Trie的应用及拼写检查器的优化
2011-12-29 22:11 htc开发 阅读(270) 评论(0) 收藏 举报之前实现的拼写检查器,是用Hash表来保存语言模型(Language Model)。每个单词插入到Hash表时都要先计算一个Hashcode值来作为Id。因此插入一个单词到Hash表(不冲突的情况下)与查询一个单词的效率都是O(len),其中len是单词的长度。我们也可以用一种叫Trie的树形结构来保存语言模型。
Trie的结构非常简单,举个简单的例子,对于下面这些单词:
an, ant, all, allot, alloy, aloe, are, ate, be
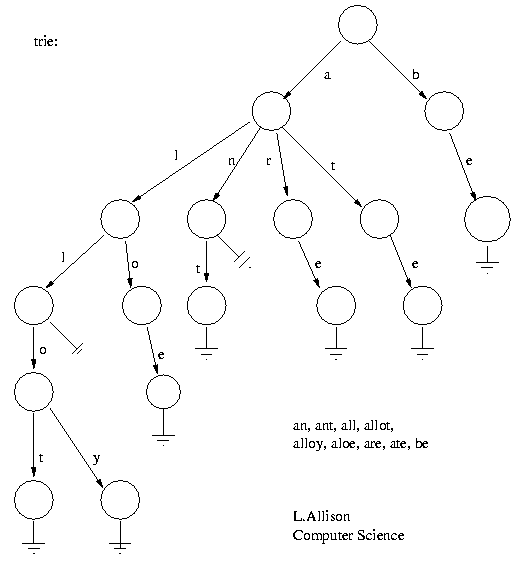
我们可以构建出这样一个Trie树,每条支路都代表一个字母,由根节点出发到叶子节点所经过的路径上的字母就组成一个单词。其中,根节点不包含字母。Trie的构建和查询过程都很简单。拿到一个单词,我们可以从单词第一个字符遍历到最后一个,同时从Trie树的根节点开始,发现当前字符的节点不存在就建出来并添加到当前节点的孩子节点列表中。然后把这个孩子节点设为当前节点,开始继续处理下一个字符。
class TrieNode
{
Map<Character, TrieNode> subNodeMap = new HashMap<Character,
TrieNode>();
char character;
boolean isWord;
double frequency;
public void add(String
word) {
TrieNode node = this; //
Assume this node is root
for (char c
: word.toCharArray()) {
TrieNode subNode = node.subNodeMap.get(c);
if (subNode
== null) {
subNode = new TrieNode();
subNode.character =
c;
node.subNodeMap.put(c,
subNode);
}
node = subNode;
}
if (!node.isWord)
node.isWord = true;
node.frequency++;
}
}
其中isWord是代表从根节点遍历到此节点是不是一个单词,frequence是计算这个单词出现概率用的。
查询的过程也非常简单,拿到一个单词,从根节点遍历到最后一个字符对应的节点就可以查到这个单词的统计概率了。
那这样一个看似很简单的数据结构是怎样优化我们的拼写检查器呢?如果单看一次单词查询,Trie也是要循环len(单词长度)次才能查到的。但是在拼写检查器的第3步中,我们产生了很多近似的编辑距离(Edit Distance)为1和2的单词。然后去掉这些单词中在语言模型里实际不存在的,然后在查找它们的概率。对于这些近似的单词,我们完全可以用几次遍历Trie就去掉实际不存在的单词,并得到剩下单词的概率,从而避免一次又一次的效率为O(len)的Hashcode值计算(总的效率是O(nlen))。
举例来说,用户输入thew时,编辑距离为1的替换字母产生的单词会有:
ahew, bhew, chew, ... zhew
taew, tbew, tcew, ... tzew
thaw, thbw, thcw, ... thzw
thea, theb, thec, ... thez
对于后三行都是由t开头的单词可以通过一次Trie遍历来筛选,并得到有效单词的概率。如果语言模型很大的话,这将是很大的效率提升。
下面来看一个Trie树的简单应用,类似搜索引擎输入框的输入提示。当用户输入单词的开头几个字母时,提示用户一些以这些字母开头并比较热门的单词。语言模型跟之前的拼写检查器一样,都以big.txt为样本统计单词概率。这个小工具核心方法有两个:构建Trie树和单词的前缀搜索。来看具体代码。
public class TrieTree {
public static void main(String[]
args) throws Exception {
TrieNode root = new TrieNode();
root.add("hello");
root.add("high");
root.add("height");
root.add("hey");
root.add("what");
root.iterateDeepFirst(new Visitor()
{
@Override
public void visit(String
word, TrieNode node) {
if (node.isWord)
System.out.println(word);
}
});
System.out.println("Words
with prefix [h]: " + root.getByPrefix("h",
5));
System.out.println("Words
with prefix [he]: " + root.getByPrefix("he",
5));
System.out.println("Words
with prefix [heig]: " + root.getByPrefix("heig",
5));
System.out.println("Words
with prefix [w]: " + root.getByPrefix("w",
5));
long startTime
= System.currentTimeMillis();
root = buildTrieFromFile("big.txt");
System.out.printf("Build
trie tree cost: %.3f second(s).\n",
(System.currentTimeMillis() - startTime) / 1000D);
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
String input;
while ((input
= reader.readLine()) != null) {
input = input.trim().toLowerCase();
if ("bye".equals(input))
break;
startTime = System.currentTimeMillis();
System.out.printf("You
mean %s. Cost %.3f second(s).\n",
root.getByPrefix(input, 5).toString(),
(System.currentTimeMillis() - startTime) / 1000D);
}
}
private static TrieNode
buildTrieFromFile(String sample) throws IOException
{
BufferedReader reader = new BufferedReader(new FileReader(sample));
Pattern pattern = Pattern.compile("[a-zA-Z]+");
TrieNode root = new TrieNode();
int totalCnt
= 0;
String line;
while ((line
= reader.readLine()) != null) {
String[] words = line.split("
");
for (String
word : words) {
if (pattern.matcher(word).matches())
{
word = word.toLowerCase();
root.add(word);
totalCnt++;
}
}
}
reader.close();
final int finalTotalCnt
= totalCnt;
root.iterateDeepFirst(new Visitor()
{
@Override
public void visit(String
word, TrieNode node) {
if (node.isWord)
node.frequency /=
finalTotalCnt;
}
});
return root;
}
}
class TrieNode {
Map<Character, TrieNode> subNodeMap = new HashMap<Character,
TrieNode>();
char character;
boolean isWord;
double frequency;
public void add(String
word) {
TrieNode node = this; //
Assume this node is root
for (char c
: word.toCharArray()) {
TrieNode subNode = node.subNodeMap.get(c);
if (subNode
== null) {
subNode = new TrieNode();
subNode.character =
c;
node.subNodeMap.put(c,
subNode);
}
node = subNode;
}
if (!node.isWord)
node.isWord = true;
node.frequency++;
}
public Collection<String>
getByPrefix(String prefix, int topN)
{
TrieNode node = this; //
Assume this node is root
for (char c
: prefix.toCharArray()) {
node = node.subNodeMap.get(c);
if (node
== null)
return Collections.emptyList();
}
// Only remain topN most frequent words
final Map<String,
Double> wordFreqMap = new HashMap<String,
Double>();
node.iterateDeepFirst(new Visitor()
{
@Override
public void visit(String
word, TrieNode node) {
if (node.isWord)
wordFreqMap.put(word, node.frequency);
}
}, prefix);
List<String> words = new LinkedList<String>(wordFreqMap.keySet());
Collections.sort(words, new Comparator<String>()
{
@Override
public int compare(String
word1, String word2) {
return wordFreqMap.get(word2).compareTo(wordFreqMap.get(word1));
}
});
return words.size()
> topN ? words.subList(0, topN) : words;
}
/**
* Recursive wrapper method.
* @param visitor
* @param prefix
*/
public void iterateDeepFirst(Visitor
visitor, String prefix) {
doIterateDeepFirst(visitor, prefix);
}
public void iterateDeepFirst(Visitor
visitor) {
doIterateDeepFirst(visitor, "");
}
public void doIterateDeepFirst(Visitor
visitor, String prefix) {
// Iterate child first, which will deep
and left-most.
String newPrefix;
for (TrieNode
subNode : subNodeMap.values()) {
newPrefix = prefix + subNode.character;
subNode.doIterateDeepFirst(visitor, newPrefix);
}
// Visit current node at last
visitor.visit(prefix, this);
}
interface Visitor
{
void visit(String
word, TrieNode node);
}
}
main方法中首先是一个简单的小例子,然后是输入提示的主循环。buildTrieFromFile方法简单地调用root节点的add方法,最后计算概率。getByPrefix方法首先遍历到前缀最后一个字符的节点上,然后递归查找该节点的所有子节点,如果子节点是一个单词就保存下来。最后根据它们的概率只保留最热门的五个。
在遍历Trie树时采用深度优先遍历,并结合Visitor(访问者模式)。这样代码会比较清晰,不同的Visitor可以完成不同的功能,跟Trie树代码分离开。当TrieNode有多种类型时,TrieNode子类们与Visitor子类们将产生两次多态调用,Visitor模式将会非常灵活。详情就参考各种设计模式书籍,如《Java与模式》。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号