
python基础编程:生成器、迭代器、time模块、序列化模块、反序列化模块、日志模块
目录:
- 生成器
- 迭代器
- 模块
- time
- 序列化
- 反序列化
- 日志
一、生成器
列表生成式;
a = [1,2,3,3,4,5,6,7,8,9,10] a = [i+1 for i in a ] print(a) a = [i*1 if i > 5 else i for i in a] print(a)
生成器:generator
不能事先把元素全部加载到内存,可以是边使用边生成的方式来依次获取元素;
生成器的使用方法:
列表生成式生成的是列表;
将列表生成器中的[]改成()就成为了一个生成器;
示例:
a = [1,2,3,3,4,5,6,7,8,9,10] a = (i+1 for i in a) 生成器的取值方法: 使用next next(a)或a.__next__()
函数一经调用必须执行完毕,中间不可停顿;生成器可解决这个问题;生成器yield保存了函数的中断状态;yield即可以中断也可以传参数;
生成器这种边执行边运算的方法被称为惰性运算;
next:只能唤醒不能传值;
send:即能唤醒又能传值;
在多个函数中不断切换来实现并发;
串行下实现并发示例:
代码:
import time
def cost(name):
print('%s 准备吃包子'%name)
while True:
baozi = yield
print('包子 [%s] 来了,被 [%s] 吃了'%(baozi,name))
def pro():
c = cost('jerry')
c1 = cost('tom')
c.__next__()
c1.__next__()
print('开始做包子')
for i in (range(10)):
time.sleep(0.5)
print('做了 %s 个包子'%i)
c.send(i)
c1.send(i)
pro()
运行结果:
jerry 准备吃包子
tom 准备吃包子
开始做包子
做了 0 个包子
包子 [0] 来了,被 [jerry] 吃了
包子 [0] 来了,被 [tom] 吃了
做了 1 个包子
包子 [1] 来了,被 [jerry] 吃了
包子 [1] 来了,被 [tom] 吃了
做了 2 个包子
包子 [2] 来了,被 [jerry] 吃了
包子 [2] 来了,被 [tom] 吃了
做了 3 个包子
包子 [3] 来了,被 [jerry] 吃了
包子 [3] 来了,被 [tom] 吃了
做了 4 个包子
包子 [4] 来了,被 [jerry] 吃了
包子 [4] 来了,被 [tom] 吃了
做了 5 个包子
包子 [5] 来了,被 [jerry] 吃了
包子 [5] 来了,被 [tom] 吃了
做了 6 个包子
包子 [6] 来了,被 [jerry] 吃了
包子 [6] 来了,被 [tom] 吃了
做了 7 个包子
包子 [7] 来了,被 [jerry] 吃了
包子 [7] 来了,被 [tom] 吃了
做了 8 个包子
包子 [8] 来了,被 [jerry] 吃了
包子 [8] 来了,被 [tom] 吃了
做了 9 个包子
包子 [9] 来了,被 [jerry] 吃了
包子 [9] 来了,被 [tom] 吃了
我们创建了一个generator后,基本上永远不会调用next(),而是通过for循环来迭代它,并且不需要关心StopIteration的错误。
generator非常强大。如果推算的算法比较复杂,用类似列表生成式的for循环无法实现的时候,还可以用函数来实现。
比如,著名的斐波拉契数列(Fibonacci),除第一个和第二个数外,任意一个数都可由前两个数相加得到:
1, 1, 2, 3, 5, 8, 13, 21, 34, ...
斐波拉契数列用列表生成式写不出来,但是,用函数把它打印出来却很容易:
执行代码:
def fib(max):
n,a,b=0,0,1
while n < max:
yield b
a,b=b,a+b
n+=1
return 'done'
f=fib(10)
print(f.__next__())
print(f.__next__())
print(f.__next__())
print(f.__next__())
print(f.__next__())
print(f.__next__())
print(f.__next__())
print(f.__next__())
print(f.__next__())
print(f.__next__())
执行结果:
1
1
2
3
5
8
13
21
34
55
二、迭代器
可以直接作用于for循环的对象统称为可迭代对象;Iterable 所谓可迭代就是可循环、可遍历;
可以使用isinstance()判断一个对象是否是Iterable对象;
生成器即可以for循环,又可以被next()不断调用返回下一个值;
可以被next()方法 调用并不断返回下一个值的对象称为迭代器;Iterator; 可迭代对象只能循环,迭代器即可循环又可以被next;
可以说所有的生成器就是迭代器,但迭代器不仅限制为生成器;迭代器的一个判断条件是只要可以被next就是一个迭代器;
生成器是迭代器的子集;
生成器都是迭代器对象,但list、dict、str虽然是可迭代(Iterable),却不是迭代器(Iterator)
示例:
>>> from collections import Iterable
>>> isinstance([],Iterable)
True
>>> isinstance((),Iterable)
True
>>> isinstance({},Iterable)
True
>>> isinstance(100,Iterable)
False
# python3中的for循环range,range都是迭代器;
三、模块
代码的级别:
函数 --》类 --》模块 --》包
模块分为三种:
自定义模块;
内置标准模块(又称标准库);自带200多个标准库;
开源模块;
模块安装:
pip install 模块名 即可下载安装;
python官方开源库
pypi.python.org/pypi
1、时间模块
import time
print(time.time) #返回时间戳;从1970年1月1日开始至现在计时;
print(time.altzone) #查看格林威治标准时间;
-32400
print(time.altzone/60/60)
-9.0
print(time.asctime()) #返回时间格式;
Sat Feb 18 15:12:02 2017
print(time.localtime()) #返回本地时间的struct time对象格式;
time.struct_time(tm_year=2017, tm_mon=2, tm_mday=18, tmhour=15, tm_min=12, tm_sec=43, tm_wday=5, tm_yday=49, tm_isdst=0)
t = time.localtime(time.time() - (60*60*24))
print('t',t)
t time.struct_time(tm_year=2017, tm_mon=2, tm_mday=17, tm_hour=15, tm_min=21, tm_sec=1, tm_wday=4, tm_yday=48, tm_isdst=0)
t = time.localtime()
print(t.tm_year,t.tm_mon)
2017 2
print(time.gmtime()) #返回utc时间的struc时间对象格式;即英国时间;
time.struct_time(tm_year=2017, tm_mon=2, tm_mday=18, tm_hour=7, tm_min=14, tm_sec=39, tm_wday=5, tm_yday=49, tm_isdst=0)
print(time.ctime()) #打印当前时间;
Sat Feb 18 15:22:18 2017
自定义时间格式:
print(time.strftime('%Y-%m-%d %H:%M:%S'))
2017-02-18 15:24:15
显示一天前的时间:
struct_time = time.localtime(time.time() - 86400)
print(time.strftime('%Y-%m-%d %H:%M:%S',struct_time))
2017-02-17 15:27:03
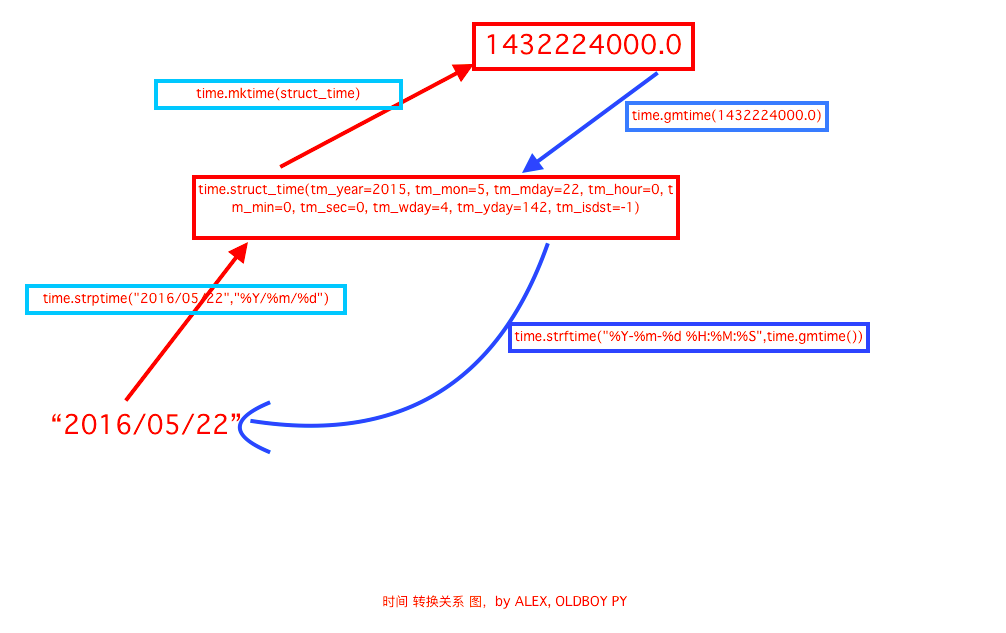
将字符串转成时间;
print(time.strptime("2017-02-17","%Y-%m-%d"))
time.struct_time(tm_year=2017, tm_mon=2, tm_mday=17, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=4, tm_yday=48, tm_isdst=-1) #变成时间对象;
字符串转成时间戳:
s_time = time.strptime("2017-02-17","%Y-%m-%d"))
print(time.mktime(s_time))
s_time = time.strptime("2017-02-17","%Y-%m-%d")) --> time.mktime(struct_time)
时间戳车成字符串:
time.gmtime(143322224000) --> time.strftime("%Y-%m-%d %H:%M:%S",time.gmtime())
import datetime
print(datetime.datetime.now()) #打印当前时间;
print(datetime.date.fromtimestramp(time.time())) #时间戳直接转成日期格式;
缺点:没有办法定制时间格式;
print(datetime.datetime.now() + datetime.timedalta(3)) #直接加三天;
print(datetime.datetime.now() + datetime.timedalta(hours=3,minutes=-20)) #加三天,再减20分钟
c_time = datetime.datetime.now()
print(c_time.replace(minute=3,hour=2))
或
print(datetime.datetime.now().replace(year=2016,month=3)) #时间替换;
| Directive | Meaning | Notes |
|---|---|---|
%a |
Locale’s abbreviated weekday name. | |
%A |
Locale’s full weekday name. | |
%b |
Locale’s abbreviated month name. | |
%B |
Locale’s full month name. | |
%c |
Locale’s appropriate date and time representation. | |
%d |
Day of the month as a decimal number [01,31]. | |
%H |
Hour (24-hour clock) as a decimal number [00,23]. | |
%I |
Hour (12-hour clock) as a decimal number [01,12]. | |
%j |
Day of the year as a decimal number [001,366]. | |
%m |
Month as a decimal number [01,12]. | |
%M |
Minute as a decimal number [00,59]. | |
%p |
Locale’s equivalent of either AM or PM. | (1) |
%S |
Second as a decimal number [00,61]. | (2) |
%U |
Week number of the year (Sunday as the first day of the week) as a decimal number [00,53]. All days in a new year preceding the first Sunday are considered to be in week 0. | (3) |
%w |
Weekday as a decimal number [0(Sunday),6]. | |
%W |
Week number of the year (Monday as the first day of the week) as a decimal number [00,53]. All days in a new year preceding the first Monday are considered to be in week 0. | (3) |
%x |
Locale’s appropriate date representation. | |
%X |
Locale’s appropriate time representation. | |
%y |
Year without century as a decimal number [00,99]. | |
%Y |
Year with century as a decimal number. | |
%z |
Time zone offset indicating a positive or negative time difference from UTC/GMT of the form +HHMM or -HHMM, where H represents decimal hour digits and M represents decimal minute digits [-23:59, +23:59]. | |
%Z |
Time zone name (no characters if no time zone exists). | |
%% |
A literal '%' character. |
2、随机模块 import random print(random.randint(1,10)) 6 生成随机数; print(random.randrange(1,20,2)) 不包含10,可以加步长;会跳着显示; print(random.sample([1,2,3,4,5,6,7],2)) #随机取两个值; [3, 1] print(random.sample(range(100),5)) #随机取五个值; [2, 3, 7, 5, 1] print(string.ascii_lowercase) #打印所有小写 print(string.digits) print(string.upper)
示例:
生成随机验证码
import random
checkcode = ''
for i in range(4):
current = random.randrange(0,4)
if current != i:
temp = chr(random.randint(65,90))
else:
temp = random.randint(0,9)
checkcode += str(temp)
print checkcode
3、系统模块
import os
os.getcwd()
os.chdir('dirname') #切换目录;
os.chdir('/')
os.curdir: 返回当前目录;
os.mkedirs('dir/dir',exist_ok=True) #创建多级目录;
os.removedirs('dirname') #删除目录
os.listdirs('dirname') #列出当前目录下文件夹
os.stat('zip_test.zip') #列出文件详细信息;
os.stat('zip_test.zip').st_size #取出文件大小;
os.sep #输出操作系统特定的路径分隔符;可动态拼路径;
os.linesep #打印当前平台使用的行终止符;
\r\n
os.pathsep #分隔文件路径的字符串;
os.name #输出字符串指示当前使用秤台;
os.system('df') #运行命令;
a = os.popen('df').read
print(a)
os.system只返回命令的执行结果的状态;
os.popen('df').read #可以拿到命令的执行结果;
os.path.abspath(__file__) #返回一个文件的绝对路径;
os.path.split(path) #将path分割成目录和文件名二元组返回;
print(os.path.split(file_path))
os.path.dirname(file_path) #显示上一级目录名;
print(os.path.dirname(file_path))
os.system('ipconfig') #运行shell命令;
os.path.basename(file_path) #取基名;
os.path.exists(path) #判断是否存在;
print(os.path.join('c:\/','programs','python27')) #路径的拼接;
4、平台模块
import platform
platform.platform() #显示当前平台;
platform.system() #判断是什么操作系统;
Windows
5、sys模块
import sys
sys.argv
sys.exit(n) #sys.exit() == exit()
sys.exit('jfkldjsl') 参数的传入;
sys.path #返回python的整个环境变量;
sys.maxsize #最大的Int值;
sys.platform #显示系统平台名称;
sys.stdout(n) #标准输出到屏幕;
print(sys.stdout('fjsdklj'))
a = sys.stdin.readline()
print(a)
6、用于序列化的两个模块
- json,用于字符串 和 python数据类型间进行转换
- pickle,用于python特有的类型 和 python的数据类型间进行转换
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
文件写入只能接受:字符串、bytes
序列化:pickle.dumps
内存 --》 字符串
反序列化:pickle.loads
字符串 --》 内存
import pickle
f = open('account.db','wb')
print(pickle.dumps(account))
f.write(pickle.dumps(account))
f.close
f = open('account.db','rb')
account=pickle.loads(f.read())
print(account['id'])
import json
两个程序之间的内存不能共享;
json只支持str、int、float、set、dict、list、tuple
pickle只有python支持,只是适用于python自己的;
json是一个通用的序列化的格式,可以在各开发程序中使用;
7、日志模块
import logging
五个日志级别:
debug()、info()、warning()、error()、critical()
logging.warning
logging.warning("user [alex] attempted wrong password more than 3 times")
logging.critical("server is down")
logging.basiConfig(filename='example.log',level=logging.INFO) #达到level后写入文件;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号