计算机集群(cluster)一些松散指计算机系统。告诉网络连接,协同工作。集群为用户像一台计算机系统,只是具有更高的性能和更高的可靠性。集群中的每个计算机被称为节点。
常见集群类型
高性能计算(HPC, high performance computing)
主要用于科学计算,多用于科研领域,一般的商业领域较少用到该类集群。最開始出现的集群就是为了高性能计算设计的。集群出现之前,科学计算都採用大型主机计算。这类主机一般都採用封闭设计,价格很昂贵。集群的目的就是使用多台普通PC搭建系统,以低廉的价格提供能够匹敌大型机的计算能力。Beowulf cluster是该类系统的代表。这类系统的核心技术:1)并行算法。2)节点间通信。
并行算法
传统的算法大多是顺序运行(serial execution)。
为了发挥集群的效能,须要让计算任务在多个节点上同一时候运行,这就须要并行算法。并行算法和多进程(线程)不同:并行算法是一个算法。同一时候在多个处理器上运行。每一个处理器上运行的任务是有关联的。终于产生一个结果;多进程(线程)每一个处理器上运行的任务是不想关的,每一个任务都有自己的结果。
Oracle中有个并行处理(parallel processing)功能。
普通SQL处理
普通的SQL处理仅仅能使用一个CPU,可是能够执行多个进程(server process)同一时候处理多个SQL。
每一个SQL处理之间没有关联,都有自己的终于结果。
并行SQL处理
能够使用多个CPU,比方在运行查找时,能够将表中数据分成若干个集合。每一个集合分给一个CPU运行,最后将每一个CPU的结果汇总,形成终于结果。
多个CPU之间是有关系的,终于仅仅有一个结果。
详细请參考oracle关于paralle processing的介绍。
节点间通信
大数据分析(big data)
该类型集群应该是随着互联网的兴起而出现。
互联网的出现导致了海量数据的出现。海量数据的出现要求有对应的方法来处理、分析这些数据。Google的MapReduce是处理大数据的事实标准,已被广泛採用。
MapReduce
MapReduce的核心也是并行处理,这点和高性能计算是类似的。但和高性能计算也有显著差别:前者的重点是数据。将数据拆分,然后分给每一个几点。后者则是计算,将计算任务分解后分给每一个节点;前者是IO密集型。后者是计算密集型。由于关注数据。所以MapReduce有个特点:Locality:
Locality的思路就是让每一个节点分到的数据,最好存放在本地(即使不在本地,也要在离本节点近的节点上,如接入同一交换机的节点),这样能够避免通过网络拿数据带来的额外开销和带宽占用。Google使用GFS作为数据存储平台。将GFS和MapReduce部署在同一集群上,来实现locality的特性。
MapReduce节点通信
MapReduce集群中的节点也须要相互通信,论文中并没有给出细节,仅仅说明使用了Remote Procedure Call。MapReduce节点间的通信也能够採用MPI标准来实现,能够參考MapReduce-MPI (MR-MPI)
library,开源的MapReduce实现,採用MPI作为通信协议(http://mapreduce.sandia.gov/)。
MapReduce还提供了容错处理(fault tolerance)等功能,详细请參考论文。
Hadoop
hadoop是使用最广的基于MapReduce/GFS的实现。Hadoop在如今的互联网公司中有广泛应用。支X宝账单中会有各种各样的统计数据。个人认为应该是採用MapReduce分析出来的(推測)。X宝的Hadoop服务叫做《X宝云梯》,网上有不少的资料,有兴趣的朋友能够搜搜看。
存储集群
依照存储模型看,存储系统能够分为3类:块级存储,文件存储,key-value及关系数据库。
块级存储
块级存储的代表是採用SAN的存储设备。这样的设备在大型企业中广泛採用,历史悠久,技术成熟。但也有缺点:一是价格昂贵。而是扩展性不强。
分布式文件系统
代表产品是Google GFS。
通过大量便宜PC + 软件方案。以低廉的价格提供:1)海量存储 2)高性能 3)高可用(HA) 4)可扩展(scalability)等特性。
该系统在互联网企业中大量使用。
Fast DSF:基于GFS思路设计的开源分布式文件系统。针对互联网使用设计。具有负载均衡。冗余备份。线性扩展等特性。
本身代码量较小,设计较为简单,适合感兴趣的同学学习。
key-value
该类产品就是如今流行的NoSQL,存储模型不限于key-value。还能够是其它。
NoSQL产品适合那些訪问量大。但又不须要事物处理(Transaction)的场景。
互联网上的大量场景都符合这个特点,如门户站点。论坛,博客等。这些场景都是读多写少。非常少更新,没有事物。
NoSQL产品一般都有非常好的扩展性。该系统在互联网企业中大量使用。
key-value模型:MemcacheDB。
MemcacheDB基于Memcached。但提供了持久化支持。Memcached本身是作为缓存(cache)用的,数据会有失效期。重新启动系统也会导致数据丢失。Amazon S3,openstack swift也都是採用了key-value模型的分布式存储系统。
还其它存储模型的系统:如MongoDB,採用document模型;google的bigtable。採用表模型。
关系数据库
基于关系模型构建,最大的特点是支持:SQL和事物(transaction)。SQL中的最重要的功能就是表连接(join)。NoSQL对SQL和连接的支持都不是非常完整,有一定限制。关系数据库的缺点是扩展性不强,非常多互联网场景不适合。关系数据库在互联网中的应用还是不可代替的,非常多场景还须要事物处理。如电子商务的支付。下单等。
不同的存储集群有不同的特点。应用须要依据自身的特点来选择合适的模型。眼下amazon的云服务中提供了块级存储(EBS)和key-value(S3)及关系数据库(RDS)的服务。当中S3的容量不限,EBS和RDS都能够依据须要随时调整。
Web集群
提供web服务的集群,互联网中的大部分集群都属于这样的。直接给用户提供各种服务,如网页。视频。web service。游戏等。
集群中的可扩展性
集群中的节点数量不固定,能够依据实际需求动态扩展,最简单的集群仅仅须要两个节点。集群中添加节点的能力叫做可扩展性(scalability)。
随着节点的添加。节点之间的数据流量也会逐渐添加。当网络的传输速度无法满足集群产生的数据流量时,该集群就达到了节点上限。能够通过创建多个集群系统满足更高的需求。
集群的可扩展性和集群类型相关,假设各节点之间没有关联并且节点本身也没有数据(状态)。则easy扩展,比方web集群。其它集群的扩展则比較复杂。
集群中节点之间的关系
一般集群的设计中会有一个主控节点(master)用来协调集群的总体执行,其余的属于工作节点(从节点)。如web集群中的负载均衡器(load balancer)。负载均衡器负责将请求调度到集群中的工作节点上。存储系统中主控节点负责定位给定数据保存在哪台工作节点上。LVM是基于Linux的广泛採用的负载均衡器。
也有对等集群设计,全部节点都是工作节点,没有主控。
代表设计有amazon Dynamo。
只是这样的设计带来了非常多复杂性。实际效果并非非常理想。
眼下商用的产品设计都是有主控节点的。
节点之间的通信
集群的节点之间须要互相通信。通信能够採用标准协议(如MPI)。也能够採用自己定义协议。非常多集群会依据自己的特点。设计专用协议,达到性能最大化。
web集群一般採用标准的HTTP(S)协议通信。有的集群通信仅仅限于主控节点和工作节点。如web集群中。有些则是工作节点之间也须要通信。如分布式文件系统中。工作节点之间须要同步数据副本。
集群的管理
负载均衡
调整每一个节点的工作复杂(CPU或存储),配置不同的算法。
心跳包
用来检查集群中节点的状态。假设几点发生问题,能够通过心跳检測出来。
容错处理
系统中节点故障后的处理,处理方法和集群类型相关。
如web集群中,负载均衡器採用主备模式,主设备失效后,备份设备自己主动接替主设备工作(failover)。工作节点失效后,仅仅要从负载均衡器中移除该设备就可以。
存储设计的处理会相对复杂。一个工作节点失效后,该节点上的数据备份所有丢失,集群须要找出丢失的数据并在其它节点中从建这些备份。
扩容
web集群中,扩容仅仅要将新机器配置在负载均衡器上就可以。存储节点上增加新机器的策略就不同样。有的会将集群中的部分数据迁移到新机器中。有的则是将之后产生的新数据调度到该机器上。
监控
用来监控集群系统的总体执行状态。集群系统会提供各自的监控工具。
架构示意图
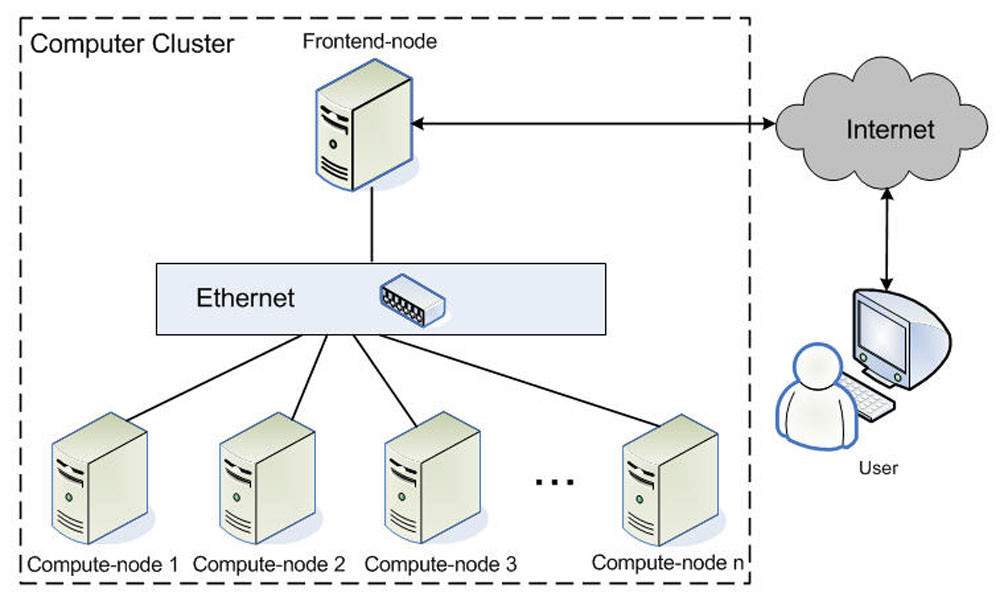
从网络
版权声明:本文博主原创文章,博客,未经同意不得转载。


