数据库 大学排名
1. 数据库笔记
SQLite 中的数据类型
数据库是存储数据的,它自然会对数据的类型进行划分,SQLite 划分有五种数据类型(不区分大小写)
NULL 类型,取值为 NULL,表示没有或者为空
INTERGER类型,取值为带符号的整数,即可为负整数
REAL类型,取值为浮点数
TEXT 类型,取值是字符串
BLOB类型,是一个二进制的数据块,即字节串,可用于存放纯二进制数据,例如图片
DDL语句
简单说,其实主要就是用来创建表的,当然也可以删除表,或者修改表的定义,比如原表只有三列,现在需要五列,就要修改表的定义
概念理解
表: 可以理解为我们通常所说的二维表,分为横纵(行列),用于存放数据
字段: 就是表中的列名
主键: 就是一种特殊的列。每一行数据的主键不能相同,是这一行数据的唯一标识,就像人的身份证号
创建表
create table 表名称(列名1 类型 配置, 列名2 类型 配置, 列名3 类型 配置);
1
注意,SQL语言是不区分大小写的,create 也可以写成CREATE。另外,每一句SQL语句后面都需要一个;号结尾
示例:
create table contacts (
id integer primary key autoincrement,
name text not null ,
phone text not null default 'unknow');
上面的DDL语句创建了一个叫contacts的表,并且定义了三个列,分别是id、name和phone,并且给每一个列定义了数据类型,分别是integer、text、text,这表明,id只能是一个整数,name和phone只能是字符串。
除了这些,还对每一个列做了一些配置,或者叫约束。
primary key autoincrement 的意思是指将id这个列定义为主键,并且从1开始自动增长,也就是说id这个列不需要人为的手动去插入数据,它会自动增长。
not null 指明这一列不能为空,当你插入数据时,如果不插入name或者phone的值,那么就会报错,无法完成这一次插入。
default 'unknow' default关键字代表设置默认值,这里指定它默认值是字符串'unkonw',当不插入这一列数据时,默认就是这个值。此处写法是有些多余的,它与not null 一起用是没有意义的,因为not null已经指明这一列必须插入,不可能为null,那就不需要默认值了,当然,此处只是为了演示default的用法
操作步骤
导入模块
连接数据库,返回连接对象
调用连接对象的execute()方法,执行SQL语句,进行增删改的操作,如进行了增添或者修改数据的操作,需调用commit()方法提交修改才能生效;execute()方法也可用于执行DDL语句进行创建表的操作
调用连接对象的cursor()方法返回游标对象,然后调用游标对象的execute()方法执行查询语句,查询数据库
关闭连接对象和游标对象
1 # 导入模块 2 import sqlite3 3 4 # 连接数据库,返回连接对象 5 conn = sqlite3.connect("D:/my_test.db") 6 7 # 调用连接对象的execute()方法,执行SQL语句 8 # (此处执行的是DDL语句,创建一个叫students_info的表) 9 conn.execute("""create table if not exists students_info ( 10 id integer primary key autoincrement, 11 name text, 12 age integer, 13 address text)""") 14 15 # 插入一条数据 16 conn.execute("insert into students_info (name,age,address) values ('Tom',18,'北京东路')") 17 18 # 增添或者修改数据只会必须要提交才能生效 19 conn.commit() 20 21 # 调用连接对象的cursor()方法返回游标对象 22 cursor = conn.cursor() 23 24 # 调用游标对象的execute()方法执行查询语句 25 cursor.execute("select * from students_info") 26 27 # 执行了查询语句后,查询的结果会保存到游标对象中,调用游标对象的方法可获取查询结果 28 # 此处调用fetchall方法返回一个列表,列表中存放的是元组, 29 # 每一个元组就是数据表中的一行数据 30 result = cursor.fetchall() 31 32 #遍历所有结果,并打印 33 for row in result: 34 print(row) 35 36 #关闭 37 cursor.close() 38 conn.close()
2. 利用爬虫爬取最好大学网上对于2018年全国各大高校的各项指标的排名及综合状况:

import requests, csv
from bs4 import BeautifulSoup
res_univer = requests.get('http://www.zuihaodaxue.com/zuihaodaxuepaiming2017.html')
res_univer.encoding = 'utf-8'
bs_univer = BeautifulSoup(res_univer.text, 'html.parser')
list_all_univer = bs_univer.find_all('tr')[1:501]
count = 0
list_data = []
with open('university.csv', 'w', encoding='gbk') as file_1:
writer = csv.writer(file_1)
writer.writerow(['排名','学校名称','省市','总分','生源质量','培养结果','科研规模','科研质量','顶尖成果','顶尖人才','科技服务','成果转化','学生国际化'])
for list_a_univer in list_all_univer:
count += 1
list_data.append(count)
data = list_a_univer.find_all('td')
for x in range(1,13):
list_data.append(data[x].text)
writer.writerow(list_data)
list_data = []
这是爬取了其中对前600名高等院校的“培训规模”的情况,最终我们将数据导入一个文本文件中(.txt):

查询“广东技术师范学院”的排名和得分信息,我们有下面的代码:
import requests
from bs4 import BeautifulSoup
allUniv=[]
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding = 'utf-8'
return r.text
except:
return ""
def fillUnivList(soup):
data = soup.find_all('tr')
for tr in data:
ltd = tr.find_all('td')
if len(ltd)==0:
continue
singleUniv = []
for td in ltd:
singleUniv.append(td.string)
allUniv.append(singleUniv)
def printUnivList(num):
a="广东技术师范学院"
print("{1:^4}{2:{0}^8}{3:{0}^6}{4:{0}^6}{5:{0}^8}".format((chr(12288)),"排名","学校名称","省市","总分","培训规模"))
for i in range(num):
u=allUniv[i]
if a in u:
print("{1:^4}{2:{0}^10}{3:{0}^5}{4:{0}^8.1f}{5:{0}^10}".format((chr(12288)),u[0],u[1],u[2],eval(u[3]),u[6]))
def main(num):
url='http://www.zuihaodaxue.cn/zuihaodaxuepaiming2018.html'
html = getHTMLText(url)
soup = BeautifulSoup(html,"html.parser")
fillUnivList(soup)
printUnivList(num)
main(600)
于是我们在海量的信息中就能够找到我们学校的排名得分啦~

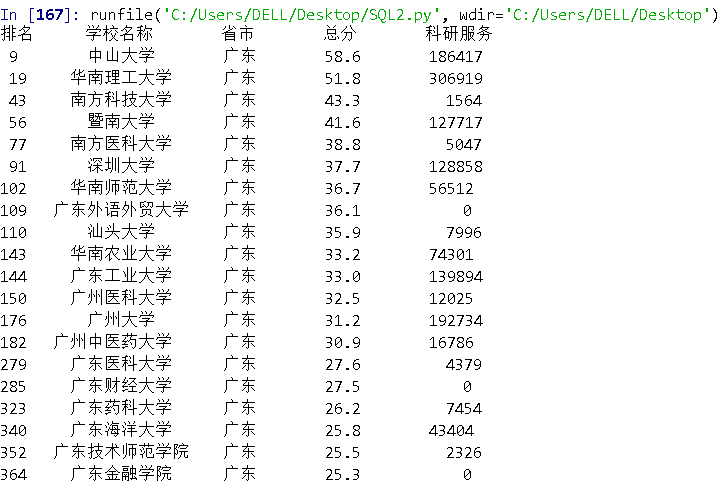
进一步地,我们调查一下广东省的高校的排名和得分情况,顺便对其中一项指标进行比较,只要将上述的代码中a这个参数的变量改为“广东”,即寻找所有关于广东省内的院校就能得到,同时改变爬虫爬取的内容:
def printUnivList(num):
a="广东技术师范学院"
print("{1:^4}{2:{0}^8}{3:{0}^6}{4:{0}^6}{5:{0}^8}".format((chr(12288)),"排名","学校名称","省市","总分","培训规模"))
for i in range(num):
u=allUniv[i]
if a in u:
print("{1:^4}{2:{0}^10}{3:{0}^5}{4:{0}^8.1f}{5:{0}^10}".format((chr(12288)),u[0],u[1],u[2],eval(u[3]),u[6]))
于是有下述结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号