Python基础之爬取小说
近些年里,网络小说盛行,但是小说网站为了增加收益,在小说中增加了很多广告弹窗,令人烦不胜烦,那如何安静观看小说而不看广告呢?答案就是爬虫。本文主要以一个简单的小例子,简述如何通过爬虫来爬取小说,仅供学习分享使用,如有不足之处,还请指正。
目标页面
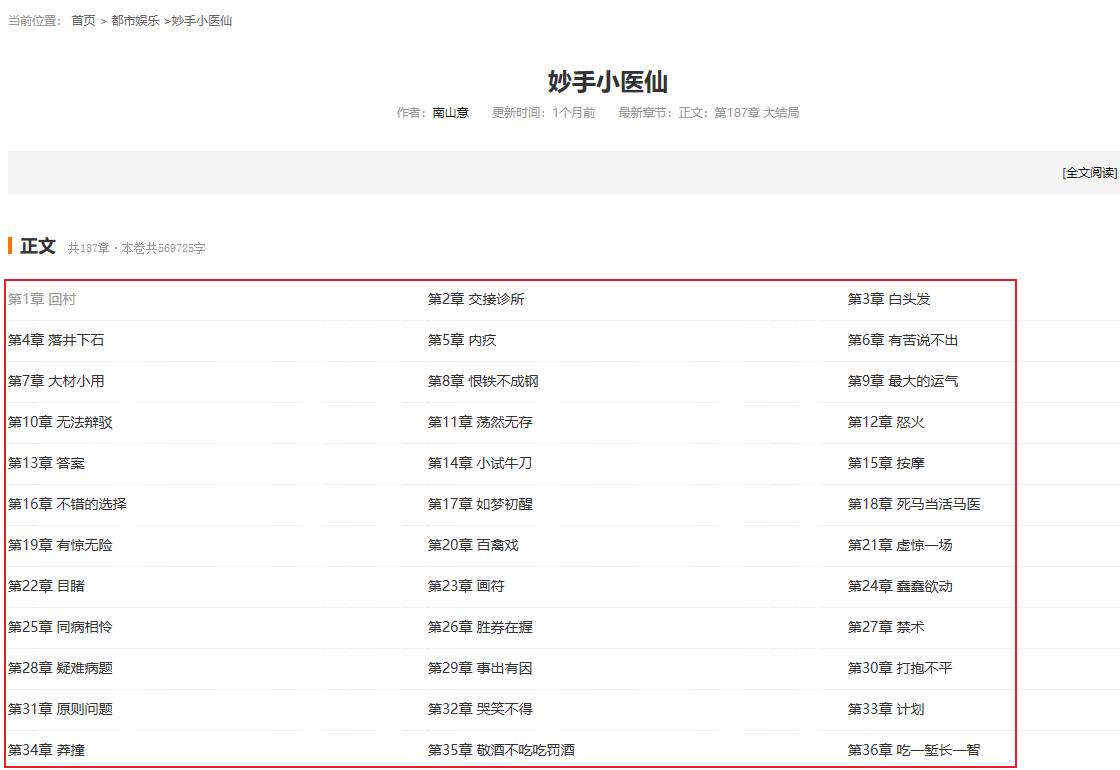
本文爬取的为【某横中文网】的一部小说【妙手小医仙】,已完结,共187章,信息如下:
网址:http://book.abcde.com/showchapter/1102448.html
本次主要爬取小说章节信息,及每一章对应的正文信息。章节信息如下所示:
目标分析
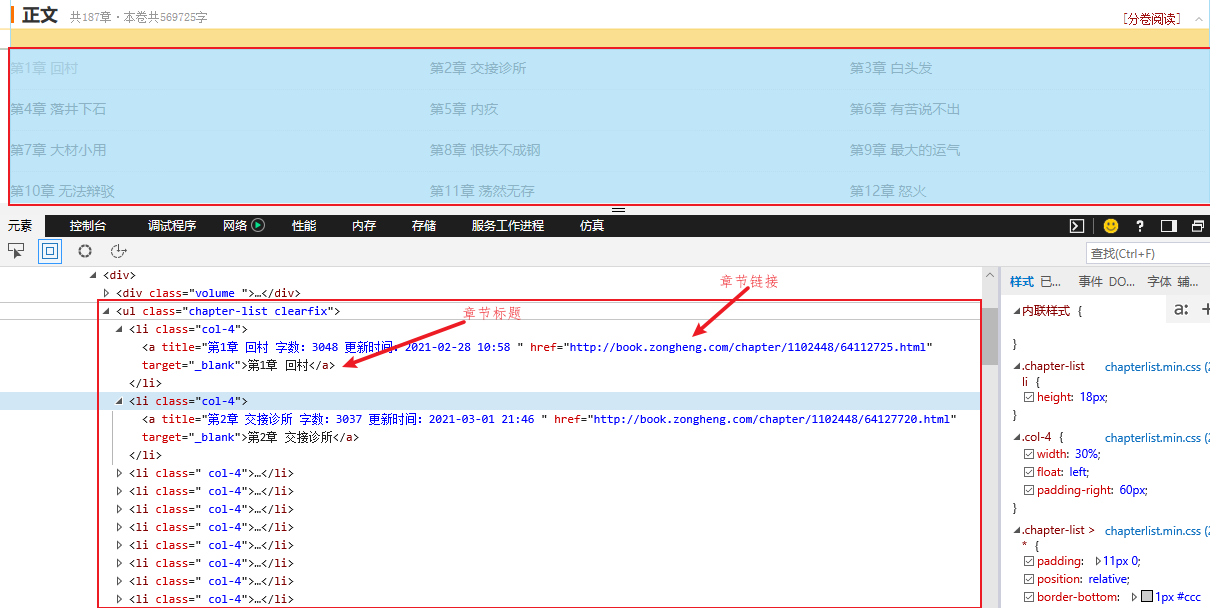
1. 章节目录分析
通过浏览器自带的开发人员工具【快捷键F12或Ctrl+Shift+I】进行分析,发现所有的章节都包含在ul【无序列表标签】中,每一个章节链接对应于li【列表项目标签】标签中的a【超链接标签】标签,其中a标签的href属性就是具体章节网址,a标签的文本就是章节标题,如下所示:
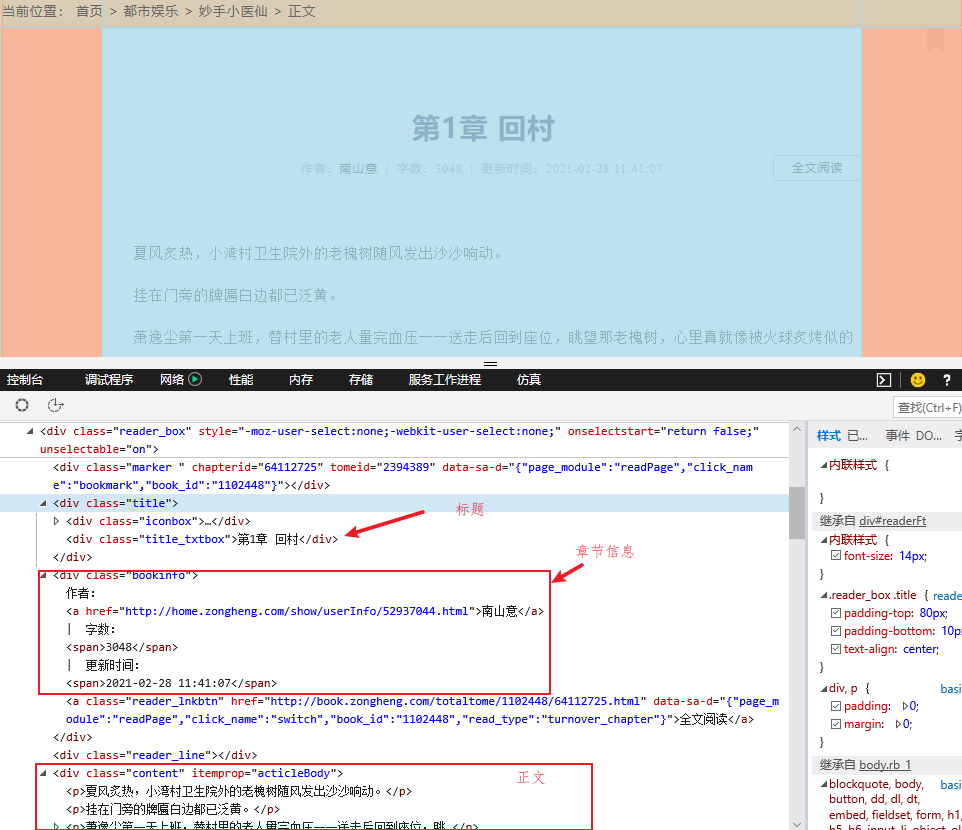
2. 章节正文分析
通过分析,发现章节全部内容,均在div【class=reader_box】中,其中包括标题div【class=title_txtbox】,章节信息div【class=bookinfo】,及正文信息div【class=content】,所有正文包含在p【段落标签】中。如下所示:
爬虫设计思路
- 获取章节页面内容,并进行解析,得到章节列表
- 循环章节列表:
- 获取每一章节内容,并进行解析,得到正文内容,
- 保存到文本文档。每一个章节,一个文档。
示例源码
获取请求页面内容,因为本例需要多次获取页面内容,所以封装为一个单独的函数,如下所示:
1 def get_data(url: str = None): 2 """ 3 获取数据 4 :param url: 请求网址 5 :return:返回请求的页面内容 6 """ 7 # 请求头,模拟浏览器,否则请求会返回418 8 header = { 9 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' 10 'Chrome/70.0.3538.102 Safari/537.36 Edge/18.18363'} 11 resp = requests.get(url=url, headers=header) # 发送请求 12 13 if resp.status_code == 200: 14 if resp.encoding != resp.apparent_encoding: 15 # 如果返回的编码和页面显示编码不一致,直接获取text会出现乱码,需要转码 16 return resp.content.decode(encoding=resp.apparent_encoding) 17 else: 18 # 如果返回成功,则返回内容 19 return resp.text 20 else: 21 # 否则,打印错误状态码,并返回空 22 print('返回状态码:', resp.status_code) 23 return
注意:有可能不同网站,返回内容的编码和页面显示的编码不一致,可能会出现中文乱码的情况,所以本例进行编码设置。
1. 解析章节列表
要获取整本小说内容,首先就要获取章节列表,然后保存到内存数组中,以便于获取具体正文。如下所示:
1 def parse_chapters(html: str = None): 2 """ 3 爬取章节列表 4 :param html: 5 :return: 6 """ 7 if html is None: 8 return 9 else: 10 chapters = [] 11 bs = BeautifulSoup(html, features='html.parser') 12 ul_chapters = bs.find('ul', class_='chapter-list clearfix') 13 # print(ul_chapters) 14 li_chapters = ul_chapters.find_all('li', class_='col-4') # 此处需要注意,页面源码查看是有空格,但是BeautifulSoup转换后空格消失 15 for li_chapter in li_chapters: 16 a_tag = li_chapter.find('a') 17 # print(a_tag) 18 a_href = a_tag.get('href') # 此处也可以用a_tag['href'] 19 a_text = a_tag.get_text() # 获取内容:章节标题 20 chapters.append({'title': a_text, 'href': a_href}) 21 22 return chapters
2. 解析单个章节
当得到单个章节的链接时,就可以获取单个章节的内容,并进行解析,如下所示:
1 def parse_single_chapter(html: str = None): 2 """ 3 解析单个章节内容 4 :param html: 5 :return: 6 """ 7 bs = BeautifulSoup(html, features='html.parser') 8 div_reader_box = bs.find('div', class_='reader_box') 9 div_title = div_reader_box.find('div', class_='title_txtbox') 10 title = div_title.get_text() # 获取标题 11 div_book_info = div_reader_box.find('div', class_='bookinfo') 12 book_info = div_book_info.get_text() 13 div_content = div_reader_box.find('div', class_='content') 14 content = '' 15 p_tags = div_content.find_all('p') 16 for p_tag in p_tags: 17 content =content + p_tag.get_text() + '\r\n' 18 # content = div_content.get_text() 19 return title + '\n' + book_info + '\n' + content
3. 循环解析并保存
循环获取单个章节正文页面,并进行解析,然后保存。如下所示:
1 def get_and_parser_single_chapter(chapters: list = []): 2 """ 3 获取单个章节 4 :param chapters: 章节列表 5 :return: 6 """ 7 for (index, chapter) in enumerate(chapters, 1): 8 title = chapter.get('title') 9 href = chapter.get('href') 10 while True: 11 print('开始第%d章爬取' % index) 12 html = get_data(href) 13 if html is not None: 14 content = parse_single_chapter(html) 15 save_data(title, content) # 保存数据 16 print('第%d章爬取成功' % index) 17 break 18 else: 19 print('第%d章爬取失败' % index) 20 time.sleep(2)
4. 整体调用逻辑
当写好单个功能函数时,顺序调用就是完整的爬虫,如下所示:
1 url = 'http://book.abcde.com/showchapter/1102448.html' 2 print('开始时间>>>>>', time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())) 3 html_chapters = get_data(url) 4 chapters = parse_chapters(html_chapters) 5 get_and_parser_single_chapter(chapters) 6 print('结束时间>>>>>', time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())) 7 print('done')
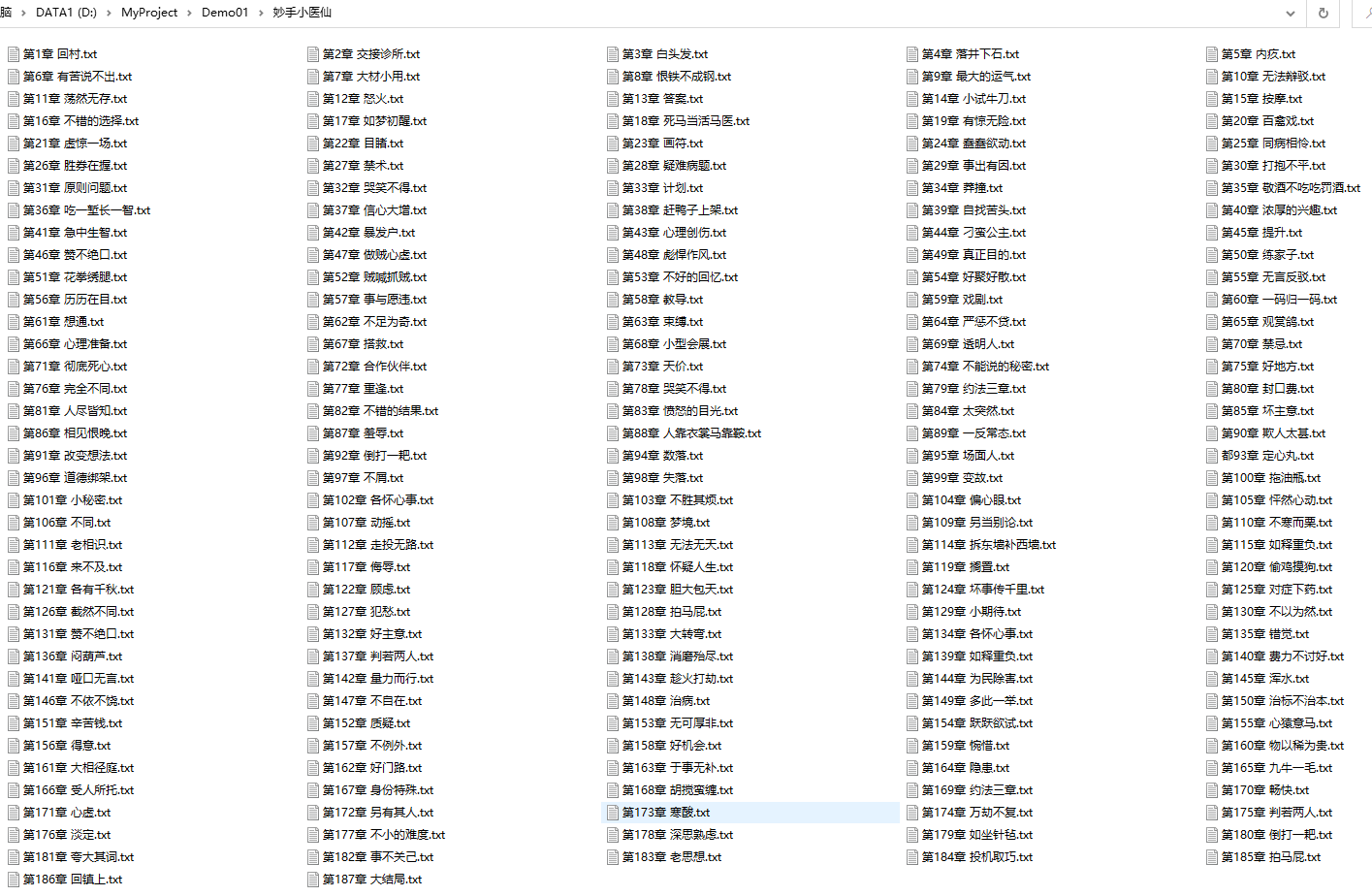
示例截图
爬取到的小说列表,如下所示:
每一个章节内容,如下所示:
示例完整代码,如下所示:


1 import requests # 请求包 用于发起网络请求 2 from bs4 import BeautifulSoup # 解析页面内容帮助包 3 import time 4 5 """ 6 说明:爬取小说 7 步骤:1. 先爬取所有章节,及章节明细对应的URL 8 2. 解析单个章节的内容 9 3. 保存 10 """ 11 12 13 def get_data(url: str = None): 14 """ 15 获取数据 16 :param url: 请求网址 17 :return:返回请求的页面内容 18 """ 19 # 请求头,模拟浏览器,否则请求会返回418 20 header = { 21 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' 22 'Chrome/70.0.3538.102 Safari/537.36 Edge/18.18363'} 23 resp = requests.get(url=url, headers=header) # 发送请求 24 25 if resp.status_code == 200: 26 if resp.encoding != resp.apparent_encoding: 27 # 如果返回的编码和页面显示编码不一致,直接获取text会出现乱码,需要转码 28 return resp.content.decode(encoding=resp.apparent_encoding) 29 else: 30 # 如果返回成功,则返回内容 31 return resp.text 32 else: 33 # 否则,打印错误状态码,并返回空 34 print('返回状态码:', resp.status_code) 35 return 36 37 38 def parse_chapters(html: str = None): 39 """ 40 爬取章节列表 41 :param html: 42 :return: 43 """ 44 if html is None: 45 return 46 else: 47 chapters = [] 48 bs = BeautifulSoup(html, features='html.parser') 49 ul_chapters = bs.find('ul', class_='chapter-list clearfix') 50 # print(ul_chapters) 51 li_chapters = ul_chapters.find_all('li', class_='col-4') # 此处需要注意,页面源码查看是有空格,但是BeautifulSoup转换后空格消失 52 for li_chapter in li_chapters: 53 a_tag = li_chapter.find('a') 54 # print(a_tag) 55 a_href = a_tag.get('href') # 此处也可以用a_tag['href'] 56 a_text = a_tag.get_text() # 获取内容:章节标题 57 chapters.append({'title': a_text, 'href': a_href}) 58 59 return chapters 60 61 62 def get_and_parser_single_chapter(chapters: list = []): 63 """ 64 获取单个章节 65 :param chapters: 章节列表 66 :return: 67 """ 68 for (index, chapter) in enumerate(chapters, 1): 69 title = chapter.get('title') 70 href = chapter.get('href') 71 while True: 72 print('开始第%d章爬取' % index) 73 html = get_data(href) 74 if html is not None: 75 content = parse_single_chapter(html) 76 save_data(title, content) # 保存数据 77 print('第%d章爬取成功' % index) 78 break 79 else: 80 print('第%d章爬取失败' % index) 81 time.sleep(2) 82 83 84 def parse_single_chapter(html: str = None): 85 """ 86 解析单个章节内容 87 :param html: 88 :return: 89 """ 90 bs = BeautifulSoup(html, features='html.parser') 91 div_reader_box = bs.find('div', class_='reader_box') 92 div_title = div_reader_box.find('div', class_='title_txtbox') 93 title = div_title.get_text() # 获取标题 94 div_book_info = div_reader_box.find('div', class_='bookinfo') 95 book_info = div_book_info.get_text() 96 div_content = div_reader_box.find('div', class_='content') 97 content = '' 98 p_tags = div_content.find_all('p') 99 for p_tag in p_tags: 100 content =content + p_tag.get_text() + '\r\n' 101 # content = div_content.get_text() 102 return title + '\n' + book_info + '\n' + content 103 104 105 def save_data(name, content): 106 """ 107 保存数据 108 :param name: 文件名 109 :param content: 文件内容 110 :return: 111 """ 112 with open('妙手小医仙\\' + name + '.txt', 'w', encoding='utf-8') as f: 113 f.write(content) 114 115 116 url = 'http://book.zongheng.com/showchapter/1102448.html' 117 print('开始时间>>>>>', time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())) 118 html_chapters = get_data(url) 119 chapters = parse_chapters(html_chapters) 120 get_and_parser_single_chapter(chapters) 121 print('结束时间>>>>>', time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())) 122 print('done')
备注
我从来不认为半小时是我微不足道的很小的一段时间。真正的强者,不是没有眼泪的人,而是含着眼泪奔跑的人。但行前路,无问西东 。
长相思·山一程
山一程,水一程,身向榆关那畔行,夜深千帐灯。
风一更,雪一更,聒碎乡心梦不成,故园无此声。
 作者:老码识途
作者:老码识途
出处:http://www.cnblogs.com/hsiang/
本文版权归作者和博客园共有,写文不易,支持原创,欢迎转载【点赞】,转载请保留此段声明,且在文章页面明显位置给出原文连接,谢谢。
关注个人公众号,定时同步更新技术及职场文章

 浙公网安备 33010602011771号
浙公网安备 33010602011771号