
Django学习 之 HTTP与WEB为Django做准备
一.HTTP
1.HTTP 简介
HTTP协议(HyperText Transfer Protocol,超文本传输协议)是因特网上应用最为广泛的一种网络传输协议,所有的WWW文件都必须遵守这个标准。
HTTP是一个基于TCP/IP通信协议来传递数据(HTML 文件, 图片文件, 查询结果等)。
2.HTTP 工作原理
HTTP是基于客户/服务器模式,且面向连接的。典型的HTTP事务处理有如下的过程: [8]
(1)客户与服务器建立连接;
(2)客户向服务器提出请求;
(3)服务器接受请求,并根据请求返回相应的文件作为应答;
(4)客户与服务器关闭连接。
客户与服务器之间的HTTP连接是一种一次性连接,它限制每次连接只处理一个请求,当服务器返回本次请求的应答后便立即关闭连接,
下次请求再重新建立连接。这种一次性连接主要考虑到WWW服务器面向的是Internet中成干上万个用户,且只能提供有限个连接,
故服务器不会让一个连接处于等待状态,及时地释放连接可以大大提高服务器的执行效率。
Web服务器有:Apache服务器,IIS服务器(Internet Information Services)等。
HTTP默认端口号为80,但是你也可以改为8080或者其他端口。
HTTP三点注意事项:
(1)HTTP是无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
(2)HTTP是媒体独立的:这意味着,只要客户端和服务器知道如何处理的数据内容,任何类型的数据都可以通过HTTP发送。客户端以及服务器指定使用适合的MIME-type内容类型。
(3)HTTP是无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。
以下图表展示了HTTP协议通信流程:
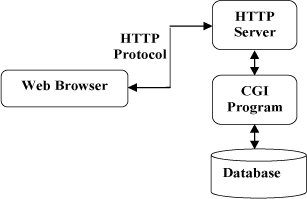
3.HTTP 消息结构
HTTP是基于客户端/服务端(C/S)的架构模型,通过一个可靠的链接来交换信息,是一个无状态的请求/响应协议。
一个HTTP"客户端"是一个应用程序(Web浏览器或其他任何客户端),通过连接到服务器达到向服务器发送一个或多个HTTP的请求的目的。
一个HTTP"服务器"同样也是一个应用程序(通常是一个Web服务,如Apache Web服务器或IIS服务器等),通过接收客户端的请求并向客户端发送HTTP响应数据。
HTTP使用统一资源标识符(Uniform Resource Identifiers, URI)来传输数据和建立连接。
一旦建立连接后,数据消息就通过类似Internet邮件所使用的格式[RFC5322]和多用途Internet邮件扩展(MIME)[RFC2045]来传送。
(1)客户端请求消息
客户端发送一个HTTP请求到服务器的请求消息包括以下格式:请求行(request line)、请求头部(header)、空行和请求数据四个部分组成,下图给出了请求报文的一般格式。
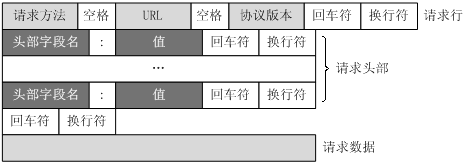
(2)服务器响应消息
HTTP响应也由四个部分组成,分别是:状态行、消息报头、空行和响应正文。

(3)请求实例
下面实例是一点典型的使用GET来传递数据的实例:
客户端请求:
GET / HTTP/1.1
Host: 127.0.0.1:8888
Connection: keep-alive\r\nCache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.108 Safari/537.36
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
'
HTTP默认的请求方法就是GET
* 没有请求体
* 数据量有限制!
* GET请求数据会暴露在浏览器的地址栏中
GET请求常用的操作:
1. 在浏览器的地址栏中直接给出URL,那么就一定是GET请求
2. 点击页面上的超链接也一定是GET请求
3. 提交表单时,表单默认使用GET请求,但可以设置为POST
请求头:
1、Host
请求的web服务器域名地址
2、User-Agent
HTTP客户端运行的浏览器类型的详细信息。通过该头部信息,web服务器可以判断出http请求的客户端的浏览器的类型。
3、Accept
指定客户端能够接收的内容类型,内容类型的先后次序表示客户都接收的先后次序
4、Accept-Lanuage
指定HTTP客户端浏览器用来展示返回信息优先选择的语言
5、Accept-Encoding
指定客户端浏览器可以支持的web服务器返回内容压缩编码类型。表示允许服务器在将输出内容发送到客户端以前进行压缩,以节约带宽。
而这里设置的就是客户端浏览器所能够支持的返回压缩格式。
6、Accept-Charset
HTTP客户端浏览器可以接受的字符编码集
7、Content-Type
显示此HTTP请求提交的内容类型。一般只有post提交时才需要设置该属性
有关Content-Type属性值有如下两种编码类型:
(1)“application/x-www-form-urlencoded”: 表单数据向服务器提交时所采用的编码类型,默认的缺省值就是“application/x-www-form-urlencoded”。
然而,在向服务器发送大量的文本、包含非ASCII字符的文本或二进制数据时这种编码方式效率很低。
(2)“multipart/form-data”: 在文件上载时,所使用的编码类型应当是“multipart/form-data”,它既可以发送文本数据,也支持二进制数据上载。
当提交为表单数据时,可以使用“application/x-www-form-urlencoded”;当提交的是文件时,就需要使用“multipart/form-data”编码类型。
8、Keep-Alive
表示是否需要持久连接。如果web服务器端看到这里的值为“Keep-Alive”,或者看到请求使用的是HTTP 1.1(HTTP 1.1默认进行持久连接),它就可以利用持久连接的优点
服务器响应:
Request URL: http://127.0.0.1:8888/favicon.ico
Request Method: GET
Status Code: 200 OK
Remote Address: 127.0.0.1:8888
Referrer Policy: no-referrer-when-downgrade
Content-Type: text/html;charset=utf-8
Referer: http://127.0.0.1:8888/
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.108 Safari/537.36
输出结果:

响应分为:
第一部分:状态行,由HTTP协议版本号, 状态码, 状态消息 三部分组成。
第一行为状态行,(HTTP/1.1)表明HTTP版本为1.1版本,状态码为200,状态消息为(ok)
第二部分:消息报头,用来说明客户端要使用的一些附加信息
第二行和第三行为消息报头,
Date:生成响应的日期和时间;Content-Type:指定了MIME类型的HTML(text/html),编码类型是UTF-8
第三部分:空行,消息报头后面的空行是必须的
第四部分:响应正文,服务器返回给客户端的文本信息。
空行后面的html部分为响应正文。
4.HTTP 请求方法
根据 HTTP 标准,HTTP 请求可以使用多种请求方法。
HTTP1.0 定义了三种请求方法: GET, POST 和 HEAD方法。
HTTP1.1 新增了五种请求方法:OPTIONS、PUT、PATCH、DELETE、TRACE 和 CONNECT 方法。
HTTP 协议的 8 种请求类型介绍:
HTTP 协议中共定义了八种方法或者叫“动作”来表明对 Request-URI 指定的资源的不同操作方式,具体介绍如下:
OPTIONS:返回服务器针对特定资源所支持的HTTP请求方法。也可以利用向Web服务器发送'*'的请求来测试服务器的功能性。
HEAD:向服务器索要与GET请求相一致的响应,只不过响应体将不会被返回。这一方法可以在不必传输整个响应内容的情况下,就可以获取包含在响应消息头中的元信息。
GET:向特定的资源发出请求。
POST:向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的创建和/或已有资源的修改。
PUT:向指定资源位置上传其最新内容。
DELETE:请求服务器删除 Request-URI 所标识的资源。
TRACE:回显服务器收到的请求,主要用于测试或诊断。
CONNECT:HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器。
虽然 HTTP 的请求方式有 8 种,但是我们在实际应用中常用的也就是 get 和 post,其他请求方式也都可以通过这两种方式间接的来实现。
5.HTTP 响应头信息
HTTP请求头提供了关于请求,响应或者其他的发送实体的信息。
Allow
服务器支持哪些请求方法(如GET、POST等)。
Content-Encoding
文档的编码(Encode)方法。只有在解码之后才可以得到Content-Type头指定的内容类型。利用gzip压缩文档能够显著地减少HTML文档的下载时间。Java的GZIPOutputStream可以很方便地进行gzip压缩,但只有Unix上的Netscape和Windows上的IE 4、IE 5才支持它。因此,Servlet应该通过查看Accept-Encoding头(即request.getHeader("Accept-Encoding"))检查浏览器是否支持gzip,为支持gzip的浏览器返回经gzip压缩的HTML页面,为其他浏览器返回普通页面。
Content-Length
表示内容长度。只有当浏览器使用持久HTTP连接时才需要这个数据。如果你想要利用持久连接的优势,可以把输出文档写入 ByteArrayOutputStream,完成后查看其大小,然后把该值放入Content-Length头,最后通过byteArrayStream.writeTo(response.getOutputStream()发送内容。
Content-Type
表示后面的文档属于什么MIME类型。Servlet默认为text/plain,但通常需要显式地指定为text/html。由于经常要设置Content-Type,因此HttpServletResponse提供了一个专用的方法setContentType。
Date
当前的GMT时间。你可以用setDateHeader来设置这个头以避免转换时间格式的麻烦。
Expires
应该在什么时候认为文档已经过期,从而不再缓存它?
Last-Modified
文档的最后改动时间。客户可以通过If-Modified-Since请求头提供一个日期,该请求将被视为一个条件GET,只有改动时间迟于指定时间的文档才会返回,否则返回一个304(Not Modified)状态。Last-Modified也可用setDateHeader方法来设置。
Location
表示客户应当到哪里去提取文档。Location通常不是直接设置的,而是通过HttpServletResponse的sendRedirect方法,该方法同时设置状态代码为302。
Refresh
表示浏览器应该在多少时间之后刷新文档,以秒计。除了刷新当前文档之外,你还可以通过setHeader("Refresh", "5; URL=http://host/path")让浏览器读取指定的页面。
注意这种功能通常是通过设置HTML页面HEAD区的<META HTTP-EQUIV="Refresh" CONTENT="5;URL=http://host/path">实现,这是因为,自动刷新或重定向对于那些不能使用CGI或Servlet的HTML编写者十分重要。但是,对于Servlet来说,直接设置Refresh头更加方便。
注意Refresh的意义是"N秒之后刷新本页面或访问指定页面",而不是"每隔N秒刷新本页面或访问指定页面"。因此,连续刷新要求每次都发送一个Refresh头,而发送204状态代码则可以阻止浏览器继续刷新,不管是使用Refresh头还是<META HTTP-EQUIV="Refresh" ...>。
注意Refresh头不属于HTTP 1.1正式规范的一部分,而是一个扩展,但Netscape和IE都支持它。
Server
服务器名字。Servlet一般不设置这个值,而是由Web服务器自己设置。
Set-Cookie
设置和页面关联的Cookie。Servlet不应使用response.setHeader("Set-Cookie", ...),而是应使用HttpServletResponse提供的专用方法addCookie。参见下文有关Cookie设置的讨论。
WWW-Authenticate
客户应该在Authorization头中提供什么类型的授权信息?在包含401(Unauthorized)状态行的应答中这个头是必需的。例如,response.setHeader("WWW-Authenticate", "BASIC realm=\"executives\"")。
注意Servlet一般不进行这方面的处理,而是让Web服务器的专门机制来控制受密码保护页面的访问(例如.htaccess)。
6.HTTP状态码
当浏览者访问一个网页时,浏览者的浏览器会向网页所在服务器发出请求。当浏览器接收并显示网页前,此网页所在的服务器会返回一个包含HTTP状态码的信息头(server header)用以响应浏览器的请求。
HTTP状态码的英文为HTTP Status Code。
下面是常见的HTTP状态码:
200 OK //客户端请求成功
400 Bad Request //客户端请求有语法错误,不能被服务器所理解
401 Unauthorized //请求未经授权,这个状态代码必须和
//WWW-Authenticate报头域一起使用
403 Forbidden //服务器收到请求,但是拒绝提供服务
404 Not Found //请求资源不存在,eg:输入了错误的URL
500 Internal Server Error //服务器发生不可预期的错误
503 Server Unavailable //服务器当前不能处理客户端的请求,一段时间后可能恢复正常
7.HTTP状态码分类
HTTP状态码由三个十进制数字组成,第一个十进制数字定义了状态码的类型,后两个数字没有分类的作用。HTTP状态码共分为5种类型:
1** 信息,服务器收到请求,需要请求者继续执行操作
2** 成功,操作被成功接收并处理
3** 重定向,需要进一步的操作以完成请求
4** 客户端错误,请求包含语法错误或无法完成请求
5** 服务器错误,服务器在处理请求的过程中发生了错误
更多详细状态码解释请见:点我
8.HTTP协议特性
(1)基于TCP/IP协议
http协议是基于TCP/IP协议之上的应用层协议。
(2)基于请求---响应模式
HTTP协议规定,请求从客户端发出,最后服务器端响应 该请求并返回。换句话说,肯定是先从客户端开始建立通信的,服务器端在没有 接收到请求之前不会发送响应。
(3)无状态保存
HTTP是一种不保存状态,即无状态(stateless)协议。HTTP协议 自身不对请求和响应之间的通信状态进行保存。也就是说在HTTP这个 级别,协议对于发送过的请求或响应都不做持久化处理。
使用HTTP协议,每当有新的请求发送时,就会有对应的新响应产 生。协议本身并不保留之前一切的请求或响应报文的信息。这是为了更快地处理大量事务,确保协议的可伸缩性,而特意把HTTP协议设计成 如此简单的。
可是,随着Web的不断发展,因无状态而导致业务处理变得棘手 的情况增多了。比如,用户登录到一家购物网站,即使他跳转到该站的 其他页面后,也需要能继续保持登录状态。针对这个实例,网站为了能 够掌握是谁送出的请求,需要保存用户的状态。HTTP/1.1虽然是无状态协议,但为了实现期望的保持状态功能, 于是引入了Cookie技术。有了Cookie再用HTTP协议通信,就可以管 理状态了。有关Cookie的详细内容后面会详细讲解。
(4)无连接
无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
二.web应用与web框架
1.web应用
应用程序有两种模式C/S、B/S:
C/S(Client/Server)是客户端/服务器端程序,也就是说这类程序一般独立运行。
B/S(Browser/Server)就是浏览器端/服务器端应用程序,这类应用程序一般借助谷歌,火狐等浏览器来运行。
Web应用程序一般是B/S模式。Web应用程序首先是“应用程序”,和用什么程序语言(如:java,python等)编写出来的程序没有什么本质上的不同。在网络编程的意义下,浏览器是一个socket客户端,服务器是一个socket服务端。
基于socket实现一个最简单的web应用程序。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# by hsz
import socket
# 创建socket对象
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 绑定IP和端口
sock.bind(("127.0.0.1", 8888))
# 监听
sock.listen(5)
while True:
conn, addr = sock.accept() # 等待连接
data = conn.recv(1024) # 接收数据
print("请求信息====> %s" % data)
# 发送数据
conn.send("HTTP/1.1 200 OK\r\nContent-Type: text/html;charset=utf-8\r\n\r\n".encode('utf-8'))
conn.send("<h2>hello http</h2>".encode("utf-8"))
conn.close()
2.wsgiref模块
最简单的Web应用就是先把HTML用文件保存好,用一个现成的HTTP服务器软件,接收用户请求,从文件中读取HTML,返回。
如果要动态生成HTML,就需要把上述步骤自己来实现。不过,接受HTTP请求、解析HTTP请求、发送HTTP响应都是苦力活,如果我们自己来写这些底层代码,还没开始写动态HTML呢,就得花个把月去读HTTP规范。
正确的做法是底层代码由专门的服务器软件实现,我们用Python专注于生成HTML文档。因为我们不希望接触到TCP连接、HTTP原始请求和响应格式,所以,需要一个统一的接口协议来实现这样的服务器软件,让我们专心用Python编写Web业务。这个接口就是WSGI:Web Server Gateway Interface。而wsgiref模块就是python基于wsgi协议开发的服务模块。
例:
from wsgiref.simple_server import make_server
def application(environ, start_response):
start_response('200 OK', [('Content-Type', 'text/html')])
return [b'<h1>Hello, web!</h1>']
if __name__ == '__main__':
httpd = make_server('', 8080, application)
print('Serving HTTP on port 8080...')
# 开始监听HTTP请求:
httpd.serve_forever()
即可得到标题:Hello, web!
3.Web框架
Web框架(Web framework)是一种开发框架,用来支持动态网站、网络应用和网络服务的开发。这大多数的web框架提供了一套开发和部署网站的方式,也为web行为提供了一套通用的方法。web框架已经实现了很多功能,开发人员使用框架提供的方法并且完成自己的业务逻辑,就能快速开发web应用了。
浏览器和服务器之间是基于HTTP协议进行通信的。也可以说web框架就是在以上十几行代码基础张扩展出来的,有很多简单方便使用的方法,大大提高了开发的效率。
4.一个Web框架demo
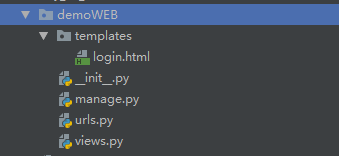
(1)启动文件manage.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# by hsz
from wsgiref.simple_server import make_server
from urls import *
def application(environ, start_response):
start_response('200 OK', [('Content-Type', 'text/html;charset=utf-8')])
path = environ.get("PATH_INFO")
func = None
for item in urlpatterns:
if path == item[0]:
func = item[1]
break
if func:
ret = func(environ)
else:
ret = not_found(environ)
return [ret]
if __name__ == '__main__':
# 请求端口
httpd = make_server('', 8080, application)
print('Serving HTTP on port 8080...')
# 开始监听HTTP请求:
httpd.serve_forever()
(2)urls.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# by hsz
from views import *
urlpatterns = [
("/login/", login),
]
(3)views.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# by hsz
def login(environ):
with open("templates/login.html", "rb") as f:
data = f.read()
return data
def not_found(environ):
ret = b'<h1>404 not found.!!!</h1>'
return ret
(4)templates模板目录(该目录下创建login.html网页)
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title></title>
</head>
<body>
<form action="http://127.0.0.1:8080/login/" method="post">
<p>用户名:<input type="text" name="user"></p>
<p>密码:<input type="password" name="pwd"></p>
<input type="submit">
</form>
</body>
</html>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号