Shell——awk文本和数据处理编程语言
一、awk工作原理
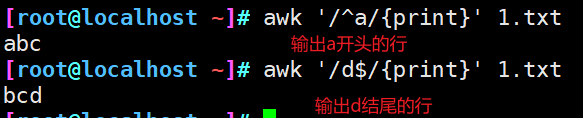
逐行读取文本,默认以空格或tab键为分隔符进行分隔,将分隔所得的各个字段保存到内建变量中,并按模式或者条件执行编辑命令。
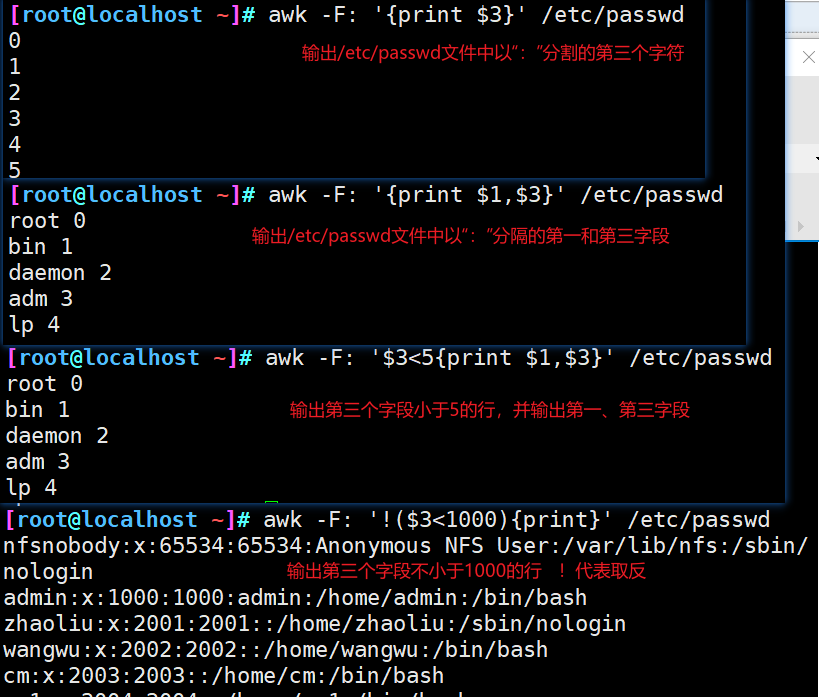
sed命令常用于一整行的处理,而awk比较倾向于将一行分成多个“字段”然后再进行处理。awk信息的读入也是逐行读取的,执行结果可以通过print的功能将字段数据打印显示。在使用awk命令的过程中,可以使用逻辑操作符“&&”表示“与”、“||”表示“或”、“!”表示“非”;还可以进行简单的数学运算,如+、-、*、/、^分别表示加、减、诚、除、取余和乘方。
二、命令格式
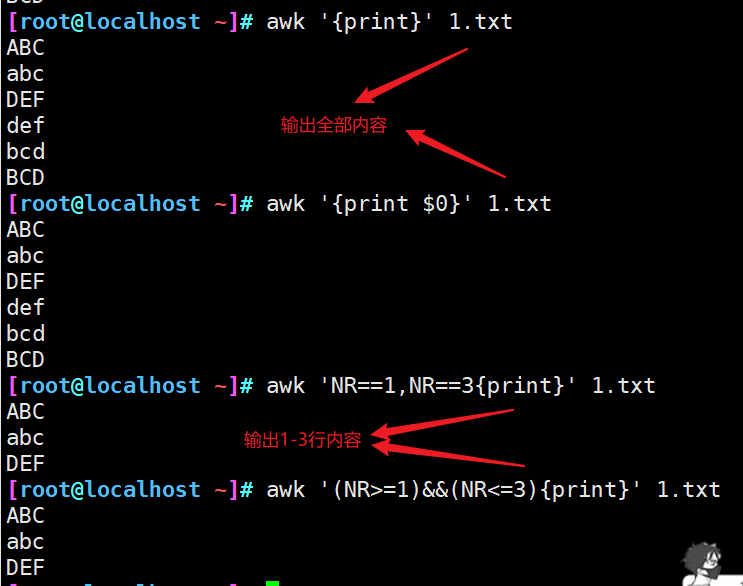
awk 选项 '模式或条件(操作)' 文件1 文件2 … awk -f 脚本文件 文件1 文件2 …
awk后面接两个单引号并加上大括号{ }来设置想要对数据进行的处理操作,awk可以处理后续接的文件,也可以读取来自前个命令的标准输,但如果awk主要是处理每一行的字段内的数据时,默认的字段分隔符为“空格键”或“Tab键”
1、常见的内建变量(可直接使用)
FS∶ 列分割符。指定每行文本的字段分隔符,默认为空格或制表位。与"-F"作用相同
NF∶ 当前处理的行的字段个数。
NR∶ 当前处理的行的行号(序数)。
$0∶当前处理的行的整行内容。
$n∶ 当前处理行的第n个字段(第n列)。
FILENAME∶ 被处理的文件名。
RS∶ 行分隔符。awk从文件上读取资料时,将根据RS的定义把资料切割成许多条记录,而awk一次仅读入一条记录,以进行处理。预设值是’\n’
FNR:awk当前读取的记录数,其变量值小于等于NR(比如当读取第二个文件时,FNR是从0开始重新计数,而NR不会)。
NR==FNR:用于在读取两个或两个以上的文件时,判断是不是在读取第一个文件。

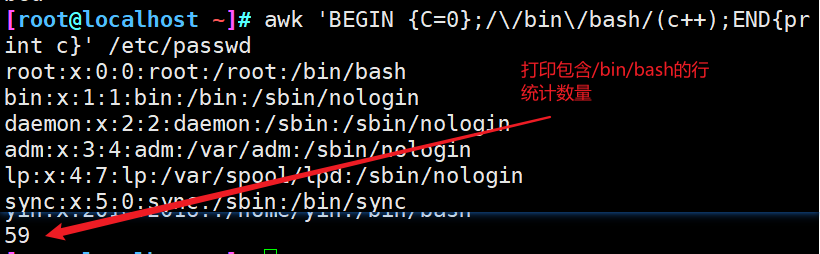
BEGIN模式表示,在处理指定的文本之前,需要先执行BEGIN模式中指定的动作;
awk再处理指定的文本,之后再执行END模式中指定的动作;
END{ } 语句块中,往往会放入打印结果等语句。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号