Apache Storm技术实战之3 -- TridentWordCount
欢迎转载,转载请注明出处。
介绍TridentTopology的使用,重点分析newDRPCStream和stateQuery的实现机理。
使用TridentTopology进行数据处理的时候,经常会使用State来保存一些状态,这些保存起来的State通过stateQuery来进行查询。问题恰恰在这里产生,即对state进行更新的Stream和尔后进行stateQuery的Stream并非同一个,那么它们之间是如何关联起来的呢。
在TridentTopology中,有一些Processor可能会同处于一个Bolt中,这些Processor形成一个processing chain, 那么Tuple又是如何在这些Processor之间进行传递的呢。
TridentWordCount
编译和运行
lein compile storm.starter.trident.TridentWordCount java -cp $(lein classpath) storm.starter.trident.TridentWordCount
main函数
public static void main(String[] args) throws Exception { Config conf = new Config(); conf.setMaxSpoutPending(20); if (args.length == 0) { LocalDRPC drpc = new LocalDRPC(); LocalCluster cluster = new LocalCluster(); cluster.submitTopology("wordCounter", conf, buildTopology(drpc)); for (int i = 0; i < 100; i++) { System.out.println("DRPC RESULT: " + drpc.execute("words", "cat the dog jumped")); Thread.sleep(1000); } } else { conf.setNumWorkers(3); StormSubmitter.submitTopology(args[0], conf, buildTopology(null)); } }
buildTopology
public static StormTopology buildTopology(LocalDRPC drpc) { FixedBatchSpout spout = new FixedBatchSpout(new Fields("sentence"), 3, new Values("the cow jumped over the moon"), new Values("the man went to the store and bought some candy"), new Values("four score and seven years ago"), new Values("how many apples can you eat"), new Values("to be or not to be the person")); spout.setCycle(true); TridentTopology topology = new TridentTopology(); TridentState wordCounts = topology.newStream("spout1", spout).parallelismHint(16).each(new Fields("sentence"), new Split(), new Fields("word")).groupBy(new Fields("word")).persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count")).parallelismHint(16); topology.newDRPCStream("words", drpc).each(new Fields("args"), new Split(), new Fields("word")).groupBy(new Fields( "word")).stateQuery(wordCounts, new Fields("word"), new MapGet(), new Fields("count")).each(new Fields("count"), new FilterNull()).aggregate(new Fields("count"), new Sum(), new Fields("sum")); return topology.build(); }
示意图
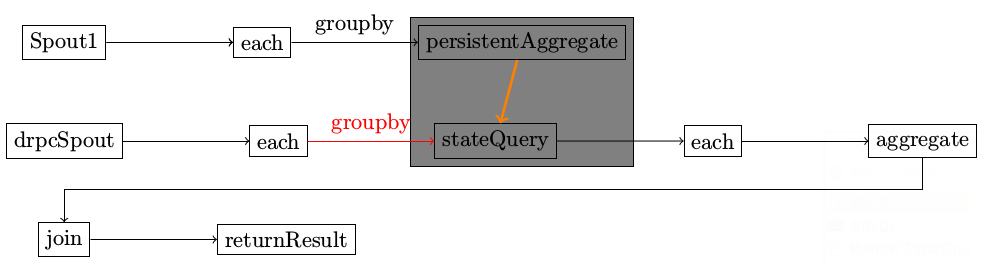
在整个topology中,有两个不同的spout。
运行结果该如何理解
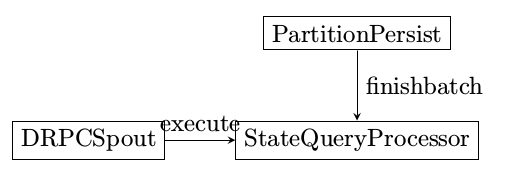
此图有好几个问题
- PartitionPersistProcessor和StateQueryProcessor同处于一个bolt,该bolt为SubtopologyBolt
- SubtopologyBolt有来自多个不同Stream的输入,根据不同的Streamid找到对应的InitialReceiver
- drpcspout在执行的时候,是一直不停的emit消息到SubtopologyBolt,还是发送完一次消息就停止发送
不同的tuple,其sourcestream不一样,根据SourceStream,找到对应的InitialReceiver
Map<String, InitialReceiver> _roots = new HashMap();
状态更新
进行状态更新的Processor名为PartitionPersistProcessor
execute
记录哪些tuple需要进行状态更新
finishBatch
状态真正更新是发生在finishBatch阶段
persistentAggregate
PartitionPersistProcessor
- SubtopologyBolt::execute
- PartitionPersistProcessor::finishBatch
- _updater::updateState
- Snapshottable::update
- _updater::updateState
- PartitionPersistProcessor::finishBatch
当状态更新的时候,状态查询是否会发生?
状态查询
进行状态查询的Processor名为StateQueryProcessor
execute
finishBatch
查询的时候,首先调用batchRetrieive来获得最新的状态更新结果,再对每个最新的结果使用_function来进行处理。
调用层次
- SubtopologyBolt::finishBatch
- StateQueryProcessor::finishBatch
- _function.batchRetrieve
- _function.execute 将处理过的结果发送给下一跳进行处理
- StateQueryProcessor::finishBatch
消息的传递
TridentTuple
如何决定bolt内部的哪个processor来处理接收到的消息,这个是根据不同的Stream来判断InitialReceiver完成。
当SubtopologyBolt接收到最原始的tuple时,根据streamid找到InitialReceiver后,InitialReceiver在receive函数中作的第一件事情就是根据tuple来创建一个tridenttuple,tridenttuple会被处在同一个SubtopologyBolt中的processor一一处理,处理的结果是保存在tridenttuple和processorcontext中。
ProcessorContext
ProcessorContext记录两个重要的信息,即当前的batchId和batchState.
public class ProcessorContext { public Object batchId; public Object[] state; public ProcessorContext(Object batchId, Object[] state) { this.batchId = batchId; this.state = state; } }
TridentCollector
tridentcollector在emit的时候将消息由各个TupleReceiver进行处理。目前仅有BridgeReceiver实现了该接口。
BridgeReceiver负责将消息发送给另外的Bolt进行处理。这里说的“另外的Bolt”是指Vanilla Topology中的Bolt.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号