BP神经网络基本原理
BP神经网络是一种单向传播的多层前向网络,具有三层或多层以上的神经网络结构,其中包含输入层、隐含层和输出层的三层网络应用最为普遍。
网络中的上下层之间实现全连接,而每层神经元之间无连接。当一对学习样本提供给网络后,神经元的激活值从输入层经各中间层向输出层传播,在输出层的各神经元获得网络的输入相应。然后,随着减小目标输出与实际误差的方向,从输出层经过各中间层修正各连接权值,最后回到输入层。
BP算法是在建立在梯度下降基础上的,BP算法的知道思想是对网络权值与阈值的修正,使误差函数沿负梯度下方向。
BP算法推算过程
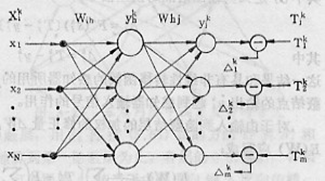
当加入第k个输入时,隐蔽层h结点的输入加权和为:
skh=∑iwihxki
相应点的输出:
ykh=F(skh)=F(∑iwihxki)
同样,输出层j结点的输入加权和为:
skj=∑hwhjykh=∑hwhjF(∑iwihxki)
相应点的输出:
ykj=F(skj)=F(∑hwhjykh)=F[∑hwhjF(∑iwihxki)]
这里,各结点的阈值等效为一个连接的加权θ=wohorwoj,这些连接由各结点连到具有固定值-1的偏置结点,其连接加权也是可调的,同其它加权一样参与调节过程。
误差函数为:
E(W)=12∑k,j(Tkj−ykj)2=12∑k,j{Tkj−F[∑hwhjF(∑iwihxki)]}2
为了使误差函数最小,用梯度下降法求得最优的加权,权值先从输出层开始修正,然后依次修正前层权值,因此含有反传的含义。
根据梯度下降法,由隐蔽层到输出层的连接的加权调节量为:
Δwhj=−η∂E∂whj=η∑k(Tkj−ykj)F′(skj)ykh=η∑kδkjykh
其中δkj为输出结点的误差信号:
δkj=F′(skj)(Tkj−ykj)=F′(skj)Δkj(1)
Δkj=Tkj−ykj
对于输入层到隐蔽层结点连接的加权修正量Δwij,必须考虑将E(W)对wih求导,因此利用分层链路法,有:
Δwih=−η∂E∂wih=−η∑k∂E∂ykh⋅∂ykh∂wih=η∑k,j{(Tkj−ykj)F′(skj)whj⋅F′(skh)xki}=η∑k,jδkjwhjF′(skh)xki=η∑kδkhxki
其中:
δkh=F′(skh)∑jwhjδkj=F′(skh)Δkh(2)
Δkh=∑jwhjδkj
可以看出,式(1)和(2)具有相同的形式,所不同的是其误差值的定义,所以可定义BP算法对任意层的加权修正量的一般形式:
Δwpq=η∑vector_no_Pδoyin
若每加入一个训练对所有加权调节一次,则可写成:
Δwpq=ηδoyin
其中,下标o和in指相关连接的输出端点和输入端点,yin代表输入端点的实际输入,δo表示输出端点的误差,具体的含义由具体层决定,对于输出层由式(1)给出,对隐蔽层则由式(2)给出。
输出层Δkj=Tkj−ykj可直接计算,于是误差值δkj很容易得到。对前一隐蔽层没有直接给出目标值,不能直接计算Δkh,而需利用输出层的δkj来计算:
Δkh=∑jwhjδkj
因此,算出Δkh后,δkh也就求出了。
如果前面还有隐蔽层,用δkh再按上述方法计算Δk1和δk1,以此类推,一直将输出误差δ一层一层推算到第一隐蔽层为止。各层的δ求得后,各层的加权调节量即可按上述公式求得。由于误差δkj相当于由输出向输入反向传播,所以这种训练算法成为误差反传算法(BP算法)。
BP训练算法实现步骤
准备:训练数据组。设网络有m层,ymj表示第m中第j个节点的输出,y_^0(零层输出)等于xj,即第j个输入。wmij表示从ym−1i到ymj的连接加权。这里,m代表层号,而不是向量的类号。
1.将各加权随机置为小的随机数。可用均匀分布的随机数,以保证网络不被大的加权值所饱和。
2. 从训练数据组中选一数据对xk,Tk, 将输入向量加到输入层(m=0),使得对所有端点i: y0i=xki, k表示向量类号
3. 信号通过网络向前传播,即利用关系式:
ymj=F(smj)=F(∑iwmijym−1i)
计算从第一层开始的各层内每个节点i的输出ymj,直到输出层的每个节点的输出计算完为止。
4. 计算输出层每个结点的误差值(利用公式(1))
δmj=F′(smj)(Tkj−ymi)=ymj(1−ymj)(Tkj−ymj),(对Sigmod函数)
它是由实际输出和要求目标值之差获得。
5. 计算前面各层结点的误差值(利用公式(2))
δm−1j=F′(sm−1j∑iwjiδmi)
这里逐层计算反传误差,直到将每层类每个结点的误差值算出为止。
6. 利用加权修正公式
Δwmij=ηδmjym−1i
和关系
wnewij=woldij+Δwij
修正所有连接权。一般η=0.01−−1,称为训练速率系数。
7. 返回第2步,为下一个输入向量重复上述步骤,直至网络收敛。






【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧