
[LNU.Machine Learning.Question.1]梯度下降方法的一些理解
曾经学习machine learning,在regression这一节,对求解最优化问题的梯度下降方法,理解总是处于字面意义上的生吞活剥。
对梯度的概念感觉费解?到底是标量还是矢量?为什么沿着负梯度方向函数下降最快?想清楚的回答这些问题。还真须要点探究精神。
我查阅了一些经典的资料(包含wiki百科),另一些个人的博客,比方http://www.codelast.com/?p=2573,http://blog.csdn.net/xmu_jupiter/article/details/22220987,都对梯度下降概念有个大概的直观解释,參照这些资料中的内容,再结合个人的体会,姑且谈谈.
1.为什么在多元函数自变量的研究中引入方向?
在自变量为一维的情况下,也就是自变量能够视为一个标量,此时,一个实数就能够代表它了。这个时候,假设要改变自变量的值,则其要么减小,要么添加。也就是“非左即右“。
所以,说到“自变量在某个方向上移动”这个概念的时候,它并非十分明显;而在自变量为n(n≥2)维的情况下。这个概念就实用了起来:假设自变量X为3维的,即每个X是(x1, x2, x3)这种一个点,当中x1,x2和x3各自是一个实数,即标量。
那么,假设要改变X。即将一个点移动到还有一个点,你怎么移动?能够选择的方法太多了,比如。我们能够令x1。x2不变,仅使x3改变,也能够令x1,x3不变。仅使x2改变。等等。这些做法也就使得我们有了”方向“的概念。由于在3维空间中,一个点移动到还有一个点,并非像一维情况下那样“非左即右”的。而是有“方向”的。在这种情况下,找到一个合适的”方向“,使得从一个点移动到还有一个点的时候。函数值的改变最符合我们预定的要求(比如。函数值要减小到什么程度),就变得十分有必要了。
2.为什么是梯度下降(Gradient Descent)
依据维基百科的定义,假设实值函数  在点
在点 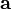 处可微且有定义,那么函数 在 点沿着梯度相反(什么是梯度?这也要问?
处可微且有定义,那么函数 在 点沿着梯度相反(什么是梯度?这也要问?)的方向
 下降最快。因而我们在回归所导出的优化问题中採用梯度下降的方法来寻找最长处问题
下降最快。因而我们在回归所导出的优化问题中採用梯度下降的方法来寻找最长处问题
3.那么。为什么方向 下降最快?
爱问为什么的学生死得快( ).解释这一问题,还须要用到Taylor展开,回顾:
).解释这一问题,还须要用到Taylor展开,回顾:
在梯度的概念下。这个式子能够进一步化为:
(a)
:代表第k个点的自变量(一个向量)。
d:单位方向(一个向量)。即 |d|=1。
:步长(一个实数)。
:目标函数在Xk这一点的梯度(一个向量)。
:α的高阶无穷小。
所谓最速下降,即意味着
也就是说希望(a)式取最小,即觉得最小,而
是向量内积的形式(如果向量d与负梯度
的夹角为θ):
(b)
(b)式取最小当且仅当\theta=0,此时方向向量d(自变量的变化方向)取负梯度方向,这个方向就是梯度变化最大的方向(负变化最小,始终要求方向的概念在脑海中)。
4.几何解释
以下图片演示样例了这一过程,这里如果 F 定义在平面上,而且函数图像是一个碗形。
蓝色的曲线是等高线(水平集)。即函数 F 为常数的集合构成的曲线。红色的箭头指向该点梯度的反方向。(一点处的梯度方向与通过该点的等高线垂直)。
沿着梯度下降方向,将终于到达碗底,即函数 F 值最小的点

梯度下降法几何解释:
因为我们的任务是求得经验损失函数的最小值。所以上图的过程实际上是一个“下坡”的过程。
在每个点上。我们希望往下走一步(如果一步为固定值0.5米),使得下降的高度最大,那么我们就要选择坡度变化率最大的方向往下走。这个方向就是经验损失函数在这一点梯度的反方向。
每走一步,我们都要又一次计算函数在当前点的梯度,然后选择梯度的反方向作为走下去的方向。随着每一步迭代,梯度不断地减小,到最后减小为零。
这就是为什么叫“梯度下降法”。
先讲到这里。敲符号、磊代码太累......
在此,向Orange先生、learnhard、wiki表示由衷的感谢


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架