1.5cookies
Cookie简介
HTTP协议 是无状态的协议,用户浏览服务器上的内容,只需要发送页面请求,服务器返回内容。
对于服务器来说,并不关心,也并不知道是哪个用户的请求。
对于一般浏览性的网页来说,没有任何问题。
但是,现在很多的网站,是需要用户登录的。以淘宝为例:比如说某个用户想购买一个产品,当点击 “ 购买按钮 ” 时,由于HTTP协议 是无状态的,那对于淘宝来说,就不知道是哪个用户操作的。
为了实现这种用户标记,服务器就采用了cookie这种机制来识别具体是哪一个用户的访问。
1 cookie的工作原理是:由服务器产生内容,浏览器收到请求后保存在本地;当浏览器再次访问时,浏览器会自动带上cookie,这样服务器就能通过cookie的内容来判断这个是“谁”了。
2 cookie虽然在一定程度上解决了“保持状态”的需求,但是由于cookie本身最大支持4096字节,以及cookie本身保存在客户端,可能被拦截或窃取
因此就需要有一种新的东西,它能支持更多的字节,并且他保存在服务器,有较高的安全性。这就是session。
3 总结而言:cookie弥补了http无状态的不足,让服务器知道来的人是“谁”;但是cookie以文本的形式保存在本地,自身安全性较差;
所以我们就通过cookie识别不同的用户,对应的在session里保存私密的信息以及超过4096字节的文本。
每当我们使用一款浏览器访问一个登陆页面的时候,一旦我们通过了认证。服务器端就会发送一组随机唯一的字符串(假设是123abc)到浏览器端,这个被存储在浏览器端的东西就叫cookie。
而服务器端也会自己存储一下用户当前的状态,比如login=true,username=hahaha之类的用户信息。
但是这种存储是以字典形式存储的,字典的唯一key就是刚才发给用户的唯一的cookie值(存在cookie中,cookie也是字典形式存储的,cookie的值是一个字典,存放了一些信息,其中就包括了sessionid(键),sessionid的值则为服务端的session的唯一键)。那么如果在服务器端查看session信息的话,理论上就会看到如下样子的字典
{'123abc':{'login':true,'username:hahaha'}}
Cookie反爬虫原理与实现
可以在 headers 添加Cookie
import requests from lxml import etree url = 'http://www.porters.vip/verify/cookie/content.html' Header = {'Cookie': 'isfirst=789kq7uc1pp4c'} res = requests.get(url=url, headers=Header) print(res.text) if res.status_code == 200: html = etree.HTML(res.text) res = html.cssselect('.page-header h1')[0].text print(res) else: print('fail')Cookie不仅可以用于Web服务器的用户身份信息存储或者状态保存,还能够用于反爬虫
发不发的反爬虫程序在默认情况下只请求HTML 文本资源,这意味着他们并不会主动完成浏览器保存 Cookie的操作
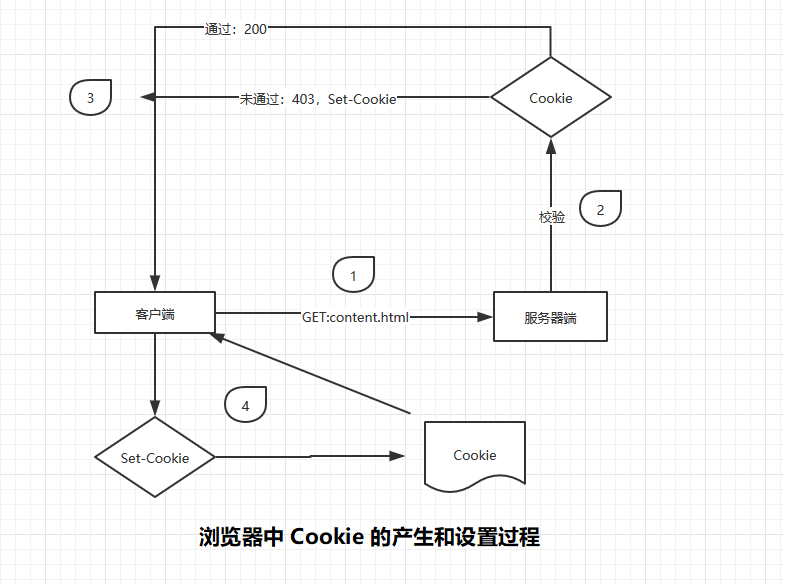
那么浏览器又是如何完成Cookie的获取与设置呢?浏览器会自动检测响应头中是否存在 Set-Cookie 头域,如果存在,则将值保存在本地,而且往后的每次请求都会自动携带对应的Cookie值,这时候只要服务器端对请求头中的Cookie 值进行校验即可
服务器会检验每个请求头中的Cookie值是否符合规则,如果通过检验,则返回正常资源,否则将请求重定向到首页,同时在响应头中调价Set-Cookie 头域和Cookie值
nginx 中的 add_header 指令可以将头域添加到响应头中,结合判断条件,就可以实现反爬虫
nginx 配置完后,如果未携带正确的 Cookie ,那么浏览器和爬虫程序发出的请求都会被重定向
携带正确的就可以正常访问了
Cookie 和 JavaScript 的结合
Session
- 刚才提到了cookie不安全,所以有了session机制。简单来说(每个框架都不一样,这只是举一个通用的实现策略),整过过程是这样:
-
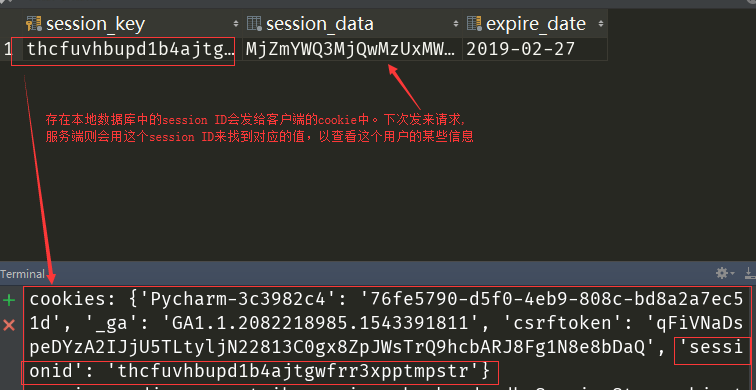
服务器根据用户名和密码,生成一个session ID,存储到服务器的数据库中。
-
用户登录访问时,服务器会将对应的session ID发送给用户(本地浏览器)。
-
浏览器会将这个session ID存储到cookie中,作为一个键值项。
-
以后,浏览器每次请求,就会将含有session ID的cookie信息,一起发送给服务器。
-
服务器收到请求之后,通过cookie中的session ID,到数据库中去查询,解析出对应的用户名,就知道是哪个用户的请求了。
总结
- cookie 在客户端(本地浏览器),session 在服务器端。cookie是一种浏览器本地存储机制。存储在本地浏览器中,和服务器没有关系。每次请求,用户会带上本地cookie的信息。这些cookie信息也是服务器之前发送给浏览器的,或者是用户之前填写的一些信息。
- Cookie有不安全机制。 你不能把所有的用户信息都存在本地,一旦被别人窃取,就知道你的用户名和密码,就会很危险。所以引入了session机制。
- 服务器在发送id时引入了一种session的机制,很简单,就是根据用户名和密码,生成了一段随机的字符串,这段字符串是有过期时间的。
- 一定要注意:session是服务器生成的,存储在服务器的数据库或者文件中,然后把sessionID发送给用户,用户存储在本地cookie中。每次请求时,把这个session ID带给服务器,服务器根据session ID到数据库中去查询,找到是哪个用户,就可以对用户进行标记了。
- session 的运行依赖 session ID,而 session ID 是存在 cookie 中的,也就是说,如果浏览器禁用了 cookie ,那么同时 session 也会失效(但是可以通过其它方式实现,比如在url中传递 session ID)
- 用户验证这种场合一般会用 session。 因此,维持一个会话的核心就是客户端的唯一标识,即session ID
import requests post_url = 'http://www.renren.com/ajaxLogin/login?1=1&uniqueTimestamp=20191051845626' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36', } session = requests.session() #创建一个session对象,该对象会自动将请求中的cookie进行存储和携带 formdata = { 'email': '15072296340', 'password':'' } session.post(url=post_url,data=formdata,headers=headers) #使用session发送请求,目的是为了将session保存该次请求中的cookies get_url = 'http://www.renren.com/256450404/profile?ref=hotnewsfeed&sfet=709&fin=0&fid=28283295275&ff_id=256450404&platform=10&expose_time=1572602798' #再次使用session进行请求的发送,该请求中已经携带了cookies res = session.get(url=get_url,headers=headers).text

 浙公网安备 33010602011771号
浙公网安备 33010602011771号