1.12那些年你不知道的爬虫面试题
1. 什么是爬虫和反爬虫?
爬虫:使用任何技术手段,批量获取网站信息的一种方式。
反爬虫:使用任何技术手段,阻止别人批量获取自己网站信息的一种方式。
2. 常见的反爬虫机制
通过UA 识别爬虫 有些爬虫的UA是特殊的,与正常浏览器的不一样,可通过识别特征UA,直接封掉爬虫请求
设置IP访问频率,如果超过一定频率,弹出验证码 如果输入正确的验证码,则放行,如果没有输入,则拉入禁止一段时间,如果超过禁爬时间,再次出发验证码,则拉入黑名单。当然根据具体的业务,为不同场景设置不同阈值,比如登陆用户和非登陆用户,请求是否含有refer。
通过并发识别爬虫 有些爬虫的并发是很高的,统计并发最高的IP,加入黑名单(或者直接封掉爬虫IP所在C段)
请求的时间窗口过滤统计 爬虫爬取网页的频率都是比较固定的,不像人去访问网页,中间的间隔时间比较无规则,所以我们可以给每个IP地址建立一个时间窗口,记录IP地址最近12次访问时间,每记录一次就滑动一次窗口,比较最近访问时间和当前时间,如果间隔时间很长判断不是爬虫,清除时间窗口,如果间隔不长,就回溯计算指定时间段的访问频率,如果访问频率超过阀值,就转向验证码页面让用户填写验证码
限制单个ip/api token的访问量 比如15分钟限制访问页面180次,具体标准可参考一些大型网站的公开api,如twitter api,对于抓取用户公开信息的爬虫要格外敏感
识别出合法爬虫 对http头agent进行验证,是否标记为、百度的spider,严格一点的话应该判别来源IP是否为、baidu的爬虫IP,这些IP在网上都可以找到。校验出来IP不在白名单就可以阻止访问内容。
3. 破解反爬虫机制的几种方法
策略1:设置下载延迟,比如数字设置为5秒,越大越安全
策略2:禁止Cookie,某些网站会通过Cookie识别用户身份,禁用后使得服务器无法识别爬虫轨迹
策略3:使用user agent池。也就是每次发送的时候随机从池中选择不一样的浏览器头信息,防止暴露爬虫身份
策略4:使用IP池,这个需要大量的IP资源,可以通过抓取网上免费公开的IP建成自有的IP代理池。
策略5:分布式爬取,这个是针对大型爬虫系统的,实现一个分布式的爬虫,主要为以下几个步骤:1、基本的http抓取工具,如scrapy; 2、避免重复抓取网页,如Bloom Filter; 3、维护一个所有集群机器能够有效分享的分布式队列; 4、将分布式队列和Scrapy的结合; 5、后续处理,网页析取(如python-goose),存储(如Mongodb)。
策略6:模拟登录—浏览器登录的爬取 设置一个cookie处理对象,它负责将cookie添加到http请求中,并能从http响应中得到cookie,向网站登录页面发送一个请求Request, 包括登录url,POST请求的数据,Http header利用urllib2.urlopen发送请求,接收WEB服务器的Response。
4.动态加载又对及时性要求很高怎么处理?
- Selenium+Phantomjs
- 尽量不使用 sleep 而使用 WebDriverWait
如何知道一个网站是动态加载的数据?
用火狐或者谷歌浏览器 打开你网页,右键查看页面源代码,ctrl +F 查询输入内容,源代码里面并没有这个值,说明是动态加载数据。
5.python 爬虫有哪些常用框架?
| 序号 | 框架名称 | 描述 | 官网 |
|---|---|---|---|
| 1 | Scrapy | Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。用这个框架可以轻松爬下来如亚马逊商品信息之类的数据。 | https://scrapy.org/ |
| 2 | PySpider | pyspider 是一个用python实现的功能强大的网络爬虫系统,能在浏览器界面上进行脚本的编写,功能的调度和爬取结果的实时查看,后端使用常用的数据库进行爬取结果的存储,还能定时设置任务与任务优先级等。 | https://github.com/binux/pyspider |
| 3 | Crawley | Crawley可以高速爬取对应网站的内容,支持关系和非关系数据库,数据可以导出为JSON、XML等。 | http://project.crawley-cloud.com/ |
| 4 | Portia | Portia是一个开源可视化爬虫工具,可让您在不需要任何编程知识的情况下爬取网站!简单地注释您感兴趣的页面,Portia将创建一个蜘蛛来从类似的页面提取数据。 | https://github.com/scrapinghub/portia |
| 5 | Newspaper | Newspaper可以用来提取新闻、文章和内容分析。使用多线程,支持10多种语言等。 | https://github.com/codelucas/newspaper |
| 7 | Grab | Grab是一个用于构建Web刮板的Python框架。借助Grab,您可以构建各种复杂的网页抓取工具,从简单的5行脚本到处理数百万个网页的复杂异步网站抓取工具。Grab提供一个API用于执行网络请求和处理接收到的内容,例如与HTML文档的DOM树进行交互。 | http://docs.grablib.org/en/latest/#grab-spider-user-manual |
| 8 | Cola | Cola是一个分布式的爬虫框架,对于用户来说,只需编写几个特定的函数,而无需关注分布式运行的细节。任务会自动分配到多台机器上,整个过程对用户是透明的。 | 没找着~ |
| 9 | 很多 | 看自己积累 | 多百度 |
6. Scrapy 的优缺点?
优点:scrapy 是异步的
采取可读性更强的 xpath 代替正则强大的统计和 log 系统,同时在不同的 url 上爬行支持 shell 方式,方便独立调试写 middleware,方便写一些统一的过滤器,通过管道的方式存入数据库。
缺点:基于 python 的爬虫框架,扩展性比较差
基于 twisted 框架,运行中的 exception 是不会干掉 reactor,并且异步框架出错后是不会停掉其他任务的,数据出错后难以察觉。
7.scrapy 和 request?
- scrapy 是封装起来的框架,他包含了下载器,解析器,日志及异常处理,基于多线程, twisted 的方式处理,对于固定单个网站的爬取开发,有优势,但是对于多网站爬取,并发及分布式处理方面,不够灵活,不便调整与括展。
- request 是一个 HTTP 库, 它只是用来,进行请求,对于 HTTP 请求,他是一个强大的库,下载,解析全部自己处理,灵活性更高,高并发与分布式部署也非常灵活,对于功能可以更好实现。
8.描述下 scrapy 框架运行的机制?
- 从 start_urls 里获取第一批 url 并发送请求,请求由引擎交给调度器入请求队列,获取完毕后,调度器将请求队列里的请求交给下载器去获取请求对应的响应资源,并将响应交给自己编写的解析方法做提取处理,如果提取出需要的数据,则交给管道文件处理;
- 如果提取出 url,则继续执行之前的步骤(发送 url 请求,并由引擎将请求交给调度器入队列…),直到请求队列里没有请求,程序结束。
9. 实现模拟登录的方式有哪些?
- 使用一个具有登录状态的 cookie,结合请求报头一起发送,可以直接发送 get 请求,访问登录后才能访问的页面。
- 先发送登录界面的 get 请求,在登录页面 HTML 里获取登录需要的数据(如果需要的话),然后结合账户密码,再发送 post 请求,即可登录成功。然后根据获取的 cookie信息,继续访问之后的页面。
- 还可以使用通用方法 selenium Pyppeteer
10.你遇到过的反爬虫的策略?
- BAN IP
- BAN USERAGENT
- BAN COOKIES
- 验证码验证
- javascript渲染
- ajax异步传输
11.你常用的反反爬虫的方案?
1.IP封锁
因为会对用户产生误伤,所以网站一般不会对用户的IP进行长时间的封锁。
解决方案:
(1)修改程序的访问频率
(2)使用IP代理的方式来对网站进行爬取
2.协议头
绝大多数网站,访问时会判断访问来源。
解决方案:
(1)访问时添加协议头
3.验证码
当用户请求频率过高的时候,有些网站就会触发验证码验证机制。
解决方案:
接入打码API,例如云打码。
4.需要登录
有些网站需要用户登录之后才能够获取页面中的信息,那么这种防护能非常有效的防止数据被大批量的被爬取。
解决方案:
(1)小数据量进行爬取(模拟登录后再去爬取,或者使用cookies 直接进行爬取)
(2)申请诸多的账号去养这些号,然后登录,或者获得cookies进行爬取。
5.动态页面的爬取
有一些网站的数据和图片是用JS代码动态生成的,那么服务器端,就会通过判断该用户是否访问了这些资源来判断是否爬虫。
通用解决方案:
(1)使用selenium
12.你用过多线程和异步吗?除此之外你还用过什么方法来提高爬虫效率?
1.协程
2.设置超时时间
3.Scrapy框架
13.有没有做过增量式抓取?
在发送请求之前判断这个URL是不是之前爬取过
在解析内容后判断这部分内容是不是之前爬取过
去重方法
- 将爬取过程中产生的url进行存储,存储在redis的set中。当下次进行数据爬取时,首先对即将要发起的请求对应的url在存储的url的set中做判断,如果存在则不进行请求,否则才进行请求。
- 对爬取到的网页内容进行唯一标识的制定,然后将该唯一表示存储至redis的set中。当下次爬取到网页数据的时候,在进行持久化存储之前,首先可以先判断该数据的唯一标识在redis的set中是否存在,在决定是否进行持久化存储
14.给定a、b两个文件,各存放50亿个url,每个url各占用64字节,内存限制是4G,如何找出a、b文件共同的url?
使用位图来进行处理。比如说这10亿个数的范围为【0-10亿】,那么就申请一个10亿的数组,
数组类型为boolen,只有0和1,0表示没有,1表示有。
这样自然而然的就删掉了重复的部分。
方案一:布隆过滤器
至于内存消耗方面的优化,实际上,如果想要内存方面有明显的节省,那就得换一种存储结构,也就是接下来要重点讲的布隆过滤器(Bloom Filter)。在讲布隆过滤器前,我们要来先认识一下另一种存储结构,位图(BitMap)。因为,布隆过滤器本身就是基于位图的,是对位图的一种改进
如果允许有一定的错误率,可以使用Bloom filter,4G内存大概可以表示340亿bit。将其中一个文件中的url使用Bloom filter映射为这340亿bit,然后挨个读取另外一个文件的url,检查是否与Bloom filter,如果是,那么该url应该是共同的url(注意会有一定的错误率)
方案二:分治思想
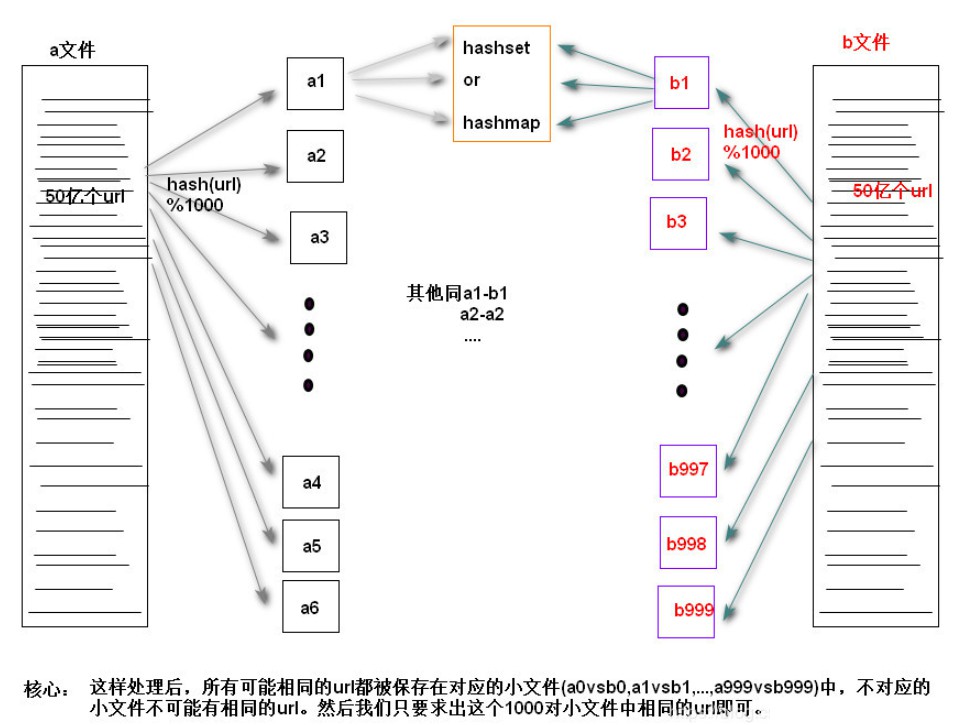
Step1:遍历文件a,对每个url求取hash(url)%1000,然后根据所取得的值将url分别存储到1000个小文件(记为a0,a1,...,a999,每个小文件约300M);
Step2:遍历文件b,采取和a相同的方式将url分别存储到1000个小文件(记为b0,b1,...,b999);
巧妙之处:这样处理后,所有可能相同的url都被保存在对应的小文件(a0vsb0,a1vsb1,...,a999vsb999)中,不对应的小文件不可能有相同的url。然后我们只要求出这个1000对小文件中相同的url即可。
Step3:求每对小文件ai和bi中相同的url时,可以把ai的url存储到hash_set/hash_map中。然后遍历bi的每个url,看其是否在刚才构建的hash_set中,如果是,那么就是共同的url,存到文件里面就可以了。
1、Hash取模是一种等价映射,不会存在同一个元素分散到不同小文件中的情况,即这里采用的是mod1000算法,那么相同的url在hash取模后,只可能落在同一个文件中,不可能被分散的。因为如果两个url相等,那么经过Hash(url)之后的哈希值是相同的,将此哈希值取模(如模1000),必定仍然相等。
2、那到底什么是hash映射呢?简单来说,就是为了便于计算机在有限的内存中处理big数据,从而通过一种映射散列的方式让数据均匀分布在对应的内存位置(如大数据通过取余的方式映射成小树存放在内存中,或大文件映射成多个小文件),而这个映射散列方式便是我们通常所说的hash函数,设计的好的hash函数能让数据均匀分布而减少冲突。尽管数据映射到了另外一些不同的位置,但数据还是原来的数据,只是代替和表示这些原始数据的形式发生了变化而已。
15.爬取图片不完整,失败怎么处理
不完整可能是图片较大,导致部分数据丢失,保存不完整,可以边下载边存,如 data.iter_content() 方法;为了防止失败,最保险的办法是先获取文件的大小,下载后判断一下大小是否一样,浏览器开发者模式 response 里面有一个 content-length 可以判断文件大小
16.JS逆向
请求正文里的参数,可以用多个浏览器去请求页面,然后再去观察
可以观察操作时是否加载了 js 文件,查找对应的 js 文件
如何快速查找 js
方案一:通过点击按钮,然后点击Event Listener,部分网站可以找到绑定的事件,对应的,只需要点击即可跳转到js的位置
方案二:部分网站可能没有绑定 js 监听事件,那么我们可以在 js 文件中搜索 请求正文参数的关键字,或者一些类似加密的函数,比如哈希,base64等
还可以从链接调用开始着手
如果加密很少的 js 我们可以用python复写(也可以使用js2py直接把js代码转化为python程序去执行),但是一旦加密函数过于庞大就需要将 js 抽取出用python+node或是webdriver来执行相关函数
如果是几百几千行的 js 加密呢?
用 python 复写其实也不是不能,但是开发时间和破解效率都是一个很关键的问题
如果说开发时间紧急,那么此时我们就需要使用其他的方式来执行这段 js
第一种:使用 selenium+webdriver 来执行本地文件,然后调用本地 html 上的 js 运行
第二种:使用 python 下的库 exec.js 来调用node来执行
17.解决爬取频率问题
分限制方案,是限制账号还是访问频率
账号限制的话,可以准备多个账号去随机访问
访问频率的话,最 low 的方法是 sleep,你还可以使用代理 IP 池,或者分布式爬虫
18.scrapy 中添加请求头
-
第一种方法,在 scrapy 的spider 中添加请求头
这种方法的好处是可以比较灵活,可以随意的添加,任意请求头
-
第二种方法,是在 scrapy 的 setting 里添加
-
第三种方法,是在 scrapy 的 middware 中添加请求头,
1 在 spider 将需要爬取的网页 url 发送给 Scrapy Engine
2 Scrapy Engine 本身不做任何处理,直接发送给 Scheduler
3 Scheduler 生成 Requests 发送给 Engine
4 Engine 拿到 Requests,通过 middware 发送给 Downloader
注意:要在 settings 里启动中间件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号