MySQL索引
MySQL索引
一、MySQL索引介绍
1.1索引是什么?
相当于一本书中的目录。帮助我们快速找到需要内容的页码。
索引可以帮我们快速找到所需要行的数据页码。起到优化查询的功能。
1.2 MySQL索引类型
Btree索引 重点!!!
Rtree索引
Hash索引
Fulltext全文索引
GIS地理位置索引
二、BTree结构
2.1、介绍
二叉树 -----> 平衡二叉树 -----> 平衡树
BTree种类
B-tree
B+Tree 在范围查询方面提供了更好的性能(> < >= <= like)
B*Tree
B-Tree查找结构:
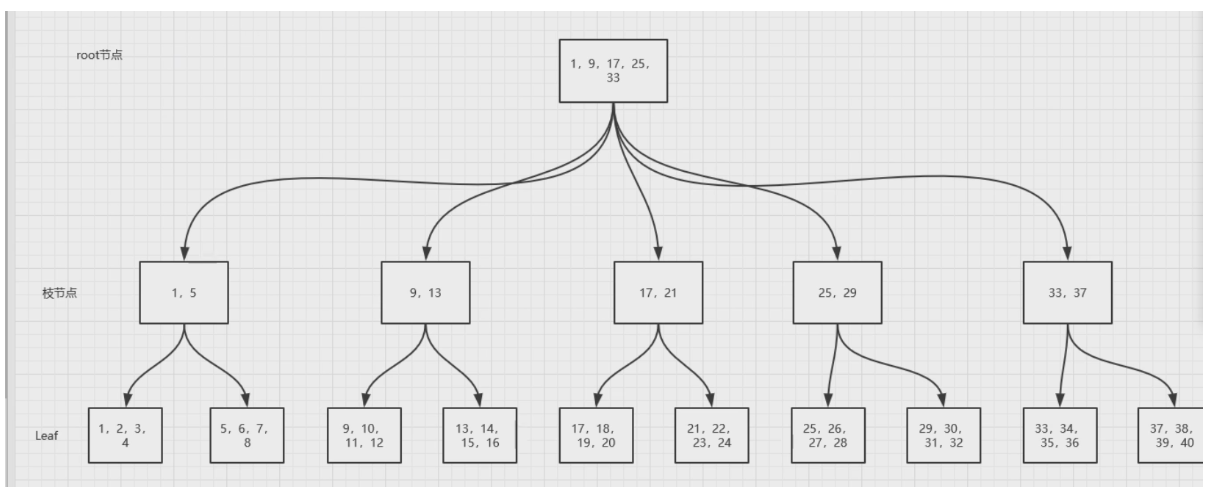
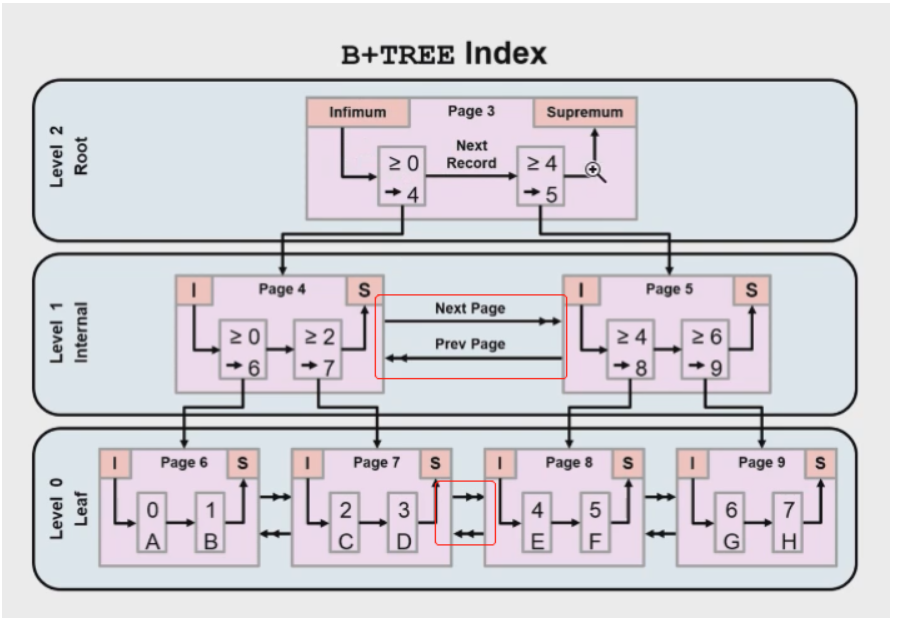
现在使用的B*Tree:
三、聚簇索引
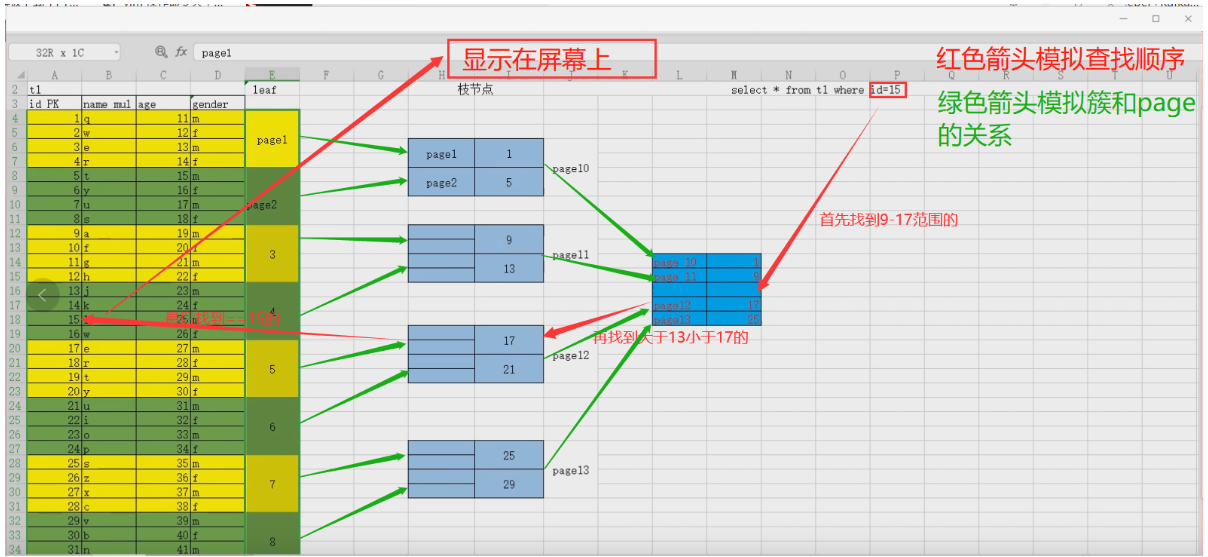
3.1 、聚簇索引BTREE结构( InnoDB独有)区
3.1.1 、簇
区extent >簇>64个pages ====>1M
3.1.2、作用:
有了聚簇索引之后,将来插入的数据行,在同一个区内,都会按照Ip值的顺序,有序在磁盘存储数据。MysQL InnoDB 表聚族索引组织存储数据表。
3.1.3、簇构建前提:
1.建表时,指定了主键列,MySQL InnoDB会将主键作为聚簇索引列,比如ID not null primary key
2.没有指定主键,自动选择唯一键(unique)的列,作为聚簇索引。
3.以上都没有,生成|隐藏聚族索引。
作用:
有了聚簇索引之后,将来插入的数据行,在同一个区内,都会按照ID值的顺序,有序在磁盘存储数据。
四、辅助索引
4.1、说明
使用普通列作为条件构建的索引。需要人为创建。
4.2、作用
优化非聚簇索引列之外的查询条件的优化。
4.3、图解
4.4、辅助索引的细分(1)单列索引
(1) 单列索引
(2)联合索引
说明:使用多列组合一个索引。
联合索引,注意最左原则。idx (a,b,c)
1.查询条件中,必须要包含最左列,上面列子就是a列
2.建立联合索引时,一定要选择重复值少的列,作为最左列。
# 全部覆盖 都走abc索引
例如:idx(a,b,c)
select * from t1 where a=and b=andc=
select * from tl where a inand b in and c in
select * from tl where b=andc=and a=
部分覆盖: 走部分索引
select * from tl where a=and b=select * from tl where a=
select * from tl where a= andc=
select * from t1 where a= and b >< >=<= likeand c=
select xxxfrom tl where aorder by b
五、前缀索引
前缀索引是针对于,我们所选择的索引列值长度过长,会导致索引树高度增高。
所以可以选择大字段的前面部分字符作为索引生成条件。
会导致索引应用时,需要读取更多的索引数据页
MvSoL中建议索引树高度3-4层。
六、B+tree索引树高度影响因素
1.索引字段较长:前缀索引
2.数据行过多:分区表,归档表(pt-archive),分布式架构(大企业)
3.数据类型:选择合适的数据类型。
七、索引的管理命令
7.1、什么时候创建索引?
并不是将所有列都建立索引。不是索引越多越好。按照业务语句的需求创建合适的索引。
将索引建立在,经常 where group by order by join on ....的条件。为什么不能乱建索引?
1.如果冗余索引过多,表的数据变化的时候,很有可能会导致索引频繁更新。会阻塞很多正常的业务更新的请求。
2.索引过多,会导致优化器选择出现偏差。
7.2、管理命令
1.查询表的索引情况mysql> desc city;
key: PRI聚簇索引
MUL: 辅助索引
UNI:唯一索引
mysql> show index from city;
2.建立索引
分析业务语句:
mysql> select * from city where name=' wuhan' ;
mysql> alter table city add index idx_na (name) ;
# 组合索引
alter table city add index idx_na_c (name,xxx);
# 前缀索引
alter table city add index idx_d(disstrict(5));
3.删除索引
mysql> alter table city drop index idx_na;
7.3、压力测试
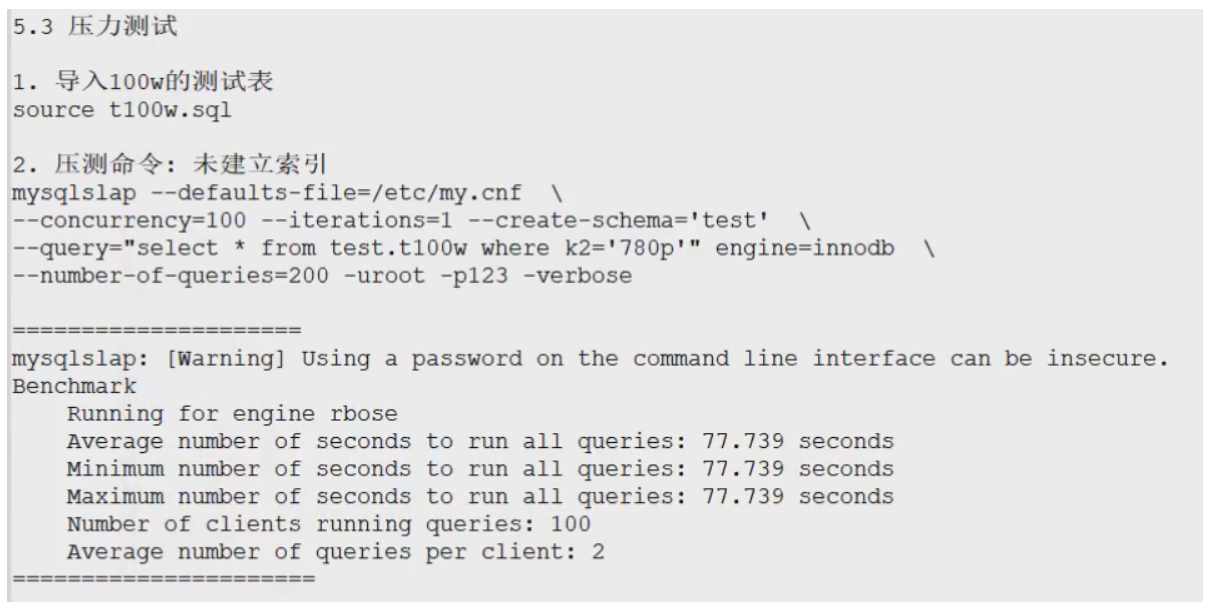
新建索引,再次执行以上的命令!就可以看到明显的速度改变了!!!
----------------------------------面试题级别的-------------------------------------------
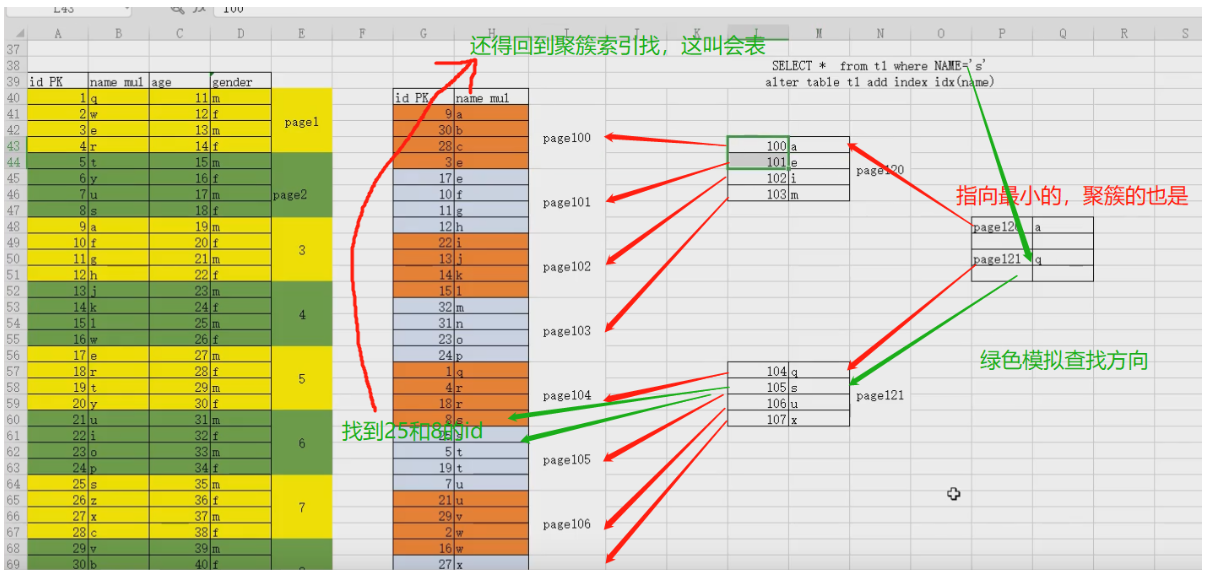
一、回表
什么时候回表?
辅助索引:将辅助索引列值+ID主键值,构建辅助索引B树结构。
用户使用,辅助索引列作为条件查询时,首先扫描辅助索引的b树。
1,如果辅助索引能够完全覆盖我们的查询结果时,就不需要回表了。
2,如果不能完全覆盖到,只能通过得出的ID主键值,回到聚簇索引(回表)扫描,最终得到想要的结果。
回表会带来什么影响?
1. I0量级变大
2. IOPS会增大
3.随机I0会增大
怎么减少回表
1.将查询尽可能用ID主键查询
2.设计合理的联合索引
完全覆盖
select name, age,gender from t1 where name='zs'
3.更精确的查询条件+联合索引
select★from tl where name='zs' and addr ='bj'
二、更新数据时,会对索引有影响吗?数据的变化会使索引实时影响吗?
比如insert, update, delete 数据。
对于聚簇索引会立即更新。
对于辅助索引,不是实时更新的。
在InnoDB内存结构中,加入了insert buffer (会话),现在版本叫change。
Changebuffer功能是临时缓冲辅助索引需要的数据更新。
当我们需要查询新insert的数据,会在内存中进行merge(合并)操作,此时辅助索引就是最新的。

