
量化原理
参考:
- https://developer.aliyun.com/article/836827?utm_content=m_1000314509#slide-0
- https://mp.weixin.qq.com/s/aEBfdSIuGOJfOXgRizvJNQ
- https://www.zhihu.com/column/c_1258047709686231040
模型量化是指将浮点激活值或权重(通常以32比特浮点数表示)近似为低比特的整数(16比特或8比特),进而在低比特的表示下完成计算的过程。通常而言,模型量化可以压缩模型参数,进而降低模型存储开销;并且通过降低访存和有效利用低比特计算指令等,能够取得推理速度的提升,这对于在资源受限设备上部署模型尤为重要。

进一步的,在将输入数据和权重进行量化后,我们就能够将神经网络的常见操作转换为量化操作。以卷积操作为例,其量化版本典型的计算流程如图1所示:
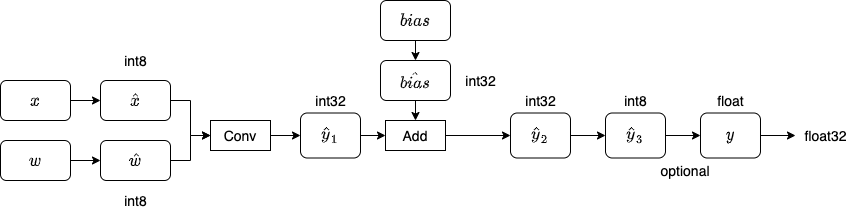
典型的量化卷积算子计算流程图

从上述量化计算的原理能够容易看出,将浮点数转化为低比特整数进行计算会不可避免地引入误差,神经网络模型中每层量化计算的误差会累积为模型整体精度的误差。常见的训练后量化(Post Training Quantization,PTQ)方案中,通过统计在典型输入数据情况下,待量化变量的数值分布,来选择合适的量化参数(scale,zero point等),将因量化而引入的信息损失降低到最小。
但是PTQ方案往往还是无法实现精度无损的模型量化,为了进一步降低量化带来的精度下降,我们可以采用量化感知训练的方案,在训练的计算图中引入伪量化的操作,通过微调训练(finetuning)让模型权重“适应”量化引入的误差,以实现更好的、甚至无损的量化模型精度。
此外,通常在具体推理框架上部署量化模型时,还会对类似conv-bn、conv-relu/relu6、conv-bn-relu/relu6这样的卷积层进行算子融合,因此需要设置为量化融合后的activation。YOLOX中的SiLU激活函数通常不会被融合,output activation的量化仅需要设置到bn的输出,而不是SiLU的输出。训练时一个典型的卷积层量化位置如图2所示。
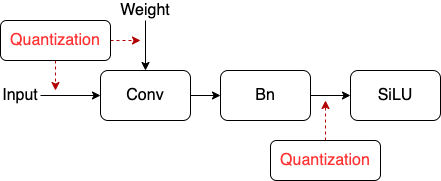
同时,QAT时所有的BN全部fold入相应的卷积中,实验采取了文献[6]中的fold策略。由于模拟量化的引入可能会使得BN层的running_mean与running_var不稳定,从而导致量化训练无法收敛。因此,我们在量化训练中固定BN的running_mean与running_var。

