“GIS DICTIONARY A-Z” 查询页面开发(1)——bs4与词典数据处理
第一天的工作:找到数据源,数据下载,数据处理。
数据源:"http://webhelp.esri.com/arcgisserver/9.3/java/geodatabases/definition_frame.htm"。
数据下载:右击网页另存为。
数据处理:bs4 + 对比观察 + chrome检查元素 + 写function写方法
一、bs4部分
from bs4 import BeautifulSoup soup = BeautifulSoup(open('GIS_dictionary.html','r',encoding='UTF-8'),features="lxml") #tag标签 GlossaryTerm_list = soup.find_all(attrs={'class':'GlossaryTerm'})#完整,1729个 Definition_list = soup.find_all(attrs={'class':'Definition'})#缺<ol>
二、对比观察 + 检查元素
在准备GlossaryTerm和Definition的一一对应时发现二者的数量对不上。观察分析后确定是网站的前端代码对不同形式的Definition有不同的处理方法:对有多项释义的词汇使用了<ol>有序列表,它不能直接被bs4的属性查找选择到。
三、写方法
第一块:因为词组和解释在同一前端代码段内,故使用".text"和".a.attrs['name']"完成第一部分的对应。
''' 完成Definition_list中已有的1610个解释的文本获取和词语对应 ''' defList = [] for i in Definition_list: defi = i.text.strip('\n')#修饰definition word = i.a.attrs['name'].replace('_',' ')#修饰glossary defList.append([defi,word]) #抓取所有解释和词语在小列表,再存入大列表 if (i.text==''): #确保没有definition为空 print(i.a.attrs['name']) #defList示例[["defi",'word'],["",''],["",''],["",'']...]
第二块:定义函数func_n(),清洗<ol>标签内的数据。其中使用了通过中间媒介list修改string的技巧和if筛查的方法。最后对应词组和相应的解释,完成项目的数据准备工作。明日计划:数据库。
''' <ol>标签,将defList补充完整,从Ctrl+F得到共有119个<ol>标签 "1610+119=1729",成功!1729 == len(GlossaryTerm_list) ''' #定义函数func_n #格式化<ol>的definition:首位加"1.";将多个连续的"\n"收为一个;在"\n"后添加"2."等序号 def func_n(txt): lstTxt = list(txt) #因为不能直接修改string,故将其打碎为list进行操作 n = len(lstTxt) newlstTxt = ["1."] #添加首位的"1." count = 2 for i in range(n-1): if lstTxt[i]=='\n' and lstTxt[i]!=lstTxt[i+1] and lstTxt[i+1]!=' ': #保留单独的"\n",在其后添加序号;排除'\n'+' '的组合 newlstTxt.append('\n') newlstTxt.append(str(count)) newlstTxt.append('.') count += 1 if lstTxt[i]!='\n' and lstTxt[i]!=lstTxt[i+1] and lstTxt[i]!='\t': #放弃连续多个的"\n"、放弃所有的'\t' newlstTxt.append(lstTxt[i]) newlstTxt.append(lstTxt[-1]) #添加for循环里没有的最后一位 strTxt = ''.join(newlstTxt) #''.join()函数将list变为string return strTxt #实操 ol_list = soup.find_all('ol') for j in ol_list: defi_ol = j.text.strip('\n') defi_ol = func_n(defi_ol) word_ol = j.a.attrs['name'].replace('_',' ') defList.append([defi_ol,word_ol])
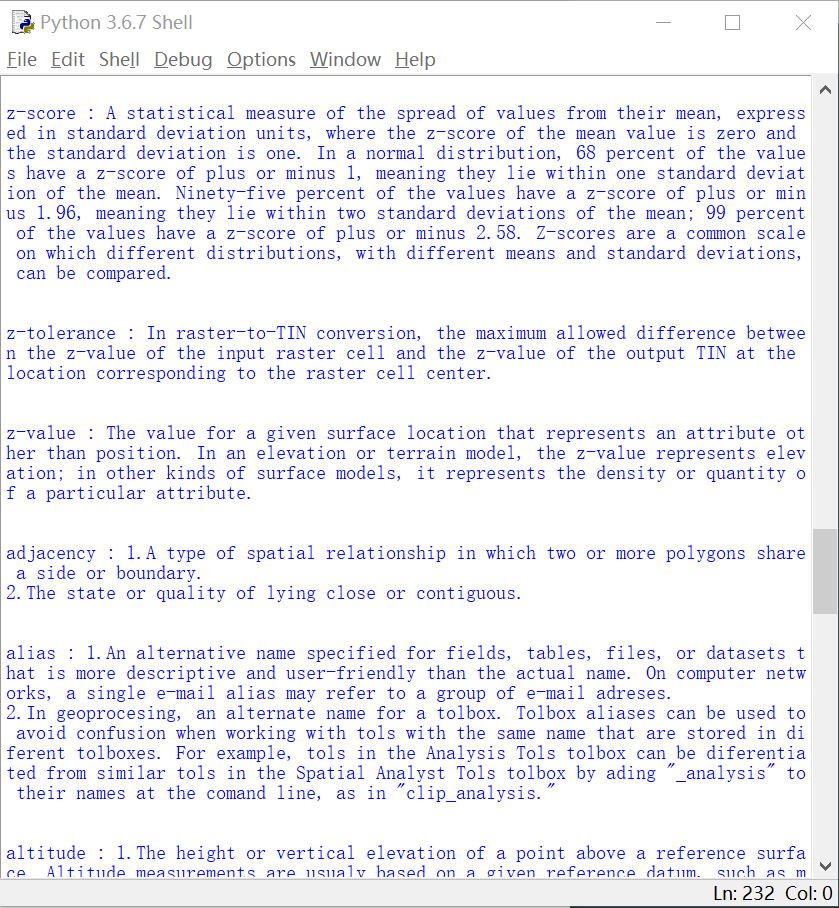
词典数据效果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号