07、Etcd 中Raft算法简介
本篇内容主要来源于自己学习的视频,如有侵权,请联系删除,谢谢。
思考: etcd是如何基于Raft来实现高可用、数据强—致性的?
1、什么是Raft算法
Raft 算法是现在分布式系统开发首选的共识算法。从本质上说,Raft 算法是通过一切以领导者为准的方式,实现一系列值的共识和各节点日志的一致。领导者就是 Raft 算法中的霸道总裁,Raft 算法是强领导者模型,集群中只能有一个“霸道总裁”。
下面是一个讲解 raft 算法的一个网站,有可视化的图形,可以帮忙我们理解 raft 算法。
Raft is a consensus algorithm for managing a replicated log. It produces a result equivalent to (multi-)Paxos, and it is as efficient as Paxos, but its structure is different from Paxos;
Raft是一种用于管理复制日志的共识算法。它产生与多Paxos一样的结果,并且与Paxos一样高效,但其结构与Paxos不同。
2、为什么需要 Raft
回答该问题之前可以思考一下另一个问题:为什么需要共识算法? 为了解决单点问题,软件系统工程师引入了数据复制技术,实现多副本。而多副本间的数据 复制就会出现一致性问题。所以需要共识算法来解决该问题。
共识算法的祖师爷是 Paxos, 但是由于它过于复杂,难于理解,工程实践上也较难落地, 导致在工程界落地较慢。 Raft 算法正是为了可理解性、易实现而诞生的。它通过问题分 解,将复杂的共识问题拆分成三个子问题,分别是:
- Leader选举:Leader故障后集群能快速选出新Leader;
- 日志复制:集群只有Leader能写入日志,Leader负责复制日志到Follower节点, 并强制Follower节点与自己保持相同;
- 安全性:一个任期内集群只能产生一个Leader、已提交的日志条目在发生 Leader选举时,一定会存在更高任期的新Leader日志中、各个节点的状态机应用的 任意位置的日志条目内容应—样等。
3、Leader 选举
当etcd server收到client 发起的put hello写请求后,KV模块会向Raft模块提交一个put提 案,我们知道只有集群Leader才能处理写提案,如果此时集群中无Leader,整个请求就会超时。
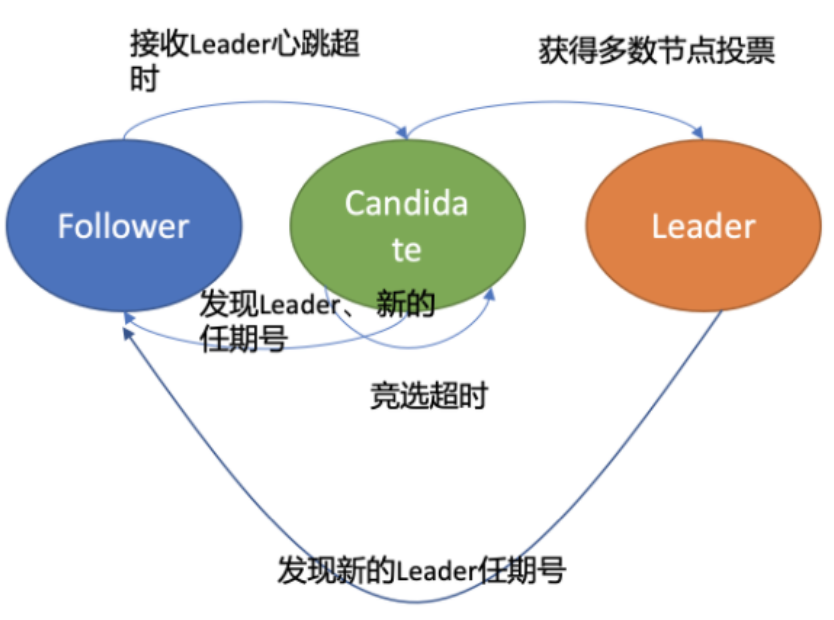
3.1、节点状态
首先在 Raft 协议中它定义了集群中的如下节点状态,任何时刻,每个节点肯定处于其中一 个状态:
-
Follower:跟随者, 同步从 Leader 收到的日志,etcd 启动的时候默认为此状 态; -
Candidate:竞选者,可以发起 Leader 选举; -
Leader:集群领导者, 唯一性,拥有同步日志的特权,需定时广播心跳给 Follower 节点,以维持领导者身份。
3.2、term
Raft 协议将时间划分成一个个任期(Term),任期用连续的整数表示,每个任期从一次选举开始,赢得选举的节点在该任期内充当 Leader 的职责,随着时间的消逝,集群可能会发 生新的选举,任期号也会单调递增。
通过任期号,可以比较各个节点的数据新旧、识别过期的 Leader 等,它在 Raft 算法中充当逻辑时钟,发挥着重要作用。
3.3、选举流程
当 Follower 节点接收 Leader 节点心跳消息超时后,它会转变成 Candidate 节点,并可发 起竞选 Leader 投票,若获得集群多数节点的支持后,它就可转变成 Leader 节点。
etcd 默认心跳间隔时间(heartbeat-interval)是 100ms, 默认竞选超时时间(election timeout)是 1000ms。
注意:
你需要根据实际部署环境、业务场景适当调优,否则就很可能会频繁发生 Leader 选举切 换,导致服务稳定性下降。
我们以Leader crash场景为案例,详细介绍一下etcd Leader选举原理。
假设集群总共3个节点,A节点为Leader,B、C节点为Follower。

election: 选举
如上Leader选举图左边部分所示,正常情况下,Leader节点会按照心跳间隔时间,定时广 播心跳消息(MsgHeartbeat消息)给Follower节点,以维持Leader身份。Follower收到后 回复心跳应答包消息(MsgHeartbeatResp 消息)给Leader。
当 Leader 节点异常后,Follower 节点会接收 Leader 的心跳消息超时,当超时时间大于竞 选超时时间后,它们会进入 Candidate 状态。
进入 Candidate 状态的节点,会立即发起选举流程,自增任期号,投票给自己,并向其他 节点发送竞选 Leader 投票消息(MsgVote)。
C 节点收到 Follower B 节点竞选 Leader 消息后,这时候可能会出现如下两种情况:
-
第一种情况: C 节点判断 B 节点的数据至少和自己一样新、B 节点任期号大于 C 当前任 期号、并且 C 未投票给其他候选者,就可投票给 B。这时 B 节点获得了集群多数节 点支持,于是成为了新的 Leader。
-
第二种情况:恰好 C 也心跳超时超过竞选时间了,它也发起了选举,并投票给了自己,那 么它将拒绝投票给 B,这时谁也无法获取集群多数派支持,只能等待竞选超时,开启 新一轮选举。
Raft 为了优化选票被瓜分导致选举失败的问题,引入了随机数,每个 节点等待发起选举的时间点不一致,优雅的解决了潜在的竞选活锁,同时易于理解。
如果现有 Leader 发现了新的 Leader 任期号,那么它就需要转换到 Follower 节点。A 节 点 crash 后,再次启动成为 Follower,假设因为网络问题无法连通 B、C 节点,这时候根 据状态图,我们知道它将不停自增任期号,发起选举。等 A 节点网络异常恢复后,那么现 有 Leader 收到了新的任期号,就会触发新一轮 Leader 选举,影响服务的可用性。
那如何避免以上场景中的无效的选举呢?
在 etcd 3.4 中,etcd 引入了一个 PreVote 参数(默认 false),可以用来启用 PreCandidate 状态解决此问题。Follower 在转换成 Candidate 状态前,先进入 PreCandidate 状态,不自增任期号, 发起预投票。若获得集群多数节点认可,确定有概率 成为 Leader 才能进入 Candidate 状态,发起选举流程。

因 A 节点数据落后较多,预投票请求无法获得多数节点认可,因此它就不会进入 Candidate 状态,导致集群重新选举。
这就是 Raft Leader 选举核心原理,使用心跳机制维持 Leader 身份、触发 Leader 选举, etcd 基于它实现了高可用,只要集群一半以上节点存活、可相互通信,Leader 宕机后,就 能快速选举出新的 Leader,继续对外提供服务。
3.4、日志复制
具体流程如下图所示:

- Leader 收到写请求后,生成一个提案并提交给 Raft 模块
- Leader 的Raft 模块为此提案生成一个日志条目,并追加到 Raft 日志中,此处 有 WAL持久化。
- Leader 将新的日志发送给 Follower,Leader 会维护两个核心字段来追踪各个 Follower 的进度信息,一个字段是 NextIndex, 它表示 Leader 发送给 Follower 节点的下一个日志条目索引。一个字段是 MatchIndex, 它表示 Follower 节点已复 制的最大日志条目的索引。
- Follower 收到日志后先进行安全检测,通过检测后将该日志写入自己的 Raft 日 志中,并回复 Leader 当前已复制的日志最大索引。此处也有WAL持久化。
- 最后 Leader 根据 Follower 的 MatchIndex 信息,找出已经被半数以上的节点 同步的位置,这个位置之前的所有日志条目都可以提交了。
- Leader 通过消息告诉 Follower 那些日志条目可以执行提交了
- Follower 根据 Leader 的信息从Raft模块中取出对应日志条目内容,并应用到状 态机中。
通过以上流程,Leader 就完成了同步日志条目给 Follower 的任务,一个日志条目被确定 为已提交的前提是,它需要被 Leader 同步到一半以上节点上。以上就是 etcd Raft 日志复 制的核心原理。
3.5、raft 日志
下图是 Raft 日志复制过程中的日志细节图:

在日志图中,最上方的是日志条目序号/索引,日志由有序号标识的一个个条目组成,每个 日志条目内容保存了Leader任期号和提案内容。最开始的时候,A节点是 Leader,任期号 为1,A节点crash 后,B节点通过选举成为新的Leader,任期号为2。
Leader 是如何知道从哪个索引位置发送日志条目给 Follower,以及 Follower 已复制的日 志最大索引是多少呢?
Leader 会维护两个核心字段来追踪各个 Follower 的进度信息:
- 一个字段是 NextIndex, 它表示 Leader 发送给 Follower 节点的下一个日志条目索引。
- 一个字段是 MatchIndex, 它表示 Follower 节点已复制的最大日志条目的索引,比如上面的日志图 1 中 C 节点的已 复制最大日志条目索引为 5,A 节点为 4。
3.6、安全性
假设当前raft日志条目如下图所示:

Leader B 在应用日志指令 put hello 为 world 到状态机,并返回给 client 成功后,突然 crash 了,那么 Follower A 和 C 是否都有资格选举成为 Leader 呢?
从日志图 2 中我们可以看到,如果 A 成为了 Leader 那么就会导致数据丢失,因为它并未 含有刚刚 client 已经写入成功的 put hello 为 world 指令。
Raft 算法如何确保面对这类问题时不丢数据和各节点数据一致性呢?
Raft 通过给选举和日志复制增加一系列规则,来实现 Raft 算法的安全性。
3.6.1、选举规则
当节点收到选举投票的时候,需检查候选者的最后一条日志中的任期号:
-
若小于自己则拒绝投票。
-
如果任期号相同,日志却比自己短,也拒绝为其投票。
这样能保证投票的节点数据至少比当前节点数据新。
3.6.2、日志复制规则
在日志图 2 中,Leader B 返回给 client 成功后若突然 crash 了,此时可能还并未将 6 号 日志条目已提交的消息通知到 Follower A 和 C,那么如何确保 6 号日志条目不被新 Leader 删除呢? 同时在 etcd 集群运行过程中,Leader 节点若频繁发生 crash 后,可能 会导致Follower 节点与 Leader 节点日志条目冲突,如何保证各个节点的同 Raft 日志位置 含有同样的日志条目?
以上各类异常场景的安全性是通过 Raft 算法中的 Leader 完全特性和只附加原则、日志匹 配等安全机制来保证的。
-
Leader 完全特性:是指如果某个日志条目在某个任期号中已经被提交,那么这 个条目
必然出现在更大任期号的所有 Leader 中。 -
只附加原则: Leader
只能追加日志条目,不能删除已持久化的日志条目。因此 Follower C 成为新 Leader 后,会将前任的 6 号日志条目复制到 A 节点。 -
日志匹配特性: Leader 在发送追加日志 RPC 消息时,会把新的日志条目紧接着 之前的条目的索引位置和任期号包含在里面。Follower 节点会检查相同索引位置的 任期号是否与 Leader 一致,一致才能追加。(它本质上是一种归纳法,一开始日志为空,满足匹配特性,随后每增加一个日志条目时,都要求上一个日志条目信息与 Leader 一致,那么最终整个日志集肯定是一致的。)
通过以上的 Leader 选举限制、Leader 完全特性、只附加原则、日志匹配等安全特性,Raft 就实现了一个可严格通过数学反证法、归纳法证明的高可用、一致性算法,为 etcd 的 安全性保驾护航。
参考资料:
raft算法简介
这个up讲得不错,推荐看


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· CSnakes vs Python.NET:高效嵌入与灵活互通的跨语言方案对比
· DeepSeek “源神”启动!「GitHub 热点速览」
· 我与微信审核的“相爱相杀”看个人小程序副业
· Plotly.NET 一个为 .NET 打造的强大开源交互式图表库
· 上周热点回顾(2.17-2.23)