软工实践寒假作业(2/2)
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzu/2020SPRINGS |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/2020SPRINGS/homework/10287 |
| 这个作业的目标 | 实现肺炎信息统计 |
| 作业正文 | https://www.cnblogs.com/hrc990816/p/12287909.html |
| 其他参考文献 |
github仓库链接
https://github.com/ququdefuqin/InfectStatistic-main
编程代码规范
缩进:
统一缩进4格
命名:
1.使用纯英文单词
2.多个单词用下划线隔开,如student_num,find_max_num()
3.常量,宏,模板,枚举类型常量采取全大写形式
4.除循环变量外不用单字母作为变量名
5.类和函数命名首字母大写
每行最多字符数:
80个
函数编写规则:
1.函数的行数尽量限制在100行以内
2.一个函数完成一个功能
3.禁止编写的函数依赖于其他函数内部所实现的功能
4.尽量重写类的构造函数
空行:
每个函数,类,结构体,以及某些程序块之间空一行以表示分离关系
注释规则:
1.在源文件头部应该列出:生成日期,作者,版权,代码功能/目的等信息
2.应该函数程序块前编写注释表明函数功能以及一些必要信息
3.重要变量定义需编写注释
操作符前后空格:
1.值操作符、比较操作符、算术操作符、逻辑操作符、位域操作符,如“ =”、“ +=”
“ >=”、“ <=”、“ +”、“ *”、“ %”、“ &&”、“ ||”、“ <<” 、“ ^” 等二元操作符
的前后应当加空格
2.一元操作符如“ !”、“ ~”、“ ++”、“ --”、“ &”( 地址运算符) 等前后不加
空格
3.像“[ ]”、“ .”、“ ->” 这类操作符前后不加空格
其他规则:
1.尽量使用const,避免使用宏
2.尽可能局部声明变量
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 20 |
| Estimate | 估计这个任务需要多少时间 | 30 | 60 |
| Development | 开发 | 120 | 120 |
| Analysis | 需求分析 (包括学习新技术) | 420 | 480 |
| Design Spec | 生成设计文档 | 60 | 30 |
| Design Review | 设计复审 | 30 | 15 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 60 |
| Design | 具体设计 | 30 | 30 |
| Coding | 具体编码 | 360 | 360 |
| Code Review | 代码复审 | 60 | 60 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 120 |
| Reporting | 报告 | 60 | 180 |
| Test Repor | 测试报告 | 60 | 120 |
| Size Measurement | 计算工作量 | 60 | 60 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 1470 | 1745 |
解题思路
这次用到的最核心的数据结构就是:map.
解题分为大致三个步骤:
1.用map存储命令行中成对的参数,用map>存储拥有多个
值的参数,方便后续处理.
2.用fstream文件流处理log文件,同样用map存储各省对应的信息,对文件日志的处理以行为单位,先
处理是什么省,再处理该省的动作,将该省可能做出的动作进行分类处理.
3.输出的output文件就依次从map中按map["省份名"]的形式将各省的肺炎情况输出,对于-date,
-type,-province的约束在输出前将需要的map中的key准备好,在输出时将这些key依此放到map中
就可以做到按约束输出了.
2.用fstream文件流处理log文件,同样用map存储各省对应的信息,对文件日志的处理以行为单位,先 处理是什么省,再处理该省的动作,将该省可能做出的动作进行分类处理.
3.输出的output文件就依次从map中按map["省份名"]的形式将各省的肺炎情况输出,对于-date, -type,-province的约束在输出前将需要的map中的key准备好,在输出时将这些key依此放到map中 就可以做到按约束输出了.

#代码设计:
代码设计就是将解题思路中的各个功能化为函数

#关键代码展示
process_cmd:处理命令行参数
void process_cmd(int num, char* cmd_i[])
{
int i;
string temp; //中转字符串
bool break_sign = false;
for (i = 3; i < num && !break_sign; i++)
{
if (strcmp(cmd_i[i], "-province") == 0 || strcmp(cmd_i[i], "-type") == 0)
{
vector<string> list_temp;
string m_name = cmd_i[i];//记录命令行参数名称
temp = cmd_i[i];
while (1)
{
string temp1;
temp = cmd_i[++i];
temp1 = temp.substr(0, 1);
if (temp1.compare("-") == 0)
break;
list_temp.push_back(temp);
cout << cmd_i[i] << "\n";
if (i >= num - 1)
{
break_sign = true;
break;
}
}
i--;
m_many.insert(make_pair(m_name, list_temp));
}
else
{
string temp1, temp2;
temp1 = cmd_i[i];
temp2 = cmd_i[++i];
m_single.insert(make_pair(temp1, temp2));
}
}
}
process_file:处理指定路径下的日志文件
void process_file(string log_file)
{
int num; //测试用的
//6种情况,新增(感染患者,疑似患者),感染患者,疑似患者(流入,确诊),死亡,治愈,排除(疑似患者).
int i;
//首先加入全国的情况
fstream fei_yan_log(log_file);
string temp;
string temp_past; //用于存储之前一次的读取
string province_name;
bool is_province = true; //是否读到省份的标志位
while (!fei_yan_log.eof())
{
temp_past = temp;
fei_yan_log >> temp;
num = draw_number(temp);
temp = UTF8ToGB(temp.c_str()).c_str();
if (temp.substr(0, 1).compare("/") == 0)
break;
if (is_province)
{
if (m_province.find(temp) == m_province.end())
{
insert_province(temp);
occur_province.push_back(temp);
}
is_province = false;
province_name = temp;
}
if (temp.compare("新增") == 0)
{
process_xin_zeng(fei_yan_log, province_name);
is_province = true;
}
if (temp.compare("死亡") == 0)
{
process_pass_away(fei_yan_log, province_name);
is_province = true;
}
if (temp.compare("治愈") == 0)
{
process_zhi_yu(fei_yan_log, province_name);
is_province = true;
}
if (temp.compare("流入") == 0)
{
process_liu_ru(fei_yan_log, province_name, temp_past);
is_province = true;
}
if (temp.compare("确诊感染") == 0)
{
process_que_zhen(fei_yan_log, province_name);
is_province = true;
}
if (temp.compare("排除") == 0)
{
process_pai_chu(fei_yan_log, province_name);
is_province = true;
}
}
}
output_fei_yan_log:输出统计信息至指定文件
void output_fei_yan_log(int argc,char* argv[])
{
int i;
vector<int> type; //用于处理要输出的type
vector<string> need_province; //需要的省份
bool is_need_quan_guo = true; //是否需要输出全国,因为排序问题需要把全国单独列出
bool is_need_erase = true;
if (m_many.find("-type") != m_many.end())
{
for (i = 0; i < (m_many["-type"]).size(); i++)
type.push_back(m_type[(m_many["-type"])[i]]);
}
else
{
for (i = 0; i < 4; i++)
type.push_back(i);
}
if (m_many.find("-province") != m_many.end())
{
sort((m_many["-province"]).begin(), (m_many["-province"]).end());
need_province.insert(need_province.begin(), (m_many["-province"]).begin(), (m_many["-province"]).end());
if (find(need_province.begin(), need_province.end(), "全国") == need_province.end())
is_need_quan_guo = false;
}
else
{
sort(occur_province.begin(), occur_province.end());
need_province.insert(need_province.begin(), occur_province.begin(), occur_province.end());
is_need_erase = false;
}
string output_path = m_single["-out"];
fstream output_file(output_path, fstream::out);
vector<int> province_log;
vector<string> output_basic_string;
output_basic_string.push_back(" 感染患者");
output_basic_string.push_back(" 疑似患者");
output_basic_string.push_back(" 治愈");
output_basic_string.push_back(" 死亡");
if (is_need_quan_guo)
{
for (i = 0; i < 4; i++)
{
province_log.push_back((m_province["全国"])[i]);
}
output_file << "全国";
for (i = 0; i < type.size(); i++)
{
output_file << output_basic_string[type[i]] << province_log[type[i]] << "人";
}
output_file << "\n";
}
m_province.erase(m_province.find("全国"));
if(is_need_erase)
need_province.erase(find(need_province.begin(), need_province.end(), "全国")); //全国输出完后删除,以免影响后续输出
for (i = 0; i < need_province.size(); i++) //输出每个省份的数据
{
province_log.clear();
output_file << need_province[i];
for (int m = 0; m < 4; m++)
{
province_log.push_back((m_province[need_province[i]])[m]);
}
for (int n = 0; n < type.size(); n++)
{
output_file << output_basic_string[type[n]] << province_log[type[n]] << "人";
}
output_file << "\n";
}
output_file << "// 该文档并非真实数据,仅供测试使用" << "\n"; //输出文件尾数据
output_file << "// 命令:";
for (i = 0; i < argc; i++)
{
output_file << argv[i] << " ";
}
}
#单元测试
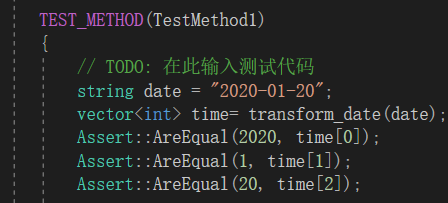
##如图是第一个测试,该测试主要检测日期转化函数的正确性
 ##第二测试是检测日期比较函数的返回值正确性
##第二测试是检测日期比较函数的返回值正确性
T.png) ##第三个测试是检测整个函数对命令行参数的处理的正确性,测试结果由output文件显示
##第三个测试是检测整个函数对命令行参数的处理的正确性,测试结果由output文件显示
 ##第五个测试与第三个测试一样,只是改变了命令行参数,其他测试与第三个测试一样,变量是命令行参数
##第五个测试与第三个测试一样,只是改变了命令行参数,其他测试与第三个测试一样,变量是命令行参数
DXME]3XW%60Z($C]J%7BO4O.png) ##如图,测试通过
##如图,测试通过
]9[2HVAO2ARFME%7BZ2(5B.png) ##第三个之后的测试结果如下图,取其中四个测试图
##第三个之后的测试结果如下图,取其中四个测试图



覆盖率与性能测试
如图是单元测试覆盖率:
326YY[TASC.png)
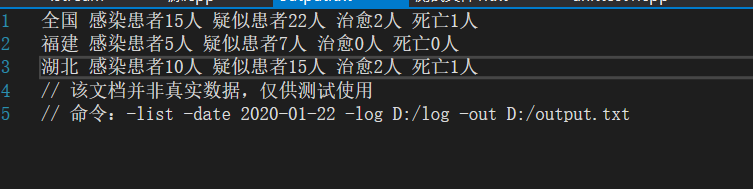
 ##如图为性能测试(cpu使用百分比以及函数占有时间百分比):
##如图为性能测试(cpu使用百分比以及函数占有时间百分比):