
Python 之并发编程之进程上(基本概念、并行并发、cpu调度、阻塞 )
一: 进程的概念:(Process)
进程就是正在运行的程序,它是操作系统中,资源分配的最小单位.
资源分配:分配的是cpu和内存等物理资源
进程号是进程的唯一标识
同一个程序执行两次之后是两个进程
进程和进程之间的关系: 数据彼此隔离,通过socket通信
二:并行和并发
并发:一个cpu同一时间不停执行多个程序
并行:多个cpu同一时间不停执行多个程序
三:cpu的进程调度方法
# 先来先服务fcfs(first come first server):先来的先执行
# 短作业优先算法:分配的cpu多,先把短的算完
# 时间片轮转算法:每一个任务就执行一个时间片的时间.然后就执行其他的.
# 多级反馈队列算法
越是时间长的,cpu分配的资源越短,优先级靠后
越是时间短的,cpu分配的资源越多
### 进程三状态图
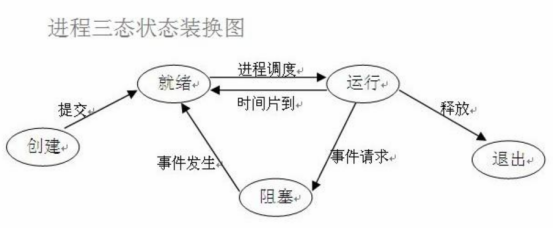
(1)就绪(Ready)状态
只剩下CPU需要执行外,其他所有资源都已分配完毕 称为就绪状态。
(2)执行(Running)状态
cpu开始执行该进程时称为执行状态。
(3)阻塞(Blocked)状态
由于等待某个事件发生而无法执行时,便是阻塞状态,cpu执行其他进程.例如,等待I/O完成input、申请缓冲区不能满足等等。

这三个在下面学习的内容中是一起掺杂在一起的
(1)获取进程号
使用os.getpid() 获取子进程号
使用os.getppid() 获取父进程号
#例:
import os, time # 获取子进程[当前进程]的id号 res1 = os.getpid() print(res1) # 获取父进程的id号 res2 = os.getppid() print(res2) # linux Process 底层利用的是fork来创建进程的,而fork在windows里并不支持.
#如果在编辑器上运行可知,父进程号是不变得,子进程号是改变的,因为父进程号是编辑器运行的进程号,二子进程号是这个程序运行的进程号,程序重新运行子进程重启在启动一个。
(2)进程的基本用法
例:
import os from multiprocessing import Process def func(): print("1.子进程id>>>%s,父进程id>>>%s" %(os.getpid(),os.getppid())) if __name__ == "__main__": print("2.子进程id>>>%s,父进程id>>>%s" % (os.getpid(), os.getppid())) #创建子进程,返回一个进程对象.target是指定要完成的任务,后面接的是函数 p = Process(target = func) # 调用子进程 p.start()
结果是:函数外的父进程号是不变的,子进程号和函数内的父进程号是相同的,而且每次运行进程号是在改变的,函数内的子进程号每次也是改变的。
(3)函数中带有参数
进程的并发要依靠cpu
cpu先执行谁后执行谁,要依靠cpu调度策略
# 无参函数
#例:
from multiprocessing import Process import os def func(): for i in range(1,6): print("2.子进程id>>>%s,父进程id>>>%s" %(os.getpid(),os.getppid())) if __name__ == "__main__": print("1.子进程id>>>%s,父进程id>>>%s" % (os.getpid(),os.getppid())) # 创建子进程 p = Process(target=func) # 调用子进程 p.start() n = 5 for i in range(1,n+1): print("*" * i)
#先打印星星后打印func函数内的循环,因为创建子进程中需要开辟栈帧空间需要时间
效果截图:

# 有参函数
from multiprocessing import Process import os,time def func(n): for i in range(1,n+1): time.sleep(0.5) print("2.子进程id>>>%s,父进程id>>>%s" % (os.getpid(), os.getppid())) if __name__ == "__main__": print("1.子进程id>>>%s,父进程id>>>%s" % (os.getpid(), os.getppid())) n = 5 # 创建子进程 返回进程对象 如果有参数用args 关键字参数执行 # 对应的值是元组,参数塞到元组中,按照次序排列 p = Process(target=func,args=(n,)) p.start() for i in range(1,n+1): time.sleep(0.3) print("*" * i)
# 这时候会造成,星星和func里面打印子进程和父进程的语句相互交错
# 因为子进程开辟栈帧空间的时间极短,所有再哪个不在睡眠时间内先运行哪个进程
效果截图:

(4)进程之间的数据彼此是隔离的
#例:
from multiprocessing import Process count = 99 def func(): global count count +=1 print("我是子进程,count=",count) if __name__ == "__main__": p = Process(target=func) p.start() print("我是主进程,count=",count)
结果输出为:
我是主进程,count= 99
我是子进程,count= 100
(5)多个进程的并发
#例:
# 在程序并发时, 因为cpu的调度策略问题,不一定谁先执行,谁后执行 from multiprocessing import Process import os def func(args): print("args=%s,子进程id号>>>%s, 父进程id号>>>%s" % (args, os.getpid(), os.getppid())) if __name__ == "__main__": for i in range(10): Process(target=func, args=(i,)).start()
运行得到结果如下图:
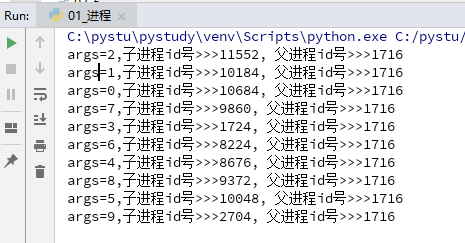
可以看出父进程id号是不变的,子进程id号是变化的,而且子进程开启不是按顺序的是并发的。
(6)子进程和父进程之间的关系
通常情况下,父进程会比子进程速度稍快,但是不绝对
在父进程执行所有代码完毕之后,会默认等待所有子进程执行完毕
然后在彻底的终止程序,为了方便进程的管理
如果不等待,子进程会变成僵尸进程,在后台不停地占用内存和cpu资源
但是本身由于进程太多,并不容易发现
#例:
from multiprocessing import Process import os,time def func(args): print("args=%s,子进程id号>>>%s,父进程id号>>>%s" % (args, os.getpid(), os.getppid())) time.sleep(1) print("args= %s, end" % (args)) if __name__ == "__main__": for i in range(10): Process(target=func,args=(i,)).start() """ Process(target=func,args=(i,)).start() Process(target=func,args=(i,)).start() Process(target=func,args=(i,)).start() Process(target=func,args=(i,)).start() Process(target=func,args=(i,)).start() Process(target=func,args=(i,)).start() .... """ print("*******父进程*******")
运行后的结果为:


可以看出父进程号是不变的,子进程是并发的,父进程的执行语句是最快结束的,因为开启子进程需要时间,而主进程的输出没有阻塞所以最快,从print("args= %s, end" % (args))可以知道,子进程是并发的,因为sleep(1)后,如果是顺序执行的话,输出结果不是这样。
四:同步 异步 / 阻塞 非阻塞
场景在多任务当中
同步:必须等我这件事干完了,你在干,只有一条主线,就是同步
异步:没等我这件事情干完,你就在干了,有两条主线,就是异步
阻塞:比如代码有了input,就是阻塞,必须要输入一个字符串,否则代码不往下执行
非阻塞:没有任何等待,正常代码往下执行.
# 同步阻塞 :效率低,cpu利用不充分
# 异步阻塞 :比如socketserver,可以同时连接多个,但是彼此都有recv
# 同步非阻塞:没有类似input的代码,从上到下执行.默认的正常情况代码
# 异步非阻塞:效率是最高的,cpu过度充分,过度发热
(1)join阻塞基本用法
#例:
from multiprocessing import Process def func(): print("我发送第一封邮件....") if __name__ == "__main__": p = Process(target=func) p.start() # 等待p对象的这个子进程执行完毕之后,在向下执行代码 # join实际上是加了阻塞 p.join() #如果没有join,往往主进程先运行,因为子进程需要开辟栈帧空间相当于加了阻塞 print("发送第十封邮件")
输出结果为:
我发送第一封邮件....
发送第十封邮件
#程序在发送第十封邮件前加了阻塞,是的会先运行子进程结束在运行join之后的语句
(2) 多个子进程通过join 加阻塞,进行同步的控制
例:
from multiprocessing import Process import time def func(index): time.sleep(0.3) print("第%s封邮件已经发送..." % (index)) if __name__ == "__main__": lst = [] for i in range(1,10): p = Process(target=func,args=(i,)) p.start() lst.append(p) # 把列表里面的每一个进程对象去执行join() # 必须等我子进程执行完毕之后了,再向下执行,控制父子进程的同步性 for i in lst: i.join() # 等前9个邮件发送之后了,再发第十个 print("发送第十封邮件")
所以输出结果为:
第3封邮件已经发送...
第2封邮件已经发送...
第1封邮件已经发送...
第5封邮件已经发送...
第9封邮件已经发送...
第6封邮件已经发送...
第4封邮件已经发送...
第7封邮件已经发送...
第8封邮件已经发送...
发送第十封邮件
十个子进程是并发的,所以不一定谁先执行结束,所以不是顺序的。
(3)使用类的方法创建子进程
# (1) 基本语法
可以使用自定义的方式创建子进程,
但是必须继承父类Processs
而且所有的逻辑都必须写在run方法里面
#例:
from multiprocessing import Process import os class MyProcess(Process): # 必须使用叫做run的方法,而且()里面只能是self def run(self): # 写自定义的逻辑 print("子进程id>>>%s, 父进程的id>>>%s" % (os.getpid(), os.getppid())) if __name__ == "__main__": p = MyProcess() p.start() print("主进程:{}".format(os.getpid()))
输出结果为:
主进程:8236
子进程id>>>6412, 父进程的id>>>8236
# (2) 带参数的子进程函数
#例:
from multiprocessing import Process import os class MyProcess(Process): def __init__(self,arg): # 必须调用一下父类的初始化构造方法 super().__init__() self.arg = arg # 必须使用叫做run的方法 def run(self): # 在这里就得获取参数 print("子进程id>>>%s,父进程的id>>>%s" % (os.getpid(),os.getppid())) print(self.arg) if __name__ == "__main__": lst = [] for i in range(1,10): p = MyProcess("参数:%s" % (i)) p.start() lst.append(p) for i in lst: i.join() print("最后执行主进程的这句话...",os.getpid())
运行结果为:
子进程id>>>5964,父进程的id>>>5336
参数:2
子进程id>>>10544,父进程的id>>>5336
参数:3
子进程id>>>11512,父进程的id>>>5336
参数:4
子进程id>>>11160,父进程的id>>>5336
参数:5
子进程id>>>12068,父进程的id>>>5336
参数:1
子进程id>>>5288,父进程的id>>>5336
参数:6
子进程id>>>11380,父进程的id>>>5336
参数:8
子进程id>>>8092,父进程的id>>>5336
参数:7
子进程id>>>7120,父进程的id>>>5336
参数:9
最后执行主进程的这句话... 5336
结果分析:父进程是程序运行的主进程号不变,子进程是并发的所以那个参数先打印是不固定的,然后对每个子进程添加了join阻塞,所以没有全部执行完子进程之前,主进程的运行语句是不打印的,也就是在子进程join后主进程运行语句必须等待子进程全部结束才打印。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号