xpath和contains模糊匹配
来源:https://www.cnblogs.com/kaibindirver/p/12072546.html
最近在弄数据爬取,研究了下xpath,也参考了很多文章,这篇总结不错,就直接复制过来了。
常见的用法举例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | #它会取class含有有test1和test2的元素xpath('//div[contains(@class,"test1") and contains(@class,"test2")]') #它会取class 含有 test1 或者test2满足时,或者同时满足时的元素xpath('//div[contains(@class,"test1") or contains(@class,"test2")]') 查找name属性中包含zhangsan关键字的页面元素//divt[contains(@name,'zhangsan')] xpath写法为 //a[text()='百度搜索'] 或者 //a[contains(text(),"百度搜索")]<a href="http://www.baidu.com">百度搜索</a>#开闭标签之间的文本内容//a[contains(@class,"news-item-title")]/text() #选中标签节点中获取指定属性的值//a[contains(@class,"news-item-title")]/@href # 选取class属性包含ing的href链接地址html.xpath("//div/p[2][contains(@class,'ing')]/a/@href")# 选取价格大于20元书的价格值html.xpath("//book[price>20.00]/price/text()")# 选取前2本书html.xpath("//book[position()<3]/title/text()")#取div位置大于2的 并且类包含three的html.xpath("//div[position()>2 and contains(@class,'three')]/@class")# 豆瓣电影评分大于8的电影//span[@class="rating_nums"][text()>8]#xpath定位标签中最后一个元素 last()//span[@class="comment-info"]//span[last()]#xpath定位标签中倒数第二个元素 last()//span[@class="comment-info"]//span[last()-1]#列表下一页 text()//div[@class="m-page"]/a[contains(text(),'下一页')]#在路径表达式中使用"|"运算符,您可以选取若干个路径。#选取 book 元素的所有 title 和 price 元素。//book/title | //book/price #选取文档中的所有 title 和 price 元素。//title | //price #选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。//bookstore/book/title | //price |
xpath可以以标签定位,也可以@任意属性:
如:以input标签定位:driver.find_element_by_xpath("//input[@id='kw']")
如:@type属性:driver.find_elements_by_xpath("//input[@type='text']")
一、xpath定位
1、常规属性
1.通过id定位
driver.find_element_by_xpath("//*[@id='kw']").send_keys("hao")

2.通过tag(标签)定位
*号匹配任何标签:driver.find_element_by_xpath("//*[@id='kw']")

也可以指定标签名称:driver.find_element_by_xpath("//input[@id='kw']")

3.通过class定位
driver.find_element_by_xpath("//input[@class='s_ipt']").send_keys("hao")

4.通过name定位
driver.find_element_by_xpath("//input[@name='wd']").send_keys("hao")

2、其他属性
1.其它属性
driver.find_element_by_xpath("//input[@autocomplete='off']").send_keys("hao")

2.多个属性组合(逻辑运算)
driver.find_elements_by_xpath("//input[@type='text' and @name='wd']")

3.绝对路径:/html/body/xxx/xx[@id=‘kw’]
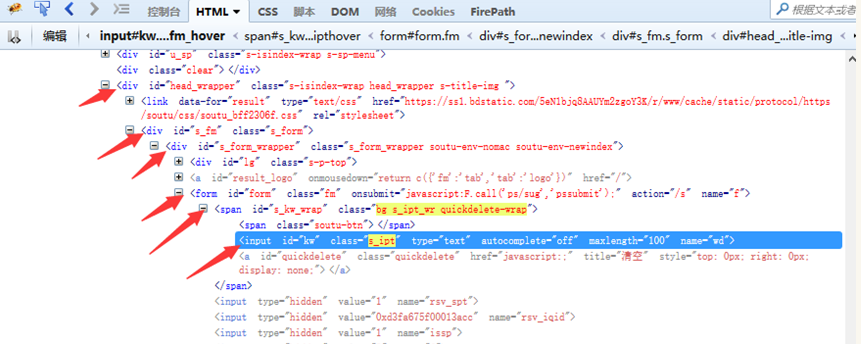
4、层级关系
1.相对路径:层级关系
driver.find_element_by_xpath("//form[@id='form']/span/input")

如:
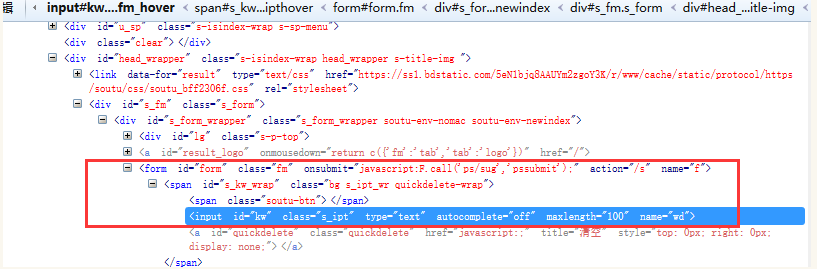
/代表绝对路径
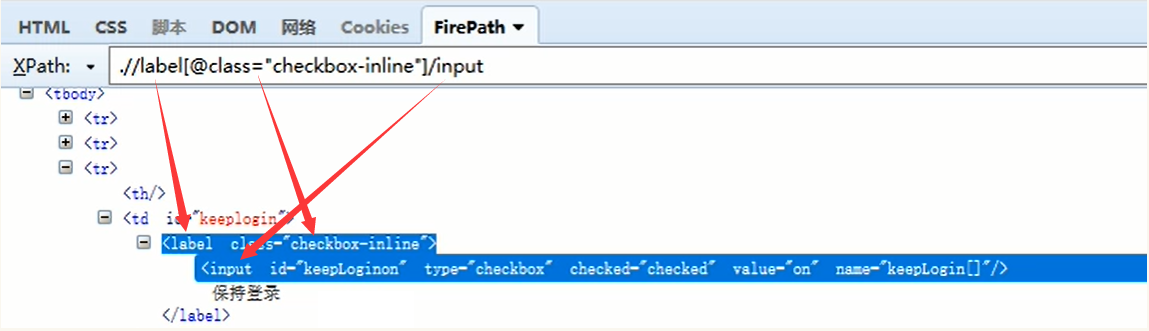
//代表相对路径
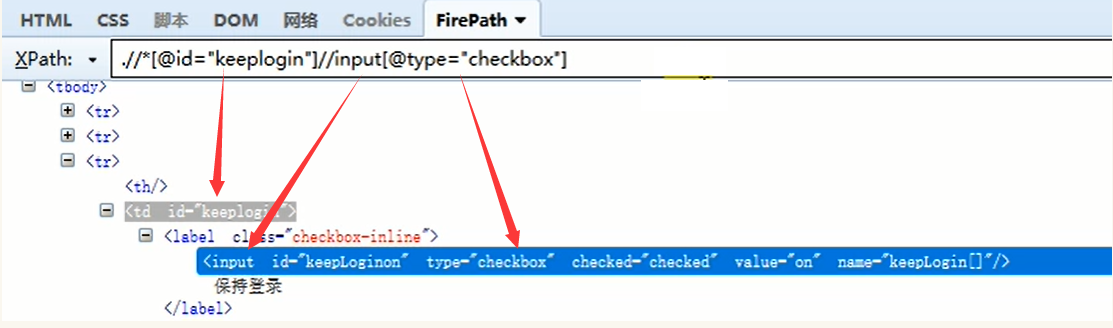
2.索引:如定位搜索选项框

driver.find_element_by_xpath("//*[@id='nr']/option[3]")

3.同一父级多个子元素
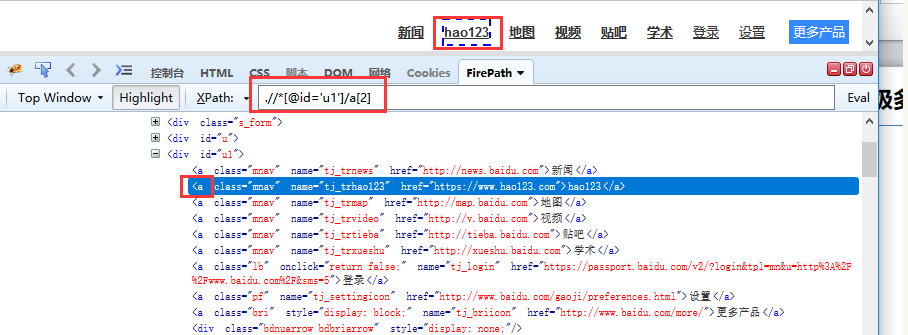
如果同一父级下,有多个相同的子元素,下标从1开始:.//*[@id='u1']/a[2]
也可以这样:.//*[@id='u1']/a[@class="mnav"][1]
4、模糊匹配
1.contains模糊匹配text:contains
如,通过模糊匹配text属性,找到百度首页的“糯米”网站超链接
driver.find_element_by_xpath("//a[contains(text(),'糯')]").click()

2.模糊匹配某个属性:contains
xpath("//input[contains(@id,‘xx')]")
driver.find_element_by_xpath("//input[contains(@class,'s_ip')]").send_keys("hao")

3.模糊匹配以xx开头:starts-with
xpath("//input[starts-with(@id,‘xx') ]")
driver.find_element_by_xpath("//input[starts-with(@class,'s_ip')]").send_keys("hao")

5、文本属性

对于这种文本属性,语法:.//*[text()=‘文本内容’]
除了这个文本属性匹配是.//*[text()=‘文本’]这种格式(无@)
其它的属性,如id,name,class等都是.//*[@id=‘xxx’] .//*[@name=‘xxx’]这种格式
二、浏览器调试xpath
1.Firefox调试:无firePath的情况下,控制台下输入$x(xpath定位),回车
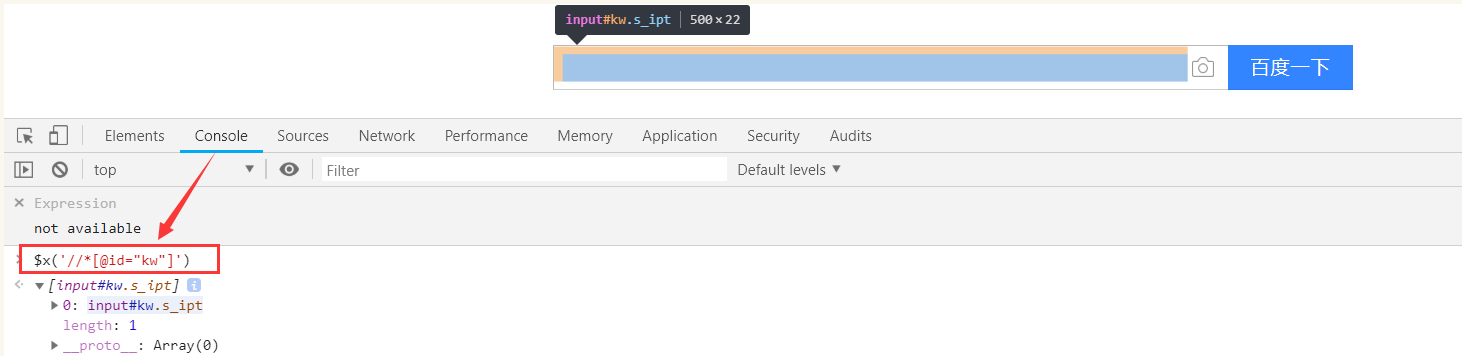
2.Chrome调试:Console下输入$x(xpath定位),回车
三、table表格定位
1、定位表格
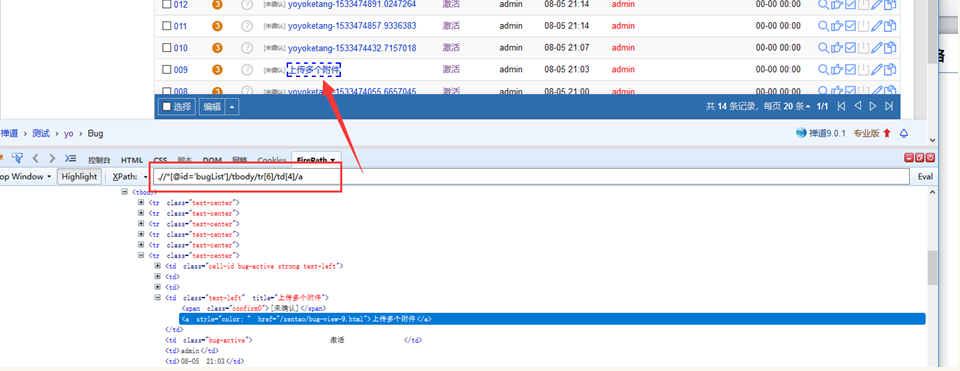
Table表格固定格式:.//*[@id=‘表格id’]/tbody/tr[行数]/td[列数]/a
.//*[@id='bugList']/tbody/tr[6]/td[4]/a
2、参数化行和列
x = 6
y = 4
table = f".//*[@id='bugList']/tbody/tr[{x}]/td[{y}]/a"
driver.find_element_by_xpath(table).click()

3、根据表格标题定位后面的按钮
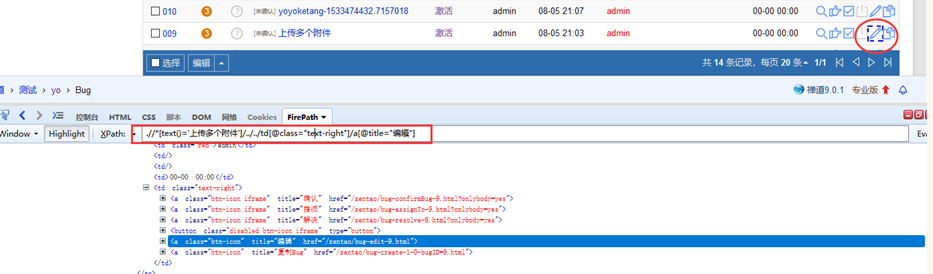
1.先通过bug的标题名称找到这一行
2.再找到这一行的父节点
3.通过父节点往下搜(编辑按钮都是固定位置)
text = "上传多个附件"
t = f'.//*[text()="{text}"]/../../td[@class="text-right"]/a[@title="编辑"]'
driver.find_element_by_xpath(t).click()




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
2014-03-23 fiddler无法抓取chrome解决方法