

HDFS
HDFS的简介:
HDFS的产生背景:随着数据量的越来越大,一个操作系统存储不下所有的数据。需要分配到更多的操作系统管理的磁盘上存储。但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统,HDFS只是分布式文件管路系统的一种。
HDFS的简介:HDFS是一个分布式文件系统,用于存储文件,通过目录树结构来定位文件。
HDFS的使用场景:适合一次写入,多次读出的场景。不支持文件的修改。适合做数据分析,并不适合做网盘应用。
HDFS的缺点:
1.不适合做低延时的数据访问
2.无法高效的存储小文件:1.存储了大量小文件,会占用大量的namenode的存储空间去存储小文件的目录和块信息。2.小文件的寻址时间会超过读取时间,违背了HDFS的设计初衷
3.不支持文件的随机修改,并发写入:1.一个文件只能有一个写,不允许多个线程同时写。2.仅支持数据的append(追加),不支持文件的随机修改。
HDFS的文件块大小:128M(寻址时间为传输时间的1%,目前的磁盘传输速率为:128MB/s)
HDFS的文件块的大小设置取决于:磁盘传输的速率
HDFS的客户端操作:
准备的Hadoop客户端开发环境:https://www.cnblogs.com/hskq/articles/16286240.html
HDFS客户端操作的执行代码:
(客户端代码的常用套路)
//1.创建客户端连接对象
//2.执行操作
//3.释放资源
@Test
public void testCopyFromLocalFile() throws IOException, InterruptedException, URISyntaxException {
// 1 获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"), configuration, "atguigu");
// 2 上传文件
fs.copyFromLocalFile(new Path("e:/banzhang.txt"), new Path("/banzhang.txt"));
// 3 关闭资源
fs.close();
}
配置项中的参数优先级:
参数优先级排序:(1)客户端代码中设置的值 >(2)ClassPath下的用户自定义配置文件 >(3)然后是服务器的自定义配置(xxx-site.xml) >(4)服务器的默认配置(xxx-default.xml)
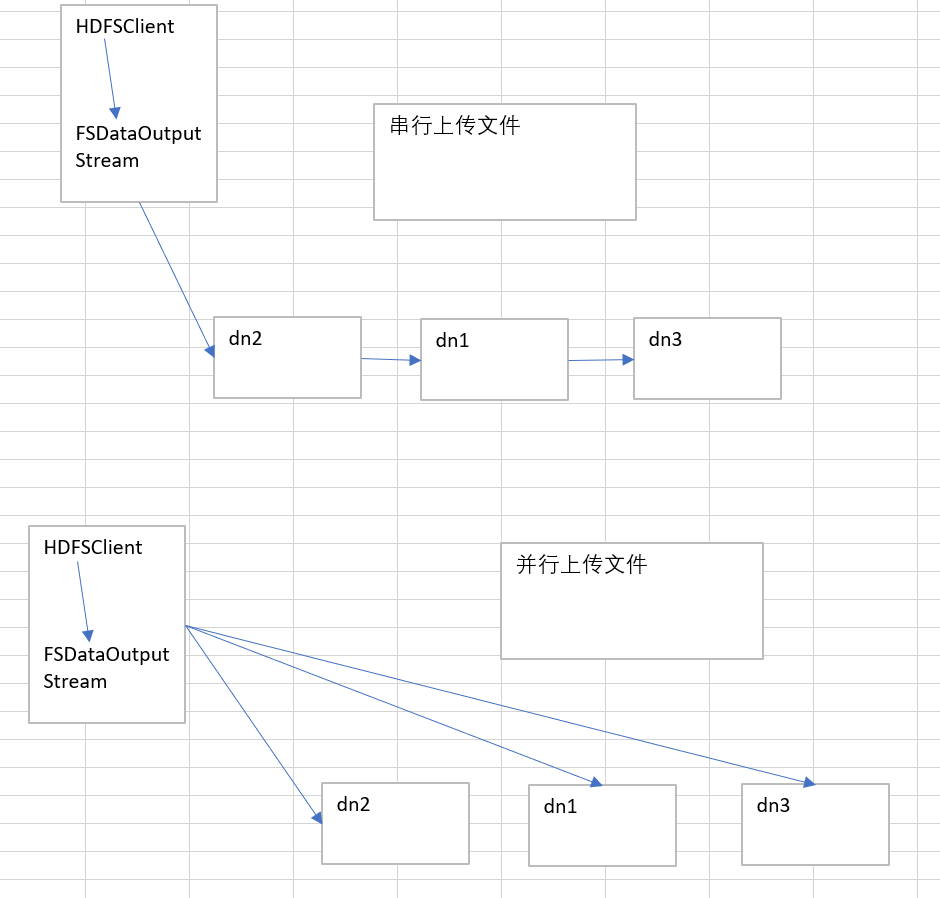
HDFS的写数据流程(重点):
1.HDFSClient会创建分布式文件系统对象,请求将文件上传到HDFS集群中(HDFS会进行检验:1.校验是否有权限 2.检验目录结构(上传的目录结构是否存在))
2.校验结束后,HDFS将可以上传的消息响应给客户端
3.请求将第一个块文件上传到HDFS上
4.HDFS返回三个节点(返回节点的策略为(节点距离最近且负载均衡):1.本地节点2.其他机架上的节点3.其他机架的其他节点)给客户端
5.HDFSClient创建FSDataOutputStream,并与节点建立连接Block传输管道。节点应答成功。
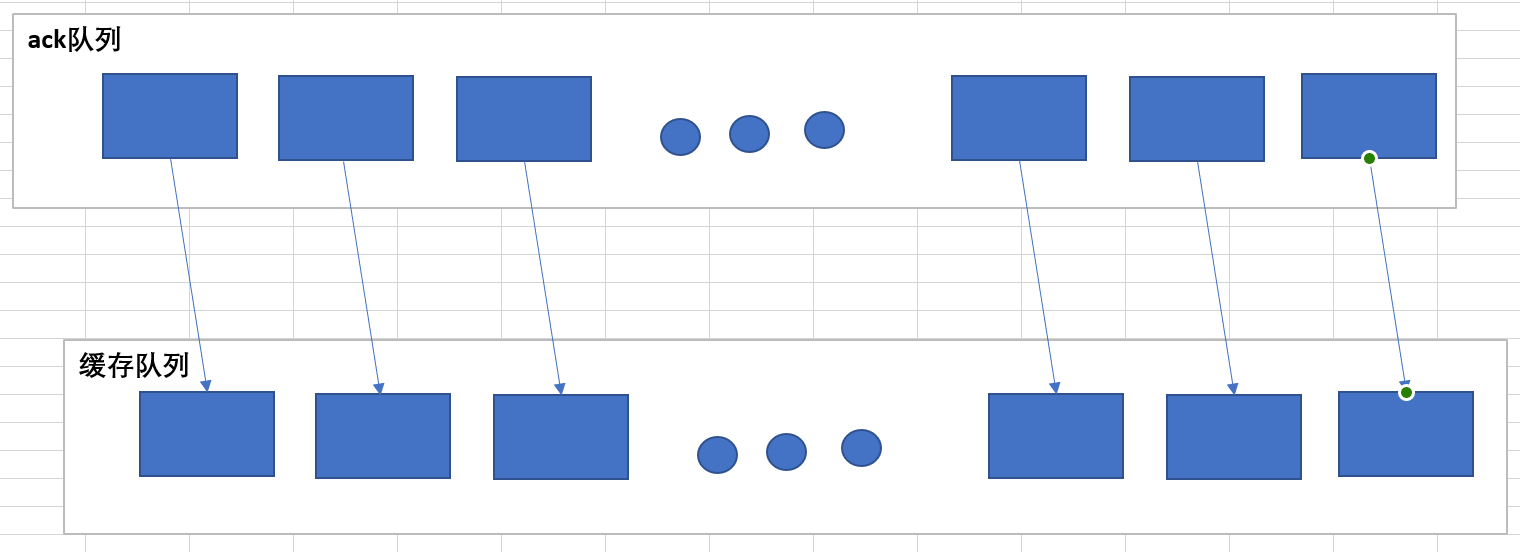
6.开始上传文件:1.将上传的文件细分为一个一个的chunk(512byte + 4byte),放入缓存队列中,(同时放入ack队列中)等到缓存队列中的chunk达到了一个packet(64kb),开始传输。
2.每次传输一个packet,到达节点后,先将packet在磁盘中存储一份,同时将内存packet传输给下一个节点。(效率高)
出现问题:如果在发送过程中出现了问题,文件回滚,将ack队列中的数据回滚到缓存队列中,再次发送。
网络拓扑——节点距离计算:节点找到对方节点的距离。
机架感知(副本存储节点的选择):1.选择客户端所在的节点 2.选择远离第一个节点所在的其他机架上的节点 3.选择其他机架上的其他节点
HDFS读数据流程:
1.HDFSClient会创建分布式文件系统对象,向NameNode请求下载文件(NameNode会校验文件的路径、文件是否存在等,还有用户的权限)
2.NameNode校验成功后,会返回文件的元数据信息。
3.HDFSClient会创建FSInputStream读取数据块(选取的节点原则为:节点距离和节点的负载均衡)(串行读取,读取完第一个数据块后,再去读取第二个数据块)
4.拼接数据块
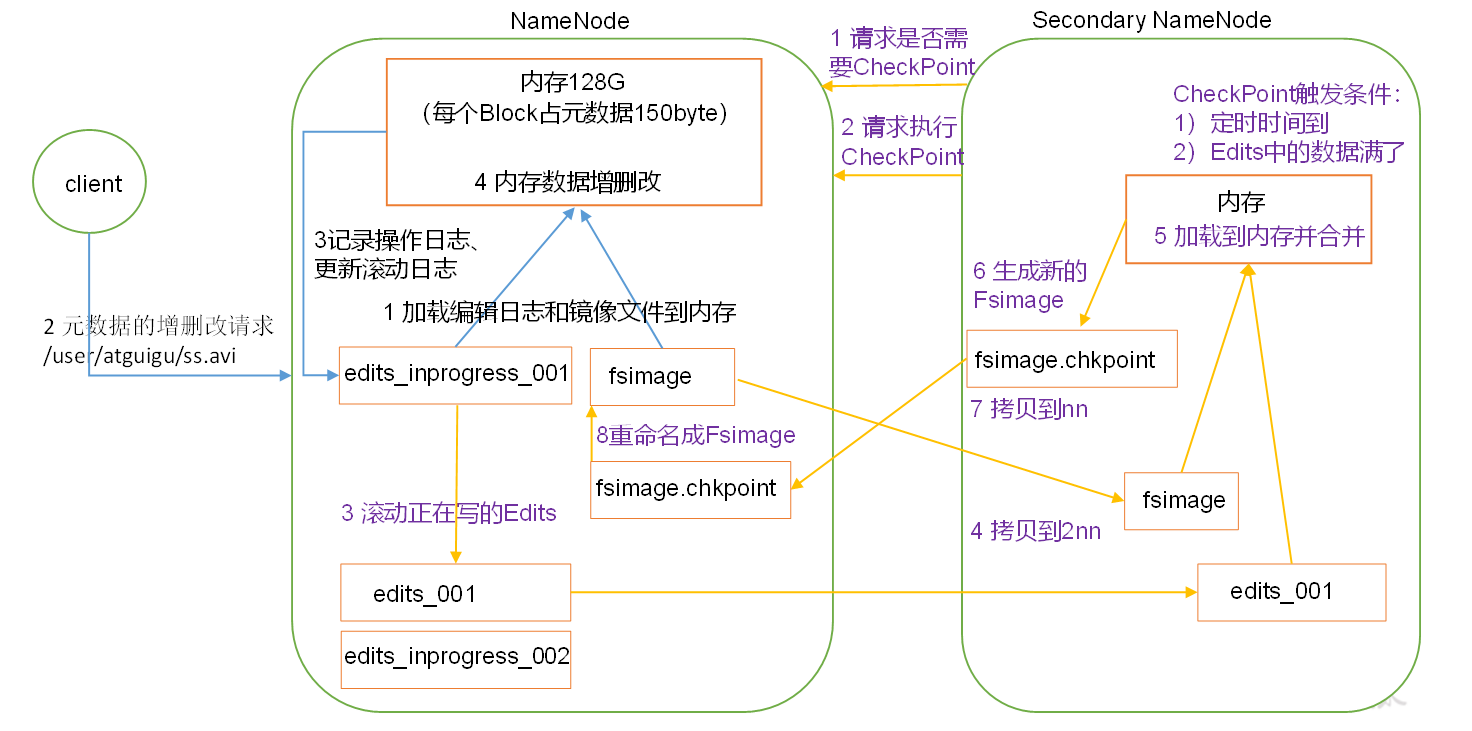
NameNode和SecondaryNameNode工作原理(面试重点):
NameNode中的元数据为了可靠性和效率,分别存储在内存和磁盘中。
磁盘中的FSImage为内存中的元数据文件的镜像文件。磁盘中的Edits追加记录了对元数据进行增删改的操作。
在启动HDFS集群时,会将磁盘中的FSImage和Edits文件加载到内存中,进行合并。
在关闭集群的时候,会将磁盘中的Edits文件和磁盘中的FSImage文件进行合并。
在HDFSClient发出对元数据进行增删改操作时:
1.NameNode会先将操作记录在Edits中,然后再对内存中的元数据文件进行修改。
2.SecondaryNameNode会每隔一段时间向NameNode发送CheckPoint的请求(发送CheckPoint的请求满足两个条件:1.定时时间到(默认1个小时)2.Edits中的记录数达到一定的数量(默认100万条数据,SecondaryNameNode每隔1分钟去查看NameNode中Edits中的数据是否达到100万条))
3.此时,NameNode会生成一个新的Edits(用来记录最新的操作),然后将旧的Edits滚动并重命名
4.SecondaryNameNode将旧的Edits和FSImage拷贝过去,在内存中进行合并,并将其送会NameNode中替代旧的FSImage
集群的安全模式:
1.NameNode启动后:会将镜像文件(FSImage)加载到内存中,并执行编辑日志(Edits)中的操作,一旦在内存中建立系统元数据的映像,就会生成一个新的编辑日志,此时NameNode开始监听DataNode的请求。
2.DataNode启动后:在安全模式下,DataNode会向NameNode发送所有数据块的信息
3.安全模式的退出: 如果满足最小副本条件,NameNode会在30秒后退出安全模式。最小副本条件:整个文件系统中99.9%的块满足最小副本级别(默认值:dfs.replication.min=1)
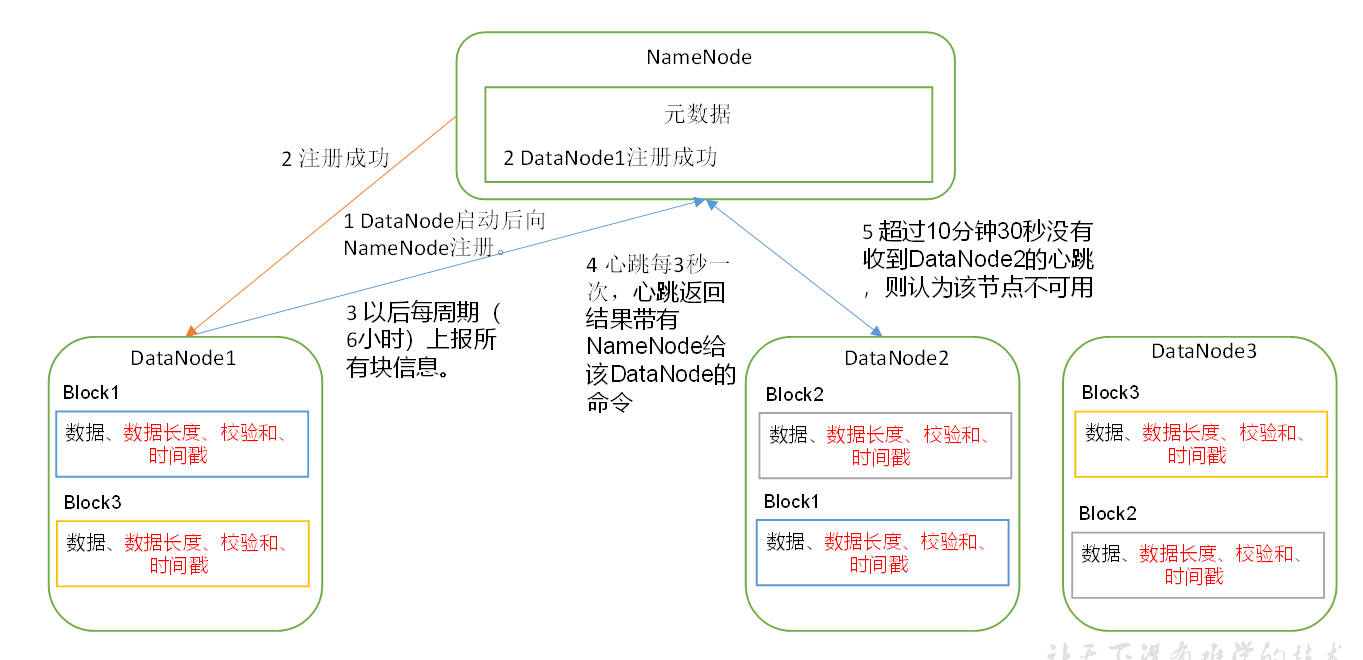
DateNode的工作机制:
1.在HDFS集群启动时,DataNode会向NameNode注册,发送所有块的信息
2.NameNode将这些信息存储在元数据中,并向DataNode发送注册成功
3.每隔六个小时DateNode会向NameNode再次发送所有数据块的信息
4.在HDFS集群工作时,DataNode和NameNode会进行心跳连接,每隔三秒,DataNode会向NameNode汇报,告诉NameNode自己还活着。
5.如果超过10分钟 + 30秒,DataNode还没有向NameNode汇报,NameNode认为该节点已经死亡(HDFSClient不能从上面进行读取数据等操作)
DataNode中存储的数据:
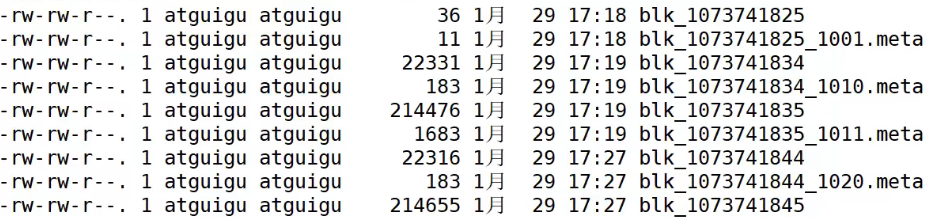
blk_开头,没有.meta结尾的代表存储数据的数据块
.meta结尾中负责存储数据块的相关信息(校验和,时间戳等)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通