语义通信论文阅读(1):Beyond Transmitting Bits: Context, Semantics, and Task-Oriented Communications

《超越比特传输:上下文、语义和面向任务的通信》
这是2022年10月发布在IJSAC上的一篇语义通信的综述,作者是帝国理工学院的Deniz Gündüz,他也是Deep-JSCC等一系列文章的作者。这篇文章就是从香农的信息论出发,总结了语义通信迄今为止的工作,涵盖了理论基础、算法以及基础的实现。
引言
目前通信系统的目标是在噪声传输信道上可靠的传输比特,而香农的信道编码理论为这种传输提供了根本的限制,系统仍然不知道所要传达的信息的准确含义或者传达这些目的的意义。但正是这种与含义的分离,使得香农的方法能够从工程中抽离出来,即在某一点生成的数字序列,在另一点能够逐步的准确的复制出来。
然而,现在的通信目标发生了转变,由准确重建信息变成了使终端能够在正确的时间以及环境下做出正确的推断以及决策。变成这种趋势有以下两种原因:
- 新兴应用带来大量数据,大模型将会带来大流量。例如自动驾驶,每辆无人驾驶汽车每天都会从其众多传感器(包括雷达、LIDAR、摄像头和超声波传感器)中收集数十万亿比特级的数据。
- 新兴应用要求极低的端到端延迟,例如当视频信号被自动驾驶汽车用于检测和避免街道上潜在的障碍物或行人时,即使是微小的延迟也可能是不可接受的。
所以将智能纳入通信系统设计,以最快和最可靠的方式提取和传递与任务相关的信息是非常有必要的。
但是什么是语义?这是一个有争议的话题。
1938年,Morris将语言分为三类:
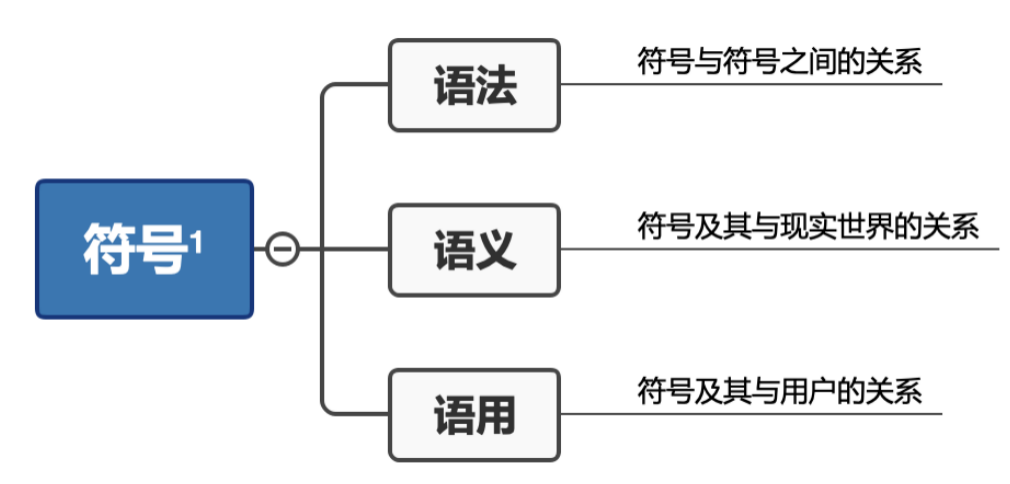
语义学建立在句法的基础上,其主要目标是理解符号与其所指称的对象之间的关系。
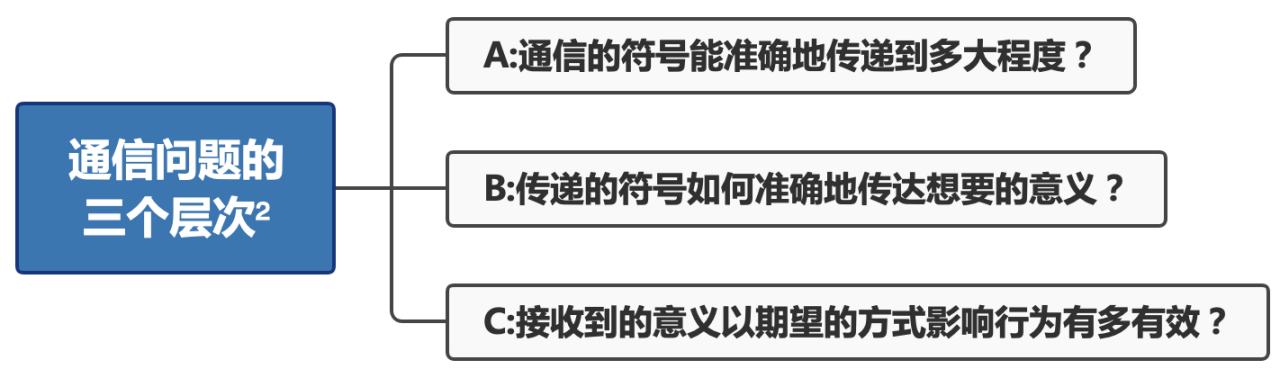
Weaver由此提出了通信问题的三个层次:
语义信息度量
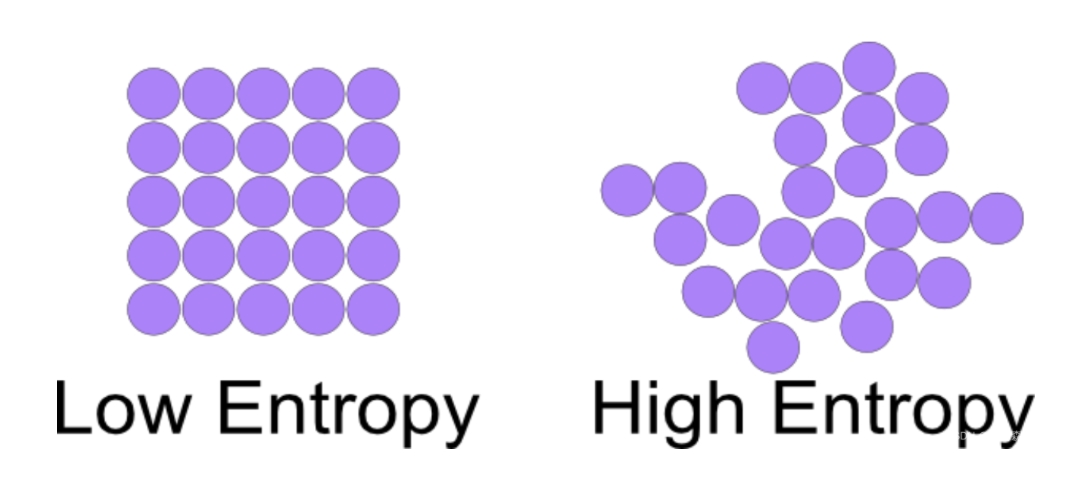
语义熵是语义平均水平的度量,熵在物理学中被用来衡量一个系统的混乱程度,在语义学中是衡量一个句子的不确定程度。
1952年, Carnap and Bar-Hillel首先阐述了在给定的语言系统中句子的语义熵的概念,并提供了一种测量方法:$$ H(s,e)=-logc(s,e) $$ 其中c(s, e)是句子s在证据e上的确认程度,表示为$$c(s,e) = \frac{m(e,s)}{m(e)}$$\(m(e,s)\)是s在e上的逻辑概率。这代表了在证据e上,m(e,s)越大,也就是e对消除s不确定性的帮助越大,那么\(logc(s,e)\)越大,加上负号后整个系统的熵越小,也就是混乱程度越小。但Carnap and Bar-Hillel由此提出了语义悖论——这会将最高的信息分配给了矛盾的句子。
2019年Venhuizen等人根据语言的世界结构(即潜在的背景知识)而不是语言的概率结构的语言理解模型阐述了语义熵

除了上述语言系统外,面向智能任务的语义熵也得到了研究。1997年Melamed提出了一种利用平行文本语料库中词的翻译分布来度量翻译任务中语义熵的信息论方法,每个单词w的语义熵为
2020年Liu通过引入公理化模糊集理论中的隶属度定义了语义熵

2020年,Chattopadhyay提出一个信息论框架来量化任何任务和任何类型信源的语义信息。
语义熵被定义为关于数据S的语义查询的最小数目,其答案足以预测任务V

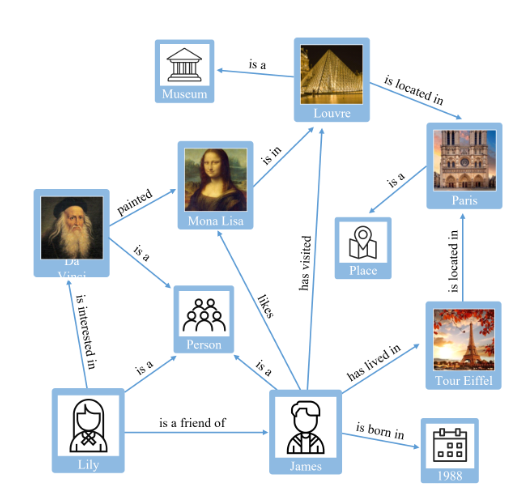
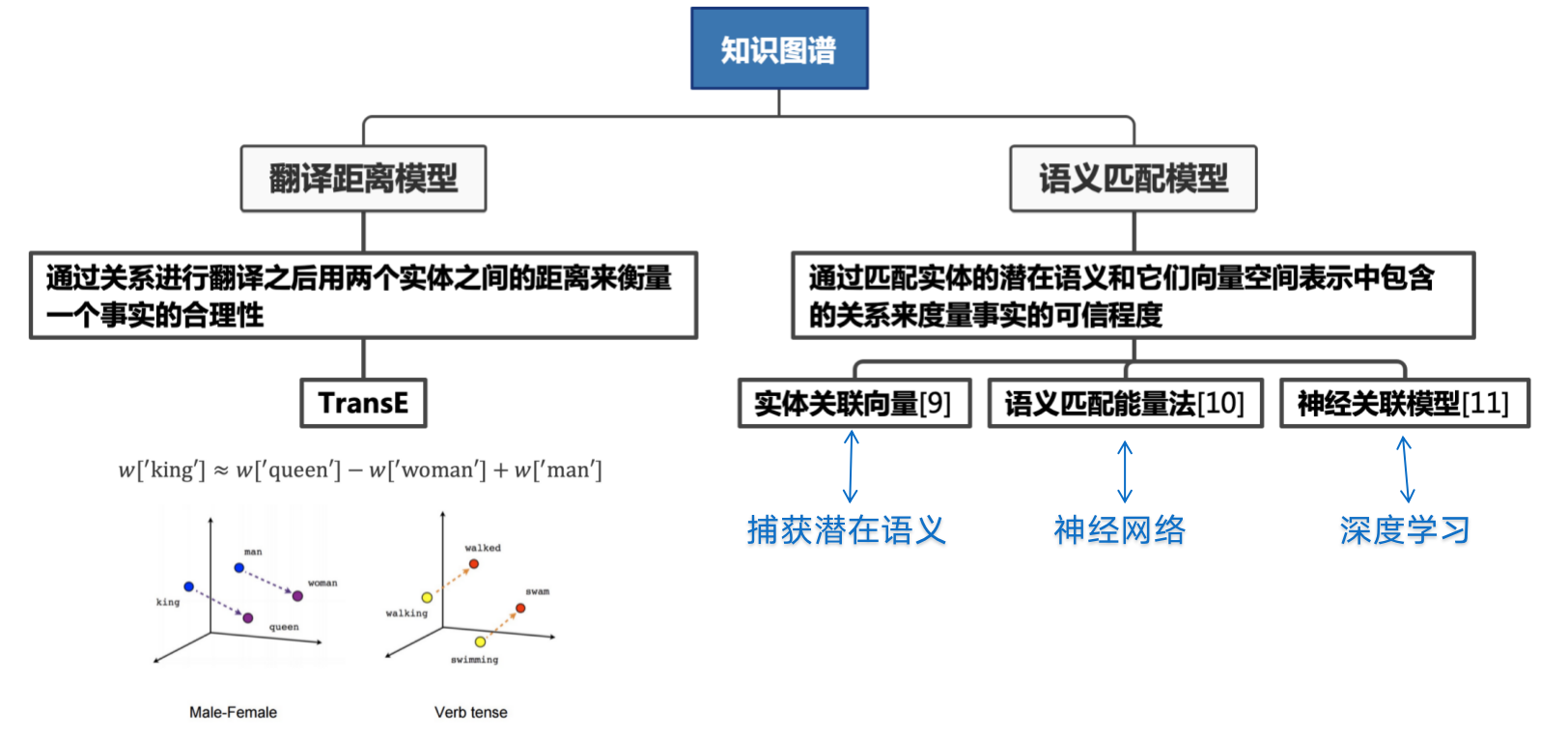
知识图谱
知识可以被定义为将有助于理解和得出结论的可用信息连接起来的能力,而知识图谱的概念是为了使这种理解成为可能而出现的信息网络
机器学习在语义通信的应用
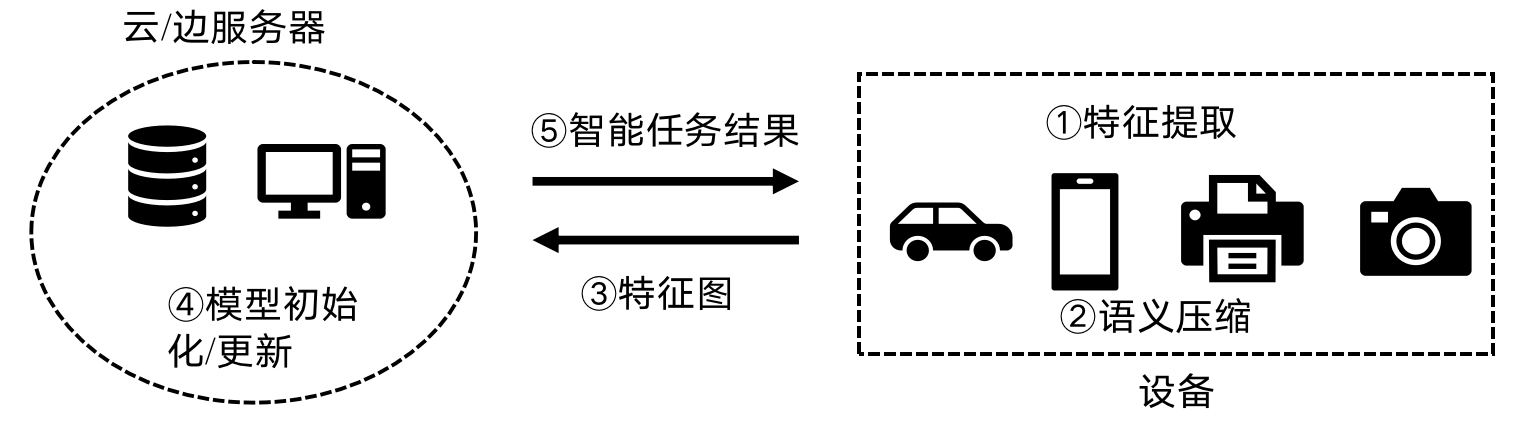

- 解决办法
- 1、在编码器处估计远程源<训练模型>
- 2、在速率受限信道上以最高质量将模型传送给解码器<压缩模型>
补充:压缩模型包括参数剪枝、量化、低秩分解 和知识蒸馏等等。
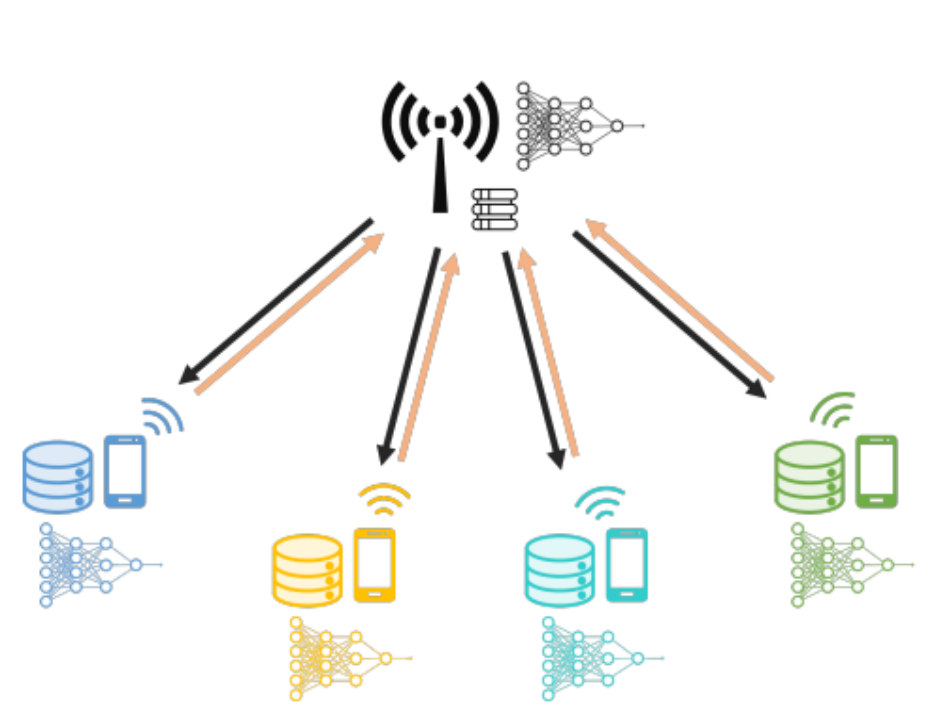
在远程模型训练中,一种更常见的场景是分布式训练,多个节点各自拥有自己的本地数据集,通过与远程参数服务器进行通信或相互通信来训练模型。
剩下的慢慢更TAT

 浙公网安备 33010602011771号
浙公网安备 33010602011771号