好用的东西1
康复训练
1 Byte = 8 bit
- && 运算,当前面为0时,后面则不进行计算,发生短路
- || 运算,当前面为1时,后面则不进行计算,发生短路
位运算
与and,&,或or,|,非not,~,异或xor,^
在 位二进制数中,最低位为 0 位,最高位为 位
原码:指一个二进制数左边加上符号位后所得的码,且当二进制数大于 0 时,符号位为 0,二进制数小于 0 时符号位为 1
反码:正数的反码和原码相同,负数的反码是对其原码按位取反,但符号位除外
补码:正数的补码和原码相同,负数的补码是其对应正数按位取反再+1
https://www.luogu.com.cn/blog/chengni5673/er-jin-zhi-yu-wei-yun-suan
加减运算>移位运算>比较大小运算>与运算>异或运算>或运算
unsigned int
直接把 32 位编码看成 32 位二进制数
int
最高位为 符号位 ,0 代表正数, 1 代表负数
对于最高位为 0 的每种编码 ,可以直接看成二进制数 的值
对于最高位为 1 的每种编码,定义数值为按位取反后
可以发现,任意两个数做加减运算,都等价与 在补码下做最高位不进位的二进制加减运算,这相当于自动对 取模
进制转换
十六进制 (0x),每个字符代表 4个二进制位,0x3f3f3f3f=1e9,0x7fffffff 是 int 能表示的最大整数
memset的原理是把val的数值填充到目标元素的每个字节上
移位运算
算术右移:二进制补码向右移动,高位以符号位填充,高位越界后舍弃。
如
n>>1 = ,值得注意的是 C++ 实现的是 向0取整而并非向下取整
逻辑右移:高位以 0 填充,低位越界后舍弃。
一般得编译器的右移均是算术右移。
龟速幂
求 的结果,其中
我们可以快速幂的思想,即 ,因为 ,且这个式子在 long long 范围之内,故可以在 的复杂度内解决
据说有 的神秘做法,不管了。
Acwing998 起床困难综合症
选择一个 范的的整数 ,使得经过给定的 次位运算后,结果 最大。
位运算的主要特点是 二进制下不进位,于是位之间独立。我们可以贪心的从高位到低位考虑,在满足范围的前提下尽可能使这一位填 就行了。
二进制状态压缩
将一个长度为 m 的 bool 数组用一个 m 位的二进制数来存储。
这种方法运算简便,均使用位运算,节省了时间和空间。当 较大时,可以使用若干个 int 分段存储,也可以直接利用 stl 里的 bitset
Acwing91 最短 Hamilton 路径
法一:我们可以枚举全排列,计算长度取最小值。
经过每个点恰好一次,这启示我们用二进制数记录每个点的访问状态,具体地,设 为当前路径的终点为 ,路径上点的集合为 的最短哈密顿路径,枚举 的出边更新即可。由于转移的 是严格递增的,所以
成对变换
为偶数,。
为奇数,。
给结论经常用在无向图邻接表边集的存储中。
lowbit运算
二进制最低位 1
根据取反运算的性质,~,可得出
lowbit 运算配合 hash 可以找出 整数二进制下所有是 1 的位 ,所花费的时间与 的个数同级。
如果要求 lowbit(x) 的最高位 的位数,可以预处理一个数组,用 Hash 的方法代替 log 运算,当 较小时,最简单的方法是建立一个数组 ,令 。
稍微复杂但效率较高的方法是建立一个长度为 的数组 ,令 。这里利用了一个数学技巧: 互不相等,且恰好取遍
递归与递推
一个问题的各种情况的集合称为 状态空间,程序相当于对 状态空间 的遍历,通过 划分、归纳、提取、抽象 来提高效率。递归和递推式就是遍历状态空间的两种方式。
对于一个问题,在边界或特殊情况时答案是已知的。如果能将场景扩大到原问题的状态空间,并且扩展过程中的每个步骤具有相似性,就可以使用递归或者递推。
从 问题边界 向 原问题 正向推导的方式称为递推。当问题推导的路线难以确定,这时不断尝试把问题的规模缩小到问题边界的路线,并沿着缩小的路线回溯的遍历方式就是递归。
在每个变换步骤中执行三个操作:
- 缩小问题状态空间的规模
- 尝试求解规模缩小以后的问题
- 如果成功,即找到了规模缩小以后问题的答案,将答案扩展到当前问题。
自身调用自身,回溯时还原现场
常见枚举方式:
- 多项式 。循环、递推。
- 指数 。递归,位运算
- 排列 。递归,next_permutation
- 组合 。递归 + 剪枝
Acwing95 费解的开关
注意到开灯的顺序对答案没有影响的,所以我们可以钦定顺序,一步一步得关。
由于一个一个关限制太多,不妨考虑一行一行关。即先考虑第一行是怎么点的。
易发现,若固定了第一行的点完的状态是什么,剩下位置的方案就确定了,这个可以归纳的证明。
这题告诉我们一个问题无法入手可以找一个顺序,然后尝试边界的情况。
Acwing96 奇怪的汉诺塔
先考虑三个汉诺塔的情况,有 。
四个的话类似,我们只需要将 个塔分成两段,然后放到盘上,有递归式
分治
Acwing97 Sumdiv
Acwing99 激光炸弹
有
其实就是容斥原理,为节省空间,省略 数组,读入时直接往 里累加。
差分
给定序列 ,它的差分序列 定义为:
Acwing100 IncDec Sequence
求出 的差分序列 ,并令 。
每次对 操作,相当于每次选出 中的任意两个数,一个加 ,一个减 。目标是把 变为 ,最后得到的数列就是由 个 构成的。
操作只有 4 种,统计出 的正数和为 ,负数绝对值和为 ,那么先两两配对,尽可能执行第一次操作,可执行 ,剩余 个未配对,每个可以与 或 配对。
所以最少操作次数为 。能产生 种不同的 ,最终得到的序列 可能有这么多种。
二分
通过二分将求解转判定。
整数域上有三种写法:
while(l<r){ int mid=(l+r)>>1; if(P[mid]==1)r=mid;else l=mid+1; } while(l<r){ int mid=(l+r+1)>>1; if(P[mid]==1)l=mid;else r=mid-1; } while(l<=r){ int mid=(l+r)>>1; if(P[mid]==1)l=mid+1,ans=mid; else r=mid-1; }
实数域上的二分:
while(r-l>eps){ double mid=(l+r)/2; if(P[mid]==1)l=mid;else r=mid; }
二分答案
一个宏观的最优化问题可以抽象为函数,定义域是该问题下的可行方案,对这些可行方案进行评估得到的数值构成函数的值域,最优解就是评估值最优的方案(不妨设评分 越高越优)。对于 都不存在一个合法方案达到 分,否则就与 的最优性矛盾;而对于 ,一定存在一个合法方案达到或超过 分,因为最优解就满足这个条件,如果让评分为值域, ,则值域为 ,代表一个评分是否合法——在 的一侧合法,另一侧不合法,分段函数。可通过二分找到这个分界点 ,当 时向更大的 寻找, 时向左边找合法的 。
Acwing102
Acwing113
离散化
把无穷大的集合中的若干个元素映射为有限集合便于统计的方法,与数值的绝对大小无关,只与相对顺序有关。
中位数
Acwing104 货仓选址
将坐标排序,若选取的坐标为 ,其他 坐标 有 个, 的有 个。若 ,向右移动一格距离和会变小;若 ,向左移动会变小。若
如果有多个相同元素,可证明在所有不同的坐标中,排序后中位数所在的坐标一定最优,因为其他坐标都可以调整到这个位置。
Acwing105 七夕祭
对顶堆做法:我们维护两个堆:
- 大根堆:存储排名为 的元素
- 小根堆:存储排名为 的元素
插入一个数时,与堆顶比较,以 “对顶“ (保持序列有序性)为原则,插入到不同堆中。
如果存在一个时刻堆中元素过多,则不断弹出扔到另一个堆,直到满足上述性质。
k大数
快速排序 :
实际上我们可以利用快速排序的思想:每次随机选取一个数为基准,把比它大的数交换到右半段,自身和小于它的数交换到左半段。
在每次选出基准值之后统计小于基准值的数量 ,若 ,我们就在左半段寻找,若 就在右半段寻找 小的数(包含自身)
平均情况下为
逆序对
值得一提的是,逆序对个数等于冒泡排序的有效交换次数。实际上,冒泡排序实际上就是交换满足 的相邻逆序对达到每次操作逆序对个数减 1 ,最终有序。
排序算法 :
选择排序
每次找出第 小的元素,并与数组上的第 个位置交换
F(i,1,n){ F(j,i+1,n){ if(a[j]<a[i]){ swap(a[j],a[i]); } } }
冒泡排序
每次检查相邻两个元素,如果逆序就交换。当没有相邻元素需要交换时,数列就有序了。
经过 扫描后,第 大的数一定在倒数第 个位置上,因此最多 次扫描可完成排序
F(i,1,n-1){ bool ok=1; F(j,1,n-i){ if(a[j]>a[j+1]){ swap(a[j],a[j+1]); ok=0; } } if(ok)break; }
P1116 车厢重组
冒泡排序就是消除逆序对的过程,所以 交换相邻元素时排列有序的最少次数=逆序对数=冒泡排序交换次数。
插入排序
将序列分成 ”已排序“ 和 ”待排序“ 两部分,对于一个新加入的一个元素 ,在 这个有序的部分找到合适的位置后插入 。
F(i,1,n-1){ int now=a[i],k; D(j,i-1,1){ if(a[j]>now)a[j+1]=a[j]; else {k=j;break} } a[k+1]=now; }
计数排序
基于分类而并非基于比较
计算每个值的出现次数,最后按顺序输出每个值
F(i,1,n)b[a[i]]++; F(i,0,w){ while(b[i]>0)cout<<i<<' ',b[i]--; }
快速排序
分治
随机选取一个哨兵值,将小于等于哨兵值放在左半部分,大于等于的放在右侧,保持相对大小关系, 递归到两边,甚至都不用合并
开两个指针,从两边往中间扫,左边找第一个大于哨兵值的,右边找第一个小于哨兵值的,交换。
最坏 ,平均
基数排序
我们每次选择一个关键字,然后遍历整个序列,将每个数放入对应关键字的桶(实现为队列)里,沿用计数排序的思想,依次将桶里的元素取出。这样对于第 个关键字,满足序列已经按 关键字排好序了。
设序列的长度为 ,关键字个数为 ,大小为
时间 ,使用STL的话空间为 ,循环队列
优势
相对于计数排序,空间减少
相对于其他排序,时间优秀且适用于字符串
相对于字典树,空间上常数小
严格弱序
P1012 [NOIP1998 提高组] 拼数
二分查找
找到 成立的第一个位置
二分 mid,若 ,r=mid ,否则 l=mid+1
找到 成立的第一个位置
二分 mid,若 ,r=mid ,否则 l=mid+1
二分答案
一般套路:
- 原问题可以归纳或弱化成找到某命题 使得成立的最小/最大 的值
- 把 看成是一个 0/1 函数,有界且单调,即范围内存在一个分界点 ,一侧全为真,另一侧全为假
- 可以找到一个复杂度优秀的做法 判定 指定 的 的真假
P1873 [COCI 2011/2012 #5] EKO / 砍树
问题是求的是满足 、 的最大值。
是 单调的
P1824 进击的奶牛
该题与 跳石头 类似。
将原问题弱化成要求相邻两头牛的距离 ,求满足 最大的 值
这样的话若一个 是可行的,则 一定也是可行解,我们继续在右边找最优解就行了。
注意到 是 单调的,且分界点 的方案一定满足最短距离等于 。
P1024 [NOIP2001 提高组] 一元三次方程求解
根据题目性质,每个开区间 只存在一个零点
一个自然的想法是如果满足 直接对整个开区间进行 零点存在定理,但如果端点时零点的时候会漏情况。
所以我们只需要判断左端点是否为零点就行了。
P1020 导弹拦截(LIS)
求最长上升子序列长度,以及这个序列最少划分成若干个上升子序列的个数。
- probelm 1
设 代表考虑过前 个结点,以 号点为结尾的最长上升子序列长度。
显然, 号点可以作为开头也可以作为结尾,有
二分栈: 考虑优化,从值域和答案的角度考虑,设 为长度为 的上升子序列结尾数的高度最小为多少,注意到 是单增的,反证法:若存在一对 , 满足逆序关系,则 ,矛盾。
考虑加入一个点 ,用这个点去更新 。
如果 要作为结尾的话,需要满足 ,于是我们二分出最后一个 ,使得 ,这些 最后都可以接上 ,但只有 是有意义的。所以 。
- problem 2
考虑贪心,对于一个点 ,此时我们已经确定了 个子序列,将 接到一个高度尽可能大的序列更优。决策包容性证明,可参考 区间覆盖问题。
根据 Dirworth 定理,于是求最长非严格下降子序列即可。
哈斯图(Hasse 图)
对于 ,若 且不存在 使得 ,则称 为 的覆盖元素。我们在哈斯图中连一条 的有向边
例:以下为集合{1,2,3,4,6,8,12}按照整除的偏序关系形成的哈斯图
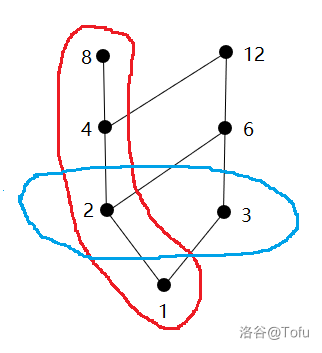
在哈斯图中,我们将较小元放在较大元下面,隐式地从底层往高层连有向边。
易发现,哈斯图中不存在回路(因为这样就不满足反对称性),所以哈斯图是一张 有向无环图!
红圈是一条链,蓝圈是一条反链。
Dilworth 定理
https://blog.csdn.net/qq_43408238/article/details/104542949
偏序集能够划分成最少的全序集个数 等于 最长反链的元素个数
偏序 :
定义集合 中的一个二元关系 ,譬如 和 两个二元组,定义 当且仅当 ,而若 则不满足偏序关系
当满足下面三个条件时, 就是一个 偏序集
- 自反性:
- 反对称性: ,若 ,则
- 传递性: ,若 ,则
全序集
设 为非空集合 的一个偏序关系。若对于 ,有 或 (即元素两两可比),则称 为一个全序集。
反链
若偏序集 中的元素两两不可比,则称 是反链。
证明:
先来证明 最小链覆盖 最长反链:
对于最长反链上的每一个点,都需要至少一条链覆盖它,且不存在一条链覆盖两个及以上的最长反链中的点。
再来证明 最小链覆盖 最长反链:
对 进行归纳
当 时,显然成立
假设该命题对 成立,下面证明对 成立
设 为一条最长反链,定义:
则
当 和 均非空时,因为 是 的最长反链,所以 是 的最长反链。根据假设,设 为最小链覆盖。同理,图 我们得到了 。由于 的极大元是 、 的极小元是 ,所以 对 的最小链覆盖
对于每一个 都有 或 为空时。那么 要么构成全上界,要么构成全下界。我们找到其中一对极小元和极大元 , 必构成一条链 ,因为 一定包含在全下界, 一定包含在全上界,所以 一定每个最长反链个数都为 ,对 归纳即可。
01背包
个物品,一个大小为 的背包,每个物品 有 大小 和价值 ,只有一件,问最大价值。
完全背包
个物品,一个大小为 的背包,每个物品 有 大小 和价值 ,有无限件,问最大价值。
每个 都是充分考虑了第 个物品的最优结果
对于 ,若满足 , 这样的偏序关系,则 可以完全抛弃。对于随机生成的数据,这个方法会大大减少物品件数,从而加快速度。但不能改变最坏复杂度。
转化为 01 背包问题求解:
由于每个物品其实最多选 件,于是我们可以二进制分组,即拆成 的形式,这是完全等价的。
多重背包
个物品,一个大小为 的背包,每个物品 有 大小 和价值 ,有 件,问最大价值。
二进制分组即可,拆成 ,可以组合成 里的所有数字
混合背包
拼拼乐
线性表
一个线性表由多个具有相同类型的数据串在一起,每个元素都具有前驱和后继。典型的线性表如:数组,链表,栈,队列。
数组
支持高效地存储与查询给定索引下的数据 。但是不能快速的进行 中间插入及删除、搜索指定元素、整体移位。
可变长度数组 :vector
栈
“后进先出”,支持在表中的一端进行插入和删除操作。
Acwing41 包含min函数的栈
没必要用堆做。但最小值不支持栈,这启发我们在维护栈时用一个线性结构保存历史上每一个时刻的最小值,这样就可以在出栈之后进行还原。插入时与上个时刻的最小值取 min 插入到末尾就行了。
Acwing128 编辑器
本题特殊点在于,所有操作都在光标位置处发生,并且操作完成后光标至多移动一个位置,只需要维护光标附近的关即可,其他大部分元素都没有改变。这个特征与对顶堆本质相同,这启发我们一个 对顶栈 的做法。
建立两个栈,为光标前后的所有元素,两个栈合并起来就保存了整个序列。因为查询操作的 不超过光标位置,所以我们再用一个数组 维护栈 前缀和的最大值就行了,光标移动时顺便修改。
法1:
设 为 个元素的出栈序列个数。考虑 元素出栈的时刻及在出栈序列中的位置,若排在 1 前面的数有 k 个,易得转移方程
法2:
设 为进栈的元素为 ,目前栈中只剩 个元素,剩下 个元素出栈序列的方案数
考虑下一步的操作,要么将栈顶取出插入序列尾部,要么将 加入栈中,有
法3:
等价于求第 项卡特兰数,即
单调栈
它是个 动态的,不要考虑它最后能长什么样子。
Acwing131 直方图中最大的矩形
先来思考这样一个问题:如果矩形的高度从左到右单调递增,那么我们可以尝试以每个矩形的高度作为最终矩形的高度,并把宽度延伸到右边界,得到一个矩形,所有这样的矩形面积最大值就是答案。
如果下一个矩形比上一个小,如果该矩形想要利用之前的矩形构成一块面积时,这块面积的高度就不能超过该矩形的高度。我们把这些矩形都删掉,用一个宽度增加、高度为该矩形自己新高度的矩形代替。这样并不会对后续的计算造成影响。于是我们维护的轮廓变成了一个高度始终单调递增的矩形序列。
单调栈的感性理解:
找到每一个数左边第一个比它小的元素:易发现如果对于 满足 ,那么对于 之后每个元素的答案, 一定不会产生贡献,所以对于这样的 就可以舍弃掉了。所以我们单调栈中存储元素的意义是所有可能在之后成为答案的序列,根据条件易得单调栈中的元素时单增的。当我们加入元素 时,我们要更新单调栈(更能成为答案的点)中的元素,将单调栈中的所有 的都删掉,由于是单增的,所以删除的一定是从栈顶开始的一段前缀,删除这些不可能的元素后,再将 放到栈顶,此时剩下的元素时可能的答案,又因为栈顶元素小于 ,所以这就是答案。相当于我们扫 ,动态维护一个数据结构。
这就是著名的单调栈算法,时间复杂度为 O(n) 。
借助单调性处理问题的思想在于 及时排除不可能选项,保持策略集合高度的有效性和秩序性。
UVA673 括号匹配
首先该题是括号匹配的定义为:
- 空串
- 如果 合法,则 合法
- 如果 合法,则 和 均合法
这样递归的定义告诉我们一个合法的串满足一个树形结构,这启发我们可以用栈解决。
此外,对于同一类括号,任意一个前缀的左括号数量都要不少于右括号数量,判断栈是否为空即可。
弹栈的时候可以这么理解:我们每匹配了一对括号的时候,就相当于把这一对括号 “擦掉”。
后缀表达式
构造方式如下,设 E 是一个合法的中缀表达式 :
- 若 E 是一个变量或常量,则 E’ = E
- 如果 E 是 E1 op E2 的形式,op 可以是任何二元运算符,则 E‘ = E1’E2’op
- 如果 E 是 (E1) 的形式,E’ = E1’
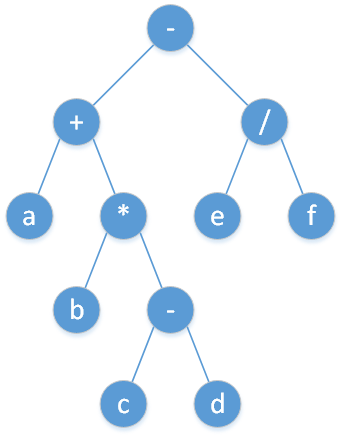
这是一个 表达式树, 叶子结点都是数字,非叶结点都是符号,且都是双目运算符。
如上表达式树的中缀表达式为 a+b*(c-d)-e/f ,后缀为 a.b.c.d.-*+e.f./-
我们可以猜到:中缀表达式对应着中序遍历,后缀表达式对应着后序遍历,即左儿子,右儿子,根,求值,这十分简单而直观!
计算后缀表达式:我们开一个栈,每次遇到数字就压入栈,遇到运算符就取出栈顶的两个元素,计算并将答案压入栈
后缀表达式还可以构建表达式树
判断一个过程能否用栈来模拟,可以考虑是否满足 “后进先出” 和 “先进后出”
链表与邻接表
数组支持随机访问,但不支持在任意位置插入或删除某个元素。与之相对应,链表支持在任意位置插入或删除元素,但只能按顺序访问其中的元素。我们用一个 struct 来表示链表中的节点,其中可以存储任意数据。另外用 prev 和 next 两个指针指向前后两个相邻的节点(双向链表)。为了避免在左右端或空链表中访问越界,我们通常建立 额外两个节点 head 与 tail 代表链头链尾 ,把实际数据节点存储在 head 与 tail 之间,减少链表边界处的判断。
链表的正规形式是通过动态分配内存、指针等实现,为了避免内存泄漏、方便调试,使用数组模拟链表、下标模拟指针也可以的。用数组模拟链表相当于把索引近似为存储空间,空间里保存该链表节点的信息,变量的值等于空间地址的就是指针
struct Node{ int val,pre,nxt; }node[N]; int head,tail,tot; void init(){ tot=2; head=1;tail=2; node[head].nxt=tail; node[tail].pre=head; } void insert(int p,int val){ int q=++tot; node[q].val={val,p,node[p].nxt}; node[node[p].nxt].pre=q; node[p].nxt=q; } void remove(int p){ node[node[p].pre].nxt=node[p].nxt; node[node[p].nxt].pre=node[p].pre; } void clear(){ memset(node,0,sizeof(node)); head=tail=tot=0; }
Solution1:
把序列中的每个数依次插入集合中,在插入 之前,集合中保存着 的所有 ,我们要在集合中找与 最接近的值。
若能维护一个有序集合,则集合中与 最接近的值要么是 的前驱,要么是后继,比较前驱后继与它的差就行了。这是平衡树(set)的基本操作。
solution2:
考虑将 从小到大排序,依次串成一个链表,同时建立一个数组 , 表示原序列中 在链表中的位置(一个指针,从下标到地址的映射)。
因为链表有序,倒序处理,插入变删除。所以在链表中,指针 指向的节点的 pre 和 nxt 即为所求。每次执行完操作后删除 指向的节点,这是 的。此时我们按同样方法对 进行操作,以此类推。
复杂度瓶颈在排序的
邻接表
邻接表可以看成 带有索引数组的多个链表 构成的集合,存储的数据被分为若干 类别 ,每一类的数据构成一个链表。每一类还有一个 代表元素 ,称为该类对应链表的 表头 ,所有 表头 构成一个表头数组,作为一个可随机访问的索引,通过表头数组可定位到某一类链表。
Hash表
又称 散列表 ,一般由 Hash 函数与链表结构共同实现。与离散化思想类似,当我们要对若干复杂信息进行统计时,可以用 Hash 函数把这些复杂的信息映射到一个容易维护的值域内。有可能造成两个不同的原式信息被 Hash 映射为相同的数值,这就是 Hash 冲突。
拉链法:建立一个邻接表结构,以 Hash函数的值域作为表头数组 ,映射后值相同的原始信息被分到同一类,构成一个链表接在对应的表头之后。
Hash表的两个基本操作:
- 计算 Hash函数 的值
- 定位到对应链表中依次遍历、比较
Hash 函数设计好时,原始信息会被均匀分配到各个表头之后,查找统计时间降为 “ 原始信息总数/表头数组长度” 。若两者都为 级别且分散均匀,几乎不产生冲突,
例:统计长度为 N 的随机序列 A 中每个数出现的次数
显然,当 A 的值域较小时,可以直接用数组计数(建立一个大小等于值域的数组进行统计与映射,就是最简单的 Hash思想)。
当 A 的值域很大时,我们可以排序后扫描。也可以使用 Hash表做法。
设计 Hash函数为 ,其中 是一个比较大的质数,但不超过 。显然,这个 Hash函数将序列 A 分成 P 类,我们一次考虑每个数 ,定位到 这个表头对应的链表。如果链表中不包含 ,那么在表头后插入 ,否则就找到 节点并将出现次数加 1。因为序列 是随机的,所以最终所有的 会均匀的分散在各个表头。时间复杂度近似为
简化问题:询问是否存在两个字符串是相似的:可以通过翻转(逆序)或旋转(移位)相同的字符串。
对序列进行 Hash,使得相似的序列 Hash 值相同,一个直接的方法是求出所有字符串正序和逆序循环同构串的 最小表示法。
设计 Hash 函数的原则是相似的字符串哈希值一定相同,哈希值不同的字符串一定不相似,这样才能保证分类的有效性。
设 或 。其中 是一个比较大的质数。对于两片形状相同的雪花,Hash值也相等。
建立一个 Hash表,把每片雪花依次插入,对于每片雪花,我们直接扫描表头 对应的链表,检查是否存在形状相同的雪花。对于随机数据,期望时间复杂度是 的,取 为最接近 的质数(如 ),复杂度为 。
P1196 约瑟夫问题
建立一个队列,指针每次移动的时候将遍历过的元素放入队尾,这样从指针头到队尾维护了从当前点开始顺时针遍历的编号序列,出圈的人将不再入队
当然也可以通过链表实现,看起来比较正常
注意在遍历的时候删除元素要备份一个迭代器,因为删除后 it 就失效了。
链表
链表可以支持快速的插入删除,但不能高效地实现 读取与查询指定值元素,只能存储元素的排列顺序
我们对链表中的每个元素用一个地址存储他们,
单向链表: 每个元素只记录后继
双向链表: 每个元素记录前驱和后继,它可以向两边走
循环单链表: 本身是一个单链表,但最后一个元素的后继指向第一个元素
循环双链表: 顾名思义,在循环单链表的基础上,第一个元素的前驱指向最后一个元素
块状链表: 。。。
双向链表的基操:
struct Node{ int pr,nx,val; Node(int _pr=0,int _nx=0,int _val=0){ pr=_pr;nx=_nx;val=_val; } }; Node s[N]; int tot=0; int find(int x){ int p=1; while(p&&s[p].val!=x)p=s[p].nx; return p; } void ins_back(int x,int y){ int px=find(x); s[++tot]={px,s[px].nx,y}; s[s[px].nx].pr=tot;s[px].nx=tot;//顺序不能反了! } void ins_front(int x,int y){ int px=find(x); s[++tot]={s[px].pr,px,y}; s[s[px].pr].nx=tot;s[px].pr=tot;//顺序不能反了! } int ask_back(int x){ int px=find(x); return s[s[px].nx].val; } int ask_front(int x){ int px=find(x); return s[s[px].pr].val; } void del(int x){ int px=find(x); s[s[px].pr].nx=s[px].nx;s[s[px].nx].pr=s[px].pr; }
P1160 队列安排
链表基础操作,我们可以设置一个虚拟结点 0 一直在链首前一个位置,这样就可以迅速找到链首并开始遍历。
Acwing132 Team Queue
开一个队列保存小组的编号,再对每个小组开个队列按顺序保存小组里的人。入队时如果该小组是空的,那么新建一个队列只保存它一个元素,否则插到对应小组的末尾。出队时找到对应的小组,将队头的人出队。
这样将所有小组队列代入到小组编号队列,就能还原出原始队列了。
P2827 [NOIP2016 提高组] 蚯蚓
n个线段,每次可以切一刀。
如果 ,本题相当于维护一个集合,支持查询最大值,删除最大值,插入新的值。二叉堆能做到
这么一看好像很不可做,我们来冷静分析一下。
首先,最大值拆成两个数之后,集合中的其他数都会增加 ,不妨认为最大值 产生了两个数 ,然后再把整个集合加上 ,这与之前的操作是等价的。
进一步地,我们可以设置变量 表示整个集合的 偏移量 ,集合的数加上 是真实的值。我们每次取出最大值,令 ,分成 插入集合。每次操作完之后令
这是不够的,依然没有解决时间上的问题。
从可以大胆猜测一下:若上一秒取出的最大值为 ,这一秒取出的最大值为 ,,证明也很好证,作差,运用整值函数的性质。
于是的话这意味着我们每个时刻的蚯蚓分裂的两个元素随时间单调递减。于是我们开 3 个队列,一个存从大到小原长,剩下两个存分裂产生的蚯蚓,这样每次比较三个队头就可以得到最大值。支持了查询/删除最大值,插入新的值。正所谓 (优先)队列。
单调队列
我们先求出前缀和 ,一段合法的区间和为 。我们枚举 ,问题变成了求所有 的 的最大值。
观察知:对于任意两个位置 ,如果有 那么对于所以 的右端点, 永远不可能成为最优选择。不但因为 不超过 ,还因为 离 更近,长度不容易超过 ,即 的生存能力比 更强,所以当 出现后, 就是一个无用的位置。
以上告诉我们:可能成为最优选择的策略集合一定是一个 下标位置递增,对应前缀和值也递增 的序列。 我们用队列来保存这个序列(不在队列中的值 100% 不可能成为答案),随着 向后扫描,动态更新:
- 判断队头决策与 的距离是否超出 的范围,若超出则出队。
- 此时队头就是最优选择
- 不断删除队尾决策,直到队尾的对应的 值小于 。然后把 作为一个新的决策入队
这就是著名的单调队列算法,每个元素至多入队一次、出队一次,所以复杂度为 。它的思想也是 在决策集合(队列)中及时排除一定不是最优的选择 ,可优化动态规划。
注意: 单调队列和单调栈都必须保证右端点是从前往后扫的,类似于扫描线,通过离线得到的信息是静态的,不支持动态,因为这没有前途。
首先,问题是动态加入一个数,查询 小值。我们的小根堆只能做 的情况。
首先,假设 是给定的,那么对顶堆可以解决:
维护一个大根堆和小根堆,接起来是一个有序的序列,其中小根堆的堆顶就是第 小值,大根堆保存前 小的所有元素。

当我们插入一个数的时候,就将这个数与堆顶比较,插到合适的堆中,保证有序性。此时可能大根堆元素个数为 ,所以我们将大根堆堆顶调整到小根堆里。这样每次操作只有 1 次,复杂度是 的。
如果 是递增的话,这是均摊 的。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】