Kafka详解与总结(五)
Kafka持久化
1. 概述
Kafka大量依赖文件系统去存储和缓存消息。对于硬盘有个传统的观念是硬盘总是很慢,这使很多人怀疑基于文件系统的架构能否提供优异的性能。实际上硬盘的快慢完全取决于使用它的方式。设计良好的硬盘架构可以和内存一样快。
在6块7200转的SATA RAID-5磁盘阵列的线性写速度差不多是600MB/s,但是随即写的速度却是100k/s,差了差不多6000倍。现在的操作系统提供了预读取和后写入的技术。实际上发现线性的访问磁盘,很多时候比随机的内存访问快得多。
为了提高性能,现代操作系统往往使用内存作为磁盘的缓存,现代操作系统乐于把所有空闲内存用作磁盘缓存,虽然这可能在缓存回收和重新分配时牺牲一些性能。所有的磁盘读写操作都会经过这个缓存,这不太可能被绕开除非直接使用I/O。所以虽然每个程序都在自己的线程里只缓存了一份数据,但在操作系统的缓存里还有一份,这等于存了两份数据。
基于jvm内存有以下缺点:
- Java对象占用空间是非常大的,差不多是要存储的数据的两倍甚至更高。
- 随着堆中数据量的增加,垃圾回收回变的越来越困难,而且可能导致错误
基于以上分析,如果把数据缓存在内存里,因为需要存储两份,不得不使用两倍的内存空间,Kafka基于JVM,又不得不将空间再次加倍,再加上要避免GC带来的性能影响,在一个32G内存的机器上,不得不使用到28-30G的内存空间。并且当系统重启的时候,又必须要将数据刷到内存中( 10GB 内存差不多要用10分钟),就算使用冷刷新(不是一次性刷进内存,而是在使用数据的时候没有就刷到内存)也会导致最初的时候新能非常慢。
基于操作系统的文件系统来设计有以下好处:
- 可以通过os的pagecache来有效利用主内存空间,由于数据紧凑,可以cache大量数据,并且没有gc的压力
- 即使服务重启,缓存中的数据也是热的(不需要预热)。而基于进程的缓存,需要程序进行预热,而且会消耗很长的时间。(10G大概需要10分钟)
- 大大简化了代码。因为在缓存和文件系统之间保持一致性的所有逻辑都在OS中。以上建议和设计使得代码实现起来十分简单,不需要尽力想办法去维护内存中的数据,数据会立即写入磁盘。
总的来说,Kafka不会保持尽可能多的内容在内存空间,而是尽可能把内容直接写入到磁盘。所有的数据都及时的以持久化日志的方式写入到文件系统,而不必要把内存中的内容刷新到磁盘中。
2. 日志数据持久化特性
写操作:通过将数据追加到文件中实现
读操作:读的时候从文件中读就好了
3. 优势
- 读操作不会阻塞写操作和其他操作(因为读和写都是追加的形式,都是顺序的,不会乱,所以不会发生阻塞),数据大小不对性能产生影响;
- 没有容量限制(相对于内存来说)的硬盘空间建立消息系统;
- 线性访问磁盘,速度快,可以保存任意一段时间!
4. 持久化原理
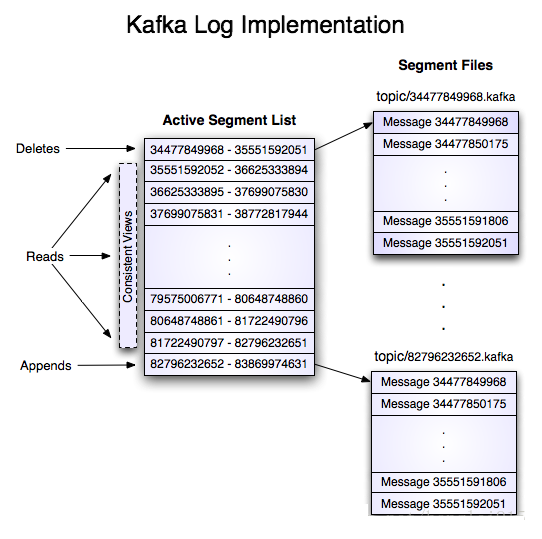
Topic在逻辑上可以被认为是一个queue。每条消费都必须指定它的topic,可以简单理解为必须指明把这条消息放进哪个queue里。为了使得Kafka的吞吐率可以水平扩展,物理上把topic分成一个或多个partition,每个partition在物理上对应一个文件夹,该文件夹下存储这个partition的所有消息和索引文件。

每个日志文件都是“log entries”序列,每一个log entry包含一个4字节整型数(值为N),其后跟N个字节的消息体。每条消息都有一个当前partition下唯一的64字节的offset,它指明了这条消息的起始位置。磁盘上存储的消息格式如下:
消息长度: 4 bytes (value: 1 + 4 + n)
版本号: 1 byte
CRC校验码: 4 bytes
具体的消息: n bytes
这个“log entries”并非由一个文件构成,而是分成多个segment,每个segment名为该segment第一条消息的offset和“.kafka”组成。另外会有一个索引文件,它标明了每个segment下包含的log entry的offset范围,如下图所示:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号