
OpenCV中的SVM參数优化
SVM(支持向量机)是机器学习算法里用得最多的一种算法。SVM最经常使用的是用于分类,只是SVM也能够用于回归,我的实验中就是用SVM来实现SVR(支持向量回归)。
对于功能这么强的算法,opencv中自然也是有集成好了,我们能够直接调用。OpenCV中的SVM算法是基于LibSVM软件包开发的,LibSVM是台湾大学林智仁(Lin Chih-Jen)等开发设计的一个简单、易于使用和高速有效的SVM模式识别与回归的软件包。
网上讲opencv中SVM使用的文章有非常多,但讲SVM參数优化的文章却非常少。所以在这里不重点讲怎么使用SVM,而是谈谈如何通过opencv中自带的库优化SVM中的各參数。
相信用SVM做过实验的人都知道,SVM的各參数对实验结果有非常大的影响,比方C,gama,P,coef等等。以下就是CvSVMParams类的原型。
C++: CvSVMParams::CvSVMParams()
C++: CvSVMParams::CvSVMParams(int svm_type,
int kernel_type,
double degree,
double gamma,
double coef0,
double Cvalue,
double nu,
double p,
CvMat* class_weights,
CvTermCriteria term_crit
)
- CvSVM::C_SVC : C类支持向量分类机。 n类分组 (n≥2),同意用异常值惩处因子C进行不全然分类。
- CvSVM::NU_SVC :
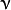 类支持向量分类机。n类似然不全然分类的分类器。參数为代替C(其值在区间【0,1】中,nu越大,决策边界越平滑)。
类支持向量分类机。n类似然不全然分类的分类器。參数为代替C(其值在区间【0,1】中,nu越大,决策边界越平滑)。 - CvSVM::ONE_CLASS : 单分类器,全部的训练数据提取自同一个类里,然后SVM建立了一个分界线以切割该类在特征空间中所占区域和其他类在特征空间中所占区域。
- CvSVM::EPS_SVR :
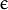 类支持向量回归机。训练集中的特征向量和拟合出来的超平面的距离须要小于p。异常值惩处因子C被採用。
类支持向量回归机。训练集中的特征向量和拟合出来的超平面的距离须要小于p。异常值惩处因子C被採用。 - CvSVM::NU_SVR : 类支持向量回归机。 代替了 p。
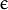 类支持向量回归机。训练集中的特征向量和拟合出来的超平面的距离须要小于p。异常值惩处因子C被採用。
类支持向量回归机。训练集中的特征向量和拟合出来的超平面的距离须要小于p。异常值惩处因子C被採用。<2>kernel_type:SVM的内核类型(4种):
- CvSVM::LINEAR : 线性内核,没有不论什么向映射至高维空间,线性区分(或回归)在原始特征空间中被完毕,这是最快的选择。
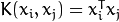 .
.- CvSVM::POLY : 多项式内核:
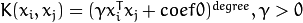 .
.- CvSVM::RBF : 基于径向的函数,对于大多数情况都是一个较好的选择:
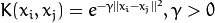 .
.- CvSVM::SIGMOID : Sigmoid函数内核:
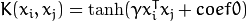 .
. 。
。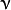 。
。 。
。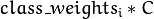 。所以这些权重影响不同类别的错误分类惩处项。权重越大,某一类别的误分类数据的惩处项就越大。
。所以这些权重影响不同类别的错误分类惩处项。权重越大,某一类别的误分类数据的惩处项就越大。CvSVMParams param; param.svm_type = CvSVM::EPS_SVR; //我的实验是用SVR作回归分析,可能大部分人的实验是用SVM来分类,方法都一样 param.kernel_type = CvSVM::RBF; param.C = 1; param.p = 5e-3; param.gamma = 0.01; param.term_crit = cvTermCriteria(CV_TERMCRIT_EPS, 100, 5e-3);
C++: bool CvSVM::train(const Mat& trainData,
const Mat& responses,
const Mat& varIdx=Mat(),
const Mat& sampleIdx=Mat(),
CvSVMParams params=CvSVMParams()
)
C++: bool CvSVM::train_auto(const Mat& trainData,
const Mat& responses,
const Mat& varIdx,
const Mat& sampleIdx,
CvSVMParams params,
int k_fold=10,
CvParamGrid Cgrid=CvSVM::get_default_grid(CvSVM::C), CvParamGrid gammaGrid=CvSVM::get_default_grid(CvSVM::GAMMA), CvParamGrid pGrid=CvSVM::get_default_grid(CvSVM::P), CvParamGrid nuGrid=CvSVM::get_default_grid(CvSVM::NU), CvParamGrid coeffGrid=CvSVM::get_default_grid(CvSVM::COEF), CvParamGrid degreeGrid=CvSVM::get_default_grid(CvSVM::DEGREE),
bool balanced=false
)
- 前5个參数參考构造函数的參数凝视。
- k_fold: 交叉验证參数。训练集被分成k_fold的自子集。当中一个子集是用来測试模型,其它子集则成为训练集。所以,SVM算法复杂度是运行k_fold的次数。
- *Grid: (6个)相应的SVM迭代网格參数。
- balanced: 假设是true则这是一个2类分类问题。这将会创建很多其它的平衡交叉验证子集。
- 这种方法依据CvSVMParams中的最佳參数C, gamma, p, nu, coef0, degree自己主动训练SVM模型。
- 參数被觉得是最佳的交叉验证,其測试集预估错误最小。
- 假设没有须要优化的參数,对应的网格步骤应该被设置为小于或等于1的值。比如,为了避免gamma的优化,设置gamma_grid.step = 0,gamma_grid.min_val, gamma_grid.max_val 为随意数值。所以params.gamma 由gamma得出。
- 最后,假设參数优化是必需的,可是对应的网格却不确定,你可能须要调用函数CvSVM::get_default_grid(),创建一个网格。比如,对于gamma,调用CvSVM::get_default_grid(CvSVM::GAMMA)。
- 该函数为分类执行 (params.svm_type=CvSVM::C_SVC 或者 params.svm_type=CvSVM::NU_SVC) 和为回归执行 (params.svm_type=CvSVM::EPS_SVR 或者 params.svm_type=CvSVM::NU_SVR)效果一样好。假设params.svm_type=CvSVM::ONE_CLASS,没有优化,并指定执行一般的SVM。
CvSVMParams param; param.svm_type = CvSVM::EPS_SVR; param.kernel_type = CvSVM::RBF; param.C = 1; //给參数赋初始值 param.p = 5e-3; //给參数赋初始值 param.gamma = 0.01; //给參数赋初始值 param.term_crit = cvTermCriteria(CV_TERMCRIT_EPS, 100, 5e-3); //对不用的參数step设为0 CvParamGrid nuGrid = CvParamGrid(1,1,0.0); CvParamGrid coeffGrid = CvParamGrid(1,1,0.0); CvParamGrid degreeGrid = CvParamGrid(1,1,0.0); CvSVM regressor; regressor.train_auto(PCA_training,tr_label,NULL,NULL,param, 10, regressor.get_default_grid(CvSVM::C), regressor.get_default_grid(CvSVM::GAMMA), regressor.get_default_grid(CvSVM::P), nuGrid, coeffGrid, degreeGrid);
用上面的代码的就能够自己主动训练并优化參数。最后,若想查看优化后的參数值,能够使用CvSVM::get_params()函数来获得优化后的CvSVMParams。以下是演示样例代码:
CvSVMParams params_re = regressor.get_params();
regressor.save("training_srv.xml");
float C = params_re.C;
float P = params_re.p;
float gamma = params_re.gamma;
printf("\nParms: C = %f, P = %f,gamma = %f \n",C,P,gamma);
