正则表达式
/* 一: 基本操作 二: 匹配: 字符 三: 匹配: 数量 四: 开头结尾 五: 匹配分组 */
一: 基本操作
import re if __name__ == '__main__': # 匹配操作: match() result = re.match(正则表达式, 要匹配的字符串) # 提取数据: group() result.group() import re if __name__ == '__main__': result = re.match("cnblogs.","cnblogs.com") info = result.group() # cnblogs. print(info)
二: 匹配: 字符

import re # . : 任意1个字符 if __name__ == '__main__': ret = re.match(".", "M") print(ret.group()) # M ret = re.match("t.o", "too") print(ret.group()) # too ret = re.match("t.o", "two") print(ret.group()) # two # [] : 多中取1 if __name__ == '__main__': # 匹配字母 result = re.match("h","hello") print(result.group()) # h result = re.match("H","Hello") print(result.group()) # H result = re.match("[Hh]","hello") print(result.group()) # h # 匹配数字 result = re.match("[0123456789]","6hello") print(result.group()) # 6 result = re.match("[0-9]","6hello") print(result.group()) # 6 # \d : 数字 if __name__ == '__main__': result = re.match("嫦娥\d号","嫦娥6号") print(result.group()) # 嫦娥6号 # \D : 非数字 if __name__ == '__main__': result = re.match("\D","嫦娥66号") print(result.group()) # 嫦 # \s : 空白 if __name__ == '__main__': match_obj = re.match("hello\sworld", "hello world") if match_obj: result = match_obj.group() print(result) # hello world else: print("匹配失败") # \S : 非空白 if __name__ == '__main__': match_obj = re.match("hello\Sworld", "hello0world") result = match_obj.group() print(result) # hello0world # \w : 非特殊字符 if __name__ == '__main__': match_obj = re.match("\w", "ab") result = match_obj.group() print(result) # a # \W : 特殊字符 if __name__ == '__main__': match_obj = re.match("\W", "#") result = match_obj.group() print(result) # #
三: 匹配: 数量
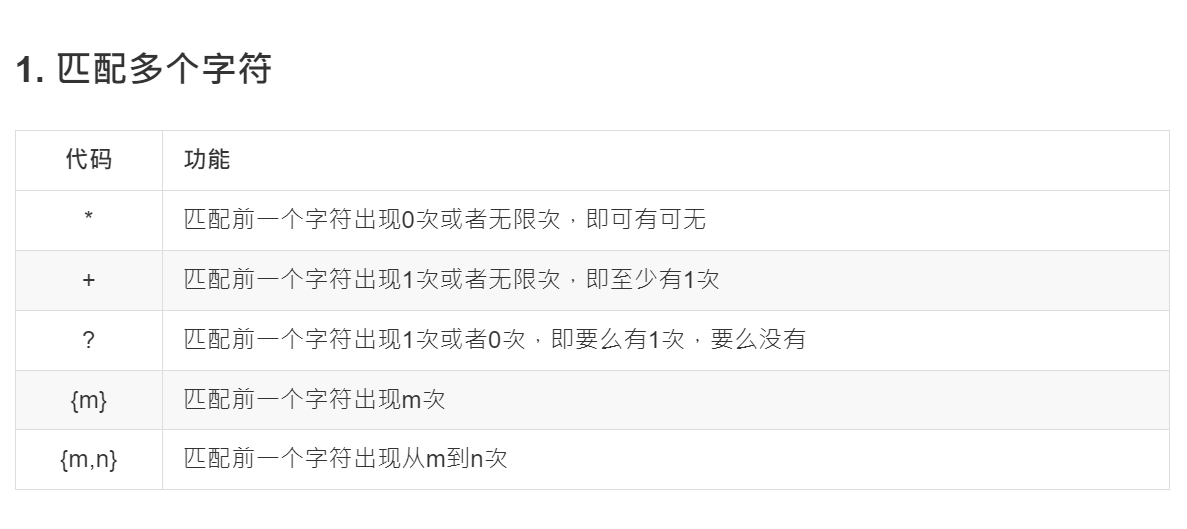
import re # * : 匹配前一个字符出现0次或者无限次 if __name__ == '__main__': ret = re.match("[A-Z][a-z]*", "M") print(ret.group()) # M if __name__ == '__main__': ret = re.match("[A-Z][a-z]*", "MmmM") print(ret.group()) # Mmm if __name__ == '__main__': ret = re.match("[A-Z][a-z]*", "MmmMnn") print(ret.group()) # Mmm # + : 匹配前一个字符出现1次或者无限次 if __name__ == '__main__': match_obj = re.match("t.+o", "two") print(match_obj.group()) # two # ? : 匹配前一个字符出现1次或者0次 if __name__ == '__main__': match_obj = re.match("https?", "http") print(match_obj.group()) # http # {m} : 匹配前一个字符出现m次 # {m, n} : 匹配前一个字符出现从m到n次 if __name__ == '__main__': ret = re.match("[a-zA-Z0-9]{6}", "12a3g45678") print(ret.group()) # 12a3g4 if __name__ == '__main__': ret = re.match("[a-zA-Z0-9]{10,12}", "1ad12f23s34455ff66") print(ret.group()) # 1ad12f23s344
四: 开头结尾
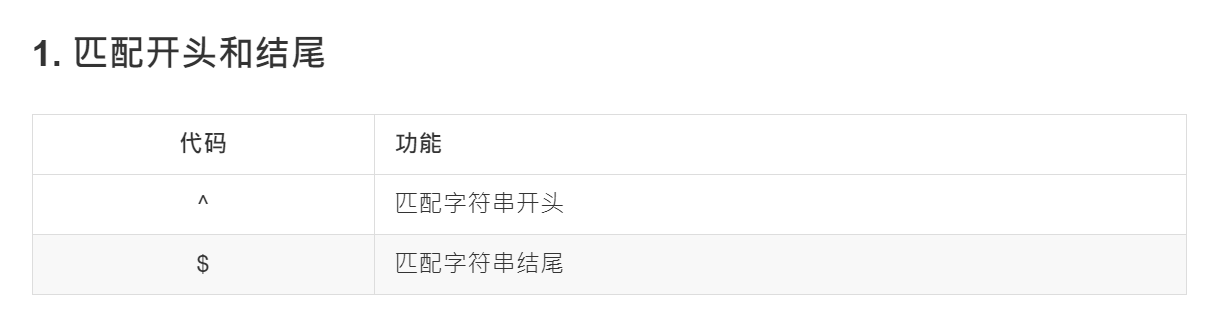
# ^ : 匹配字符串开头 # $ : 匹配字符串结尾 if __name__ == '__main__': ret = re.match("^\d.*", "3hello") print(ret.group()) # 3hello if __name__ == '__main__': ret = re.match(".*\d$", "3hello6") print(ret.group()) # 3hello6
# 匹配以数字开头中间内容不管以数字结尾 if __name__ == '__main__': ret = re.match("^\d.*\d$", "6hello6") print(ret.group()) # 6hello6 # [^指定字符]: 表示除了指定字符都匹配 if __name__ == '__main__': ret = re.match("[^abcef]", "dello6") print(ret.group()) # d
五: 匹配分组

# | : 匹配左右任意一个表达式 if __name__ == '__main__': fruit_list = ["apple", "banana", "orange", "pear"] for value in fruit_list: match_obj = re.match("apple|pear", value) if match_obj: print("%s 是我想要的" %match_obj.group()) else: print("%s 不是我想要的" %value) # (ab) : 括号中字符作为一个分组 if __name__ == '__main__': # 需求: 匹配qq:10567这样的数据,提取出来qq文字和qq号码 match_obj = re.match("(qq):([1-9]\d{4,10})", "qq:10567") if match_obj: print(match_obj.group()) # qq:10567 print(match_obj.group(1)) # qq print(match_obj.group(2)) # 10567 else: print("匹配失败") # \num : 引用分组num匹配到的字符串 match_obj = re.match("<[a-zA-Z1-6]+>.*</[a-zA-Z1-6]+>", "<html>hh123</div>") print(match_obj.group()) # <html>hh123</div> match_obj = re.match("<([a-zA-Z1-6]+)>.*</\\1>", "<html>h789h</html>") print(match_obj.group()) # <html>h789h</html> match_obj = re.match("<([a-zA-Z1-6]+)><([a-zA-Z1-6]+)>.*</\\2></\\1>", "<html><h1>www.cnblogs.cn</h1></html>") print(match_obj.group()) # <html><h1>www.cnblogs.cn</h1></html> # (?P<name>) (?P=name) : 分组起别名 引用别名 match_obj = re.match("<(?P<name1>[a-zA-Z1-6]+)><(?P<name2>[a-zA-Z1-6]+)>.*</(?P=name2)></(?P=name1)>", "<html><h1>www.cnblogs.cn</h1></html>") print(match_obj) # <re.Match object; span=(0, 36), match='<html><h1>www.cnblogs.cn</h1></html>'>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号