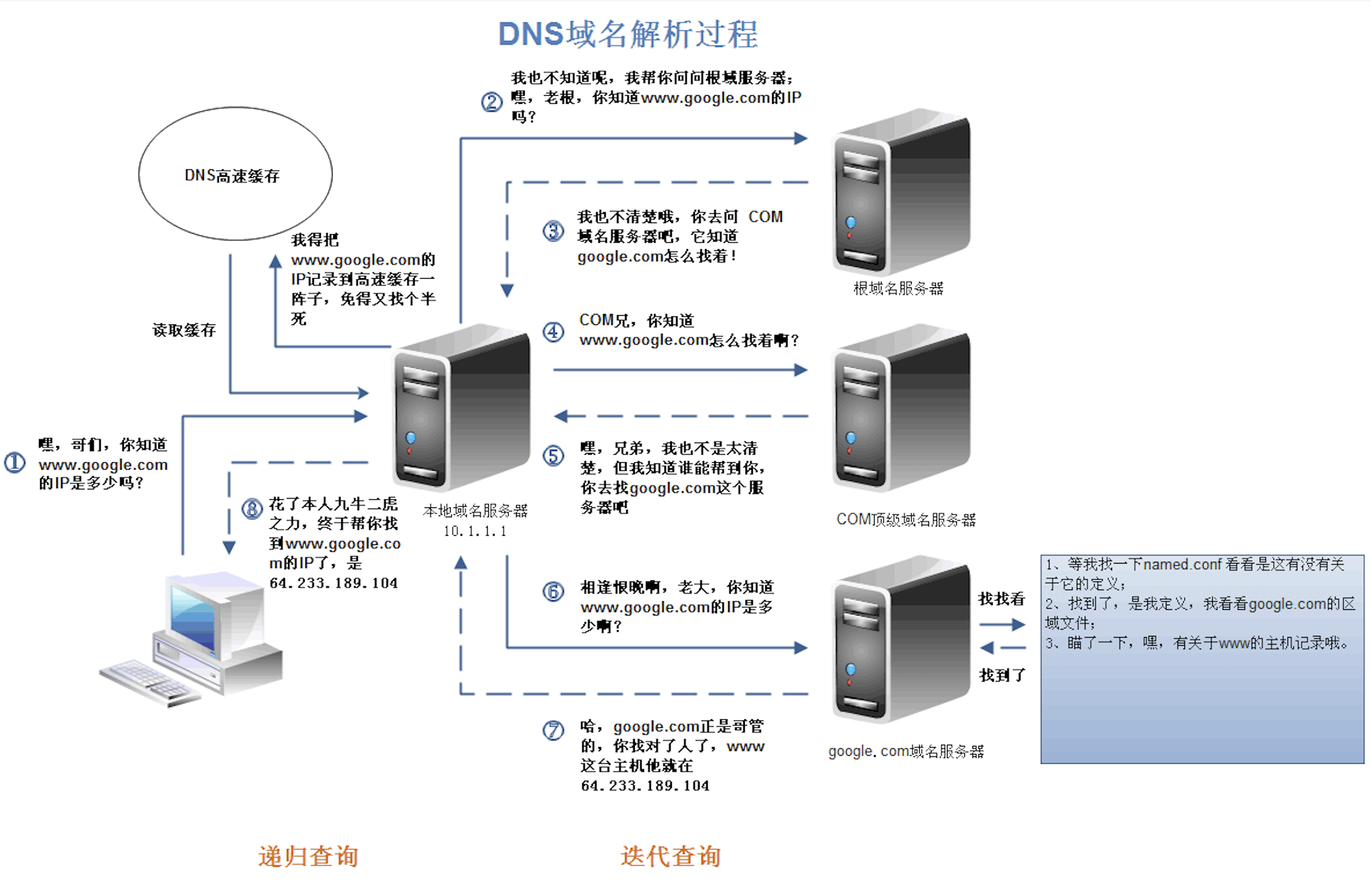
DNS
域名解析服务。会先查看本地缓存有没有保存。如果有的话,那么直接进行找到,没有的话想root server发送请求,得到权威机构的server得到,还有二级的server等,最终域名对应的IP地址。
Http1.0 Http1.1 Http2.0
http1.1相对于http1.0增加了put,delete等方法,增加了缓存的设置,增加了长链接的设置。
http2.0相对于http1.1使用了头部压缩,可以同时发送多个请求,使用了二进制进行传输,并且可以主动从服务器向客户端进行推送。
Spring
Spring Boot启动流程
@SpringBootConfiguration 标识为一个IOC容器的配置类
@EnableAutoConfiguration 标识启用自动配置
@ComponentScan 进行xml配置文件的自动扫描
Spring容器流程
- 初始化Spring容器,注册内置的BeanPostProcessor的BeanDefinition到容器中
实例化BeanFactory,生成Bean对象。生成注解配置的读取器,读取器可以读取为BeanDefinite对象,定义了Bean的属性信息。配置路径扫描器,对指定路径下的Bean进行扫描。 - 将配置类的BeanDefinition注册到容器中。
- 调用refresh()方法刷新容器。Spring容器的启动流程
Spring @Atuowired原理
SpringBoot自动装载原理
通过SPI进行装载,每次启动都会读取META-INFO下的配置文件进行装载,和默认的一些需要装载的。
Spring的请求到返回相应的流程
同下
Spring Boot启动流程
Spring Boot请求流程
同下
Spring MVC流程
每一个Request的请求会达到Tomact的DispatcherHander上,Dispatcer对任务进行分配,查找哪一个Dispatcher调用那个Hander,通过一个链式的Hander进行处理,包含了一系列拦截器,true执行,false失败,最终回到Controller的对应的方法上,之后,Controller会返回一个,会返回一个视图和model给dispacherHander进行分配,解析model和view,返回给前段。如果是Json,直接就返回了,无需解析。Intercepter就是在链中进行执行的,
实战算法
URL黑名单(布隆过滤器)
100亿个URL,怎么存储这个黑名单?
使用布隆过滤器。
布隆过滤器
它实际上一个很长的二进制矢量和一系列随机映射函数。
它可以用来判断一个元素是否在一个集合中。它的优势是只需要占用很小的内存空间以及有着高效的查询效率。对于布隆过滤器而言,它的本质是一个位数组:位数组就是数组的每个元素都只占用1 bit,并且每个元素只能是0或者1。
在数组中的每一位都是二进制位。布隆过滤器除了一个位数组,还有K个哈希函数。当一个元素加入布隆过滤器中的时候,会进行如下操作:
使用K个哈希函数对元素值进行K次计算,得到K个哈希值。
根据得到的哈希值,在位数组中把对应下标的值置为1。
词频统计(trim + nums)
2GB内存在20亿整数中找到出现次数最多的数
通常做法是使用哈希表对出现的每一个数做词频统计,哈希表的key是某个整数,value记录整数出现的次数。本题的数据量是20亿,有可能一个数出现20亿次,则为了避免溢出,哈希表的key是32位(4B),value也是32位(4B),那么一条哈希表的记录就需要占用8B。
当哈希表记录数为2亿个时,需要16亿个字节数(8*2亿),需要至少1.6GB内存(16亿/230,1GB==230个字节==10亿)。则20亿个记录,至少需要16GB的内存,不符合题目要求。
解决办法是将20亿个数的大文件利用哈希函数分成16个小文件,根据哈希函数可以把20亿条数据均匀分布到16个文件上,同一种数不可能被哈希函数分到不同的小文件上,假设哈希函数够好。然后对每一个小文件用哈希函数来统计其中每种数出现的次数,这样我们就得到16个文件中出现次数最多的数,接着从16个数中选出次数最大的那个key即可。
未出现的数(bit数组)
40亿个非负整数中找到没有出现的数(redis的BitMap)
对于原问题,如果使用哈希表来保存出现过的数,那么最坏情况下是40亿个数都不相同,那么哈希表则需要保存40亿条数据,一个32位整数需要4B,那么40亿*4B= 160亿个字节,一般大概10亿个字节的数据需要1G的空间,那么大概需要16G的空间,这不符合要求。
我们换一种方式,申请一个bit数组,数组大小为4294967295,大概为40亿bit,40亿/8=5亿字节,那么需要0.5G空间,bit数组的每个位置有两种状态0和1,那么怎么使用这个bit数组呢?呵呵,数组的长度刚好满足我们整数的个数范围,那么数组的每个下标值对应4294967295中的一个数,逐个遍历40亿个无符号数,例如,遇到20,则bitArray[20]=1;遇到666,则bitArray[666]=1,遍历完所有的数,将数组相应位置变为1。
40亿个非负整数中找到一个没有出现的数,内存限制10MB
重复URL(分机器)
找到100亿个URL中重复的URL,hash分
TOPK搜索(小根堆)
hash分,之后可以用小根堆实现查找每一个的top100,然后汇总打死一起,总得top100
*中位数
内存够:内存够还慌什么啊,直接把100亿个全部排序了,你用冒泡都可以...然后找到中间那个就可以了。但是你以为面试官会给你内存??
内存不够:题目说是整数,我们认为是带符号的int,所以4字节,占32位。
假设100亿个数字保存在一个大文件中,依次读一部分文件到内存(不超过内存的限制),将每个数字用二进制表示,比较二进制的最高位(第32位,符号位,0是正,1是负),如果数字的最高位为0,则将这个数字写入file_0文件中;如果最高位为1,则将该数字写入file_1文件中。
从而将100亿个数字分成了两个文件,假设file_0文件中有60亿个数字,file_1文件中有40亿个数字。那么中位数就在file_0文件中,并且是file_0文件中所有数字排序之后的第10亿个数字。(file_1中的数都是负数,file_0中的数都是正数,也即这里一共只有40亿个负数,那么排序之后的第50亿个数一定位于file_0中)
现在,我们只需要处理file_0文件了(不需要再考虑file_1文件)。对于file_0文件,同样采取上面的措施处理:将file_0文件依次读一部分到内存(不超内存限制),将每个数字用二进制表示,比较二进制的次高位(第31位),如果数字的次高位为0,写入file_0_0文件中;如果次高位为1,写入file_0_1文件中。
现假设file_0_0文件中有30亿个数字,file_0_1中也有30亿个数字,则中位数就是:file_0_0文件中的数字从小到大排序之后的第10亿个数字。
抛弃file_0_1文件,继续对file_0_0文件根据次次高位(第30位)划分,假设此次划分的两个文件为:file_0_0_0中有5亿个数字,file_0_0_1中有25亿个数字,那么中位数就是file_0_0_1文件中的所有数字排序之后的 第5亿个数。
按照上述思路,直到划分的文件可直接加载进内存时,就可以直接对数字进行快速排序,找出中位数了。
设计短域名系统,将长URL转化成短的URL.
利用放号器,初始值为0,对于每一个短链接生成请求,都递增放号器的值,再将此值转换为62进制(a-zA-Z0-9),比如第一次请求时放号器的值为0,对应62进制为a,第二次请求时放号器的值为1,对应62进制为b,第10001次请求时放号器的值为10000,对应62进制为sBc。
将短链接服务器域名与放号器的62进制值进行字符串连接,即为短链接的URL,比如:t.cn/sBc。
重定向过程:生成短链接之后,需要存储短链接到长链接的映射关系,即sBc ->URL,浏览器访问短链接服务器时,根据URL Path取到原始的链接,然后进行302重定向。映射关系可使用K-V存储,比如Redis或Memcache。
海量评论入库(消息队列)
假设有这么一个场景,有一条新闻,新闻的评论量可能很大,如何设计评论的读和写
前端页面直接给用户展示、通过消息队列异步方式入库
读可以进行读写分离、同时热点评论定时加载到缓存
秒杀项目构型
秒杀
用户数据预热, 构建用户历史记录,将恶意用户拦截在上游
多读少些,可以采用先清除缓存,在写入数据库,可以设置延迟双删时间。
二倍均值算法
抢红包,n个人抢m,每个钱抢[0.01 - m * 2 / n] 比如 4个人抢100,第一个人在[0.01 - 49.9]平均都是25,第一个人抢完之后,抢了k,在使用[0.01 - (m - k) * 2 / (n - 1)]

