天马行空-Ops平台建设概述
1 概述
什么是Ops平台,Ops平台的目标是什么,建设的考虑点有哪些?本章节以实际生活中医院的例子来进行各形象的阐述。
医院包含各种诊断治疗设备,病历库,医生。一个孕妇需要到医院产科,生下了小娃子,小有天生病了,到医院挂号约医生,描述症状,医生通过描述的症状,选择诊断设备,参考相关病例,结合自己医术经验进行病理诊断,然后通过治疗设备或者药物进行医治,小娃子康复出院。 而小娃子成长过程中,有时候可能会得了一些病,但是自己却无感知,为了呵护小娃子的健康成长,医院就对小娃子定期的就进行体验,对器官的各项指标进行检测诊断。发现哪些有问题或者隐患,就对症医治或者反馈给小娃子,平时要多注意运动啊,多吃蔬菜啊等等。
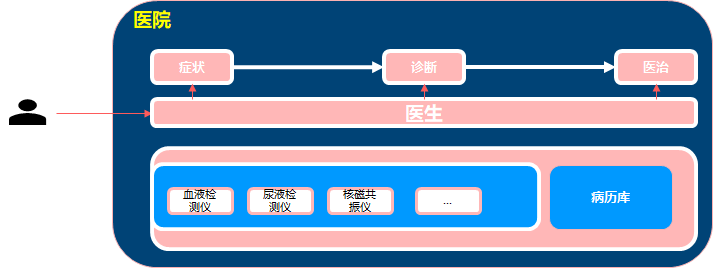
而Ops平台就是这个医院,Ops平台包含各种的诊断治疗的工具(包含部署工具),运维人员,以及知识库。运维人员(医生)根据这些诊断治疗的工具对问题进行诊断和治疗。运维人员同时需要借助这些工具对系统进行主动的问题/隐患进行发现。部署工具就类似医院的助产设备,将研发的系统(研发就是孕妇)能够成功部署上线(生个小娃子)。
结合企业产品运作模式:
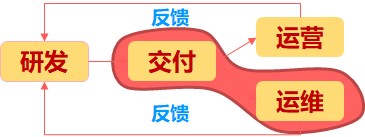
产品研发,现场实施,日常运维与运营,而运维与运营反馈研发需求改进(让小娃子多运动,食谱啥的),如此一个不断反复循环的过程。此处描述的交付指的就是产品人员使用Ops平台的部署工具进行产品的部署上网(孕妇借助助产设备药物等)正常的剩下小娃子。
所以Ops平台剑指的范围是健康高效的支撑交付与日常运维。
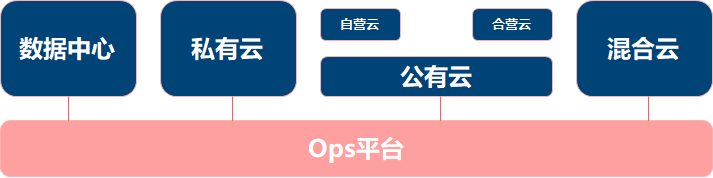
对于建立一个医院,首先是要考虑建设某一专科医院呢还是建立一个综合性医院,不同的科室(譬如牙科,眼科等)。而建设一个Ops平台首先就得考虑目标使用的场景,得考虑目标使用场景有哪些。需要给Ops带上定语对象去分析。譬如云数据中心的Ops平台,目前互联网广泛所说的Ops(应用的Ops),以及云提供商的Ops平台(私有云,公有云,混合云),而对于譬如公有云提供商的Ops平台根据又根据商业模式的不同,面对的场景有所差异,譬如自营或者合营模式。不同的定语对象在Ops上表现为Ops平台需要提供哪些诊断治疗工具。
对于医院来说,总是考虑招聘更少的医生却能诊断治愈更多的病人,因为医生要发工资啊,交社保啊,提供办公地儿啊等的开支,所以如果能做一个机器人,让机器人能给病人看病就很好了,做个机器人医生是长远的伟大目标,在宏伟目标之前,医院也得考虑降成本啊,所以就出现了在线医疗,远程医疗啊等等。而Ops平台建设也是同样的考虑,目标最终目标是构筑智能化的Ops机器人。
综述下本篇意图描述的主题是:
- 数据中心,私有云,公有云,混合云模式下Ops的场景介绍。
- 如何最终构筑一个智能化的Ops平台
- Ops平台 As CloudService
2 简史
弄懂历史,才能更彻底了解当下,洞察未来。为了比较清楚的描述清楚Ops的业务场景,很有必要展开下Ops平台的发展史,读者可以带着这几个问题来思考:
l 传统IT企业的Ops平台为什么已经越来越难以适应当下的时代?
l 纯粹互联网企业的Ops平台在当前时代又有哪些局限或者痛点
l 我们Ops平台的对象目标一直存在着什么变化?
l 市场上对Ops平台在不同的阶段有什么样的诉求?
要回答清楚这几个问题,就有必要简要扒一扒IT的发展史,回顾过去,结合与Ops相关的,基本可以划分为下述三个阶段:传统DC时代;虚拟化时代;Cloud时代。Cloud时代有分为了三种形态:私有云,公有云,混合云。
2.1 传统DC时代
对于传统行业的企业来说,IT信息化建设是可以明显降低企业经营的成本开支的,这一理念已经被洗脑并广泛认可。所以传统行业分分加大投入进行信息化建设,并从部门组织上,一般分为了IT部门和业务部门两种。IT的需求从业务部门搜集,并进行信息化建设。
而传统行业的IT技能不足,无力自研,故而就冒出了提供ERP,OA等办公套件的IT企业,Oracle等数据库企业,而IT部门进行招标采购,所以这个阶段对于IT企业是一个蜜月期,IT企业的业务收入主要目标是来自传统领域企业以及IT企业自身的IT信息化建设,而IT信息化建设也推动了数据中心的出现。
我们来了解下数据中心的构成,数据中心是个包含机房,以及机房中设备,系统,数据的统称。机房是数据中心的物理形态。所以位置关系模型上则为:国家-地区-机房。例如中国-广州-南方基地机房。每个机房包含多个机架,供电,制冷设备,机架上摆了很多物理设备,设备上部署了很多业务系统,系统提供了业务和数据,将这个我们划分为四层:L0~L4。所以数据中心从物理关系模型如下:

我们再看数据中心的建设流程,基本就是L0~L4层的建设,如下:

l 规划:包括数据中心选址,L1层建设(空调,机房,电力),组网模型,容量规划。
l 采购:根据规划的输出,从IT设备商,能源设备商采购设备资产
l L1上线:由动环能耗等设备企业进行供电,制冷等安装。
l L2上线:有IT设备商驻场进行服务器,数通,存储等设备的上架安装通电配置。
l L3/L4层上线:由IT部门进行OS,数据库,IT系统的部署配置。
这个阶段,传统企业对于信息化建设主要聚焦在办公套件OA,ERP等领域,对IT的要求是比较单一的。也进而决定了对数据中心的规模也不会很大,对于IT部门来说就是能够将采购的资产能够管理经营,将L1层动环能耗等设备监控和管理起来,将L2层数通等设备监控和管理起来,L3/L4层的部署和监控起来,报障IT业务系统正常运行,这是IT部门基本诉求。对于L1~L2 则是由对应的设备厂商配套提供了设备的监控管理的能力,对于L3/L4层因为基本都是采购自第三方的企业级产品,这种传统的IT企业级产品都是部署企业易用性不是问题,所以对于L3/L4的主要的问题集中在这些应用系统的监控上。而对于监控,是从应用的构成的标准化软件上切入的,譬如OS,数据库,JVM等等都是标准的,所以出现了APM这种产品,企业额外采购或者使用开源的APM监控系统来完成。
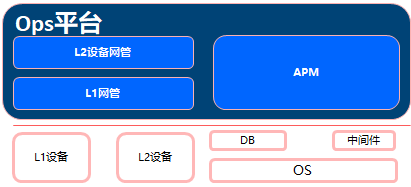
对于数据中心的Ops来说,这个阶段基本是各种设备网管+APM,基本是围绕基础设施资源来管理的。
上述可以认为是初始的第一代数据中心运维管理模式,面临的问题也很明显:
1:数据中心设备七国八制,网管系统众多。
客户在建立数据中心设备采购的时候,一个很主要的商业因素是担心被某一厂商锁定,所以会采购不同厂商的设备,譬如防火墙,核心交换机,边界交换机,终端设备等是采购自不同的设备厂商,这就带来了另一个问题:各厂商设备的网管系统众多,操作窗口多,设备维护困难。故障处理无法联动。
2:数据中心分散两地,人力维护成本高。
因此为解决这一类问题,第二代数据中心综合运维系统意在从统一资源管理,统一性能监控,统一告警角度,统一报表来切入,支持更多的异构设备,支持OS,中间件等,并提供提供问题发现-问题分析-问题解决的运维能力。这个时期的代表产品:华为的eSight,BMC的一系列(例如CMDB,BPPM,BEIM等),桌豪的一系列(OpsManager,ApplicationManager等),CA的NimSoft。
DCOps2.0的特点架构基本如下:
l 统一架构解决系统众多,数据分散问题
l 级联-被级联支持多DC统一运维问题

l 运维场景(以某商业产品为例:公开资料来源)
1 多种设备统一发现
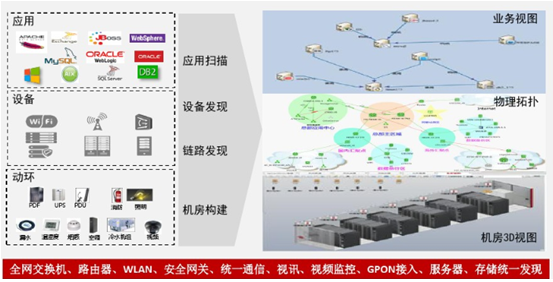
2 多种设备批量配置
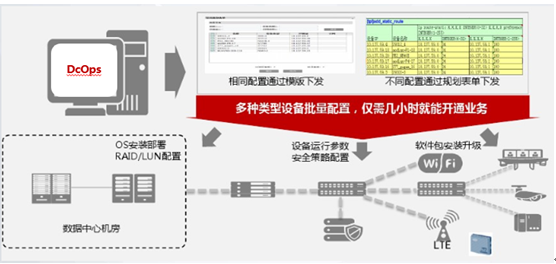
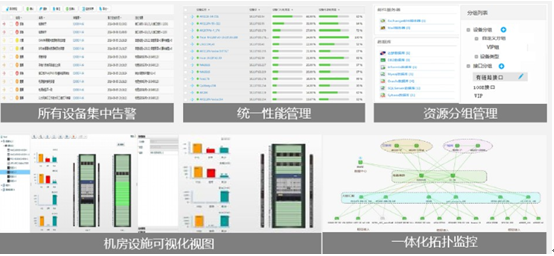
3 多种设备统一展现
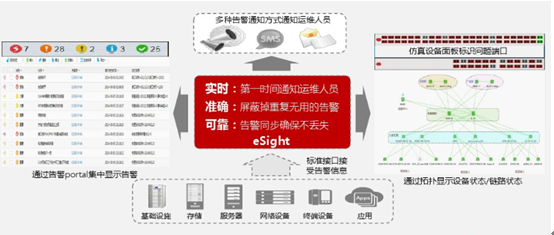
4 集中告警,实时通知运维人员
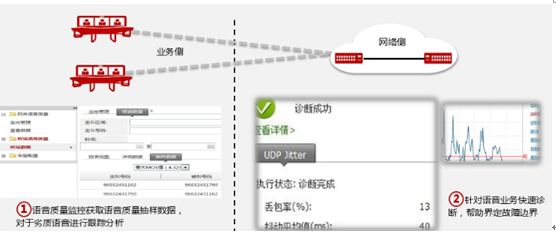
5 可视化诊断-故障根因
6 资源容量分析规划
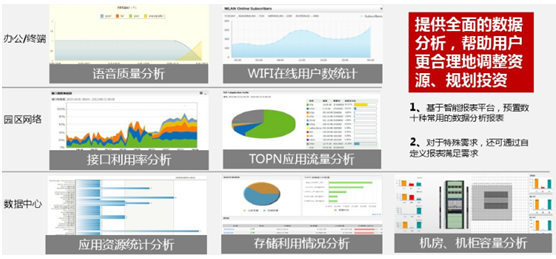
7 精细化网流分析
总结:这个阶段,数据中心的Ops走向了以资源为中心的平台化之路。
综述:传统数据中心时代,是网管类系统统一天下的时代,无论是设备网管还是第二代的统一运维系统,都是基于的网管模式,最主要的差异点是单款设备运维走向设备统一运维,这个阶段也是因为没有更丰富的应用,大部分的互联网的业务也才发展起步。
2.1 虚拟化时代
这个阶段主要是聚焦在提升数据中心资源利用率与对基础实施进行更敏捷的管理,因此从技术层面出现了计算虚拟化,存储虚拟化,网络虚拟化,因为这些技术的出现,进而演进为软件定义计算(SDC),软件定义存储(SDS),软件定义网络(SDN),软件定义数据中心等。
我们大致了解下这几个概念:
l 计算虚拟化:
如下图,传统应用是通过操作系统这个标准的中间介质使用硬件能力的,而计算虚拟化能力是在操作系统和硬件中间穿插的软件层,通过对所有OS发出的X86指令进行截获,转换为不对OS感知的多道执行环境的仿真操作,将裸机硬件在多个虚拟机之间进行时间和空间维度的共享。后续我们将这个计算虚拟化的软件层称之为Hypervisor。而Hypervisor从技术特点上又分为多种,此处对于Ops来说有点偏远,不做概述。
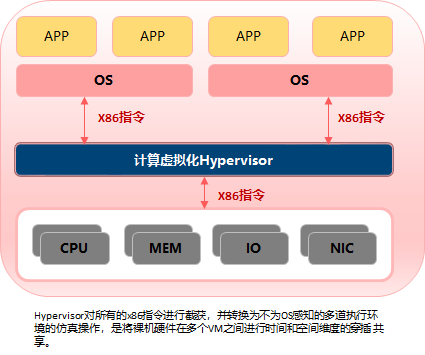
通常的Hypervisor软件堆栈分为如下两种:Xen和VMWare的ESXi属于第一种。KVM属于第二种。
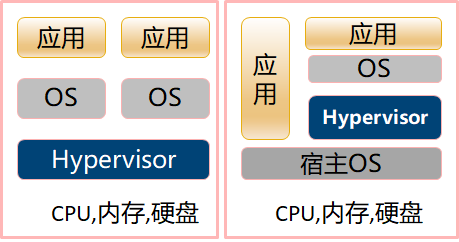
对于计算虚拟化后的输出就是虚拟机(vCPU,vNIC,Mem)以及可以部署在虚拟机上的OS(称为Guest OS)。在Hypervisor领域既有商业闭源的ESXi(VMWare),HyperV(微软),也有开源的Xen,KVM。并且KVM被集成进Linux内核,是目前使用最广泛的Hypervisor技术。
n 存储虚拟化:
如下图,Hypervisor对所有的来自应用软件层的存储数据面的IO读写指令尽心截获,建立从业务视角的覆盖多种存储资源的统一管理API,同时可实现多个对等存储节点的资源聚合。
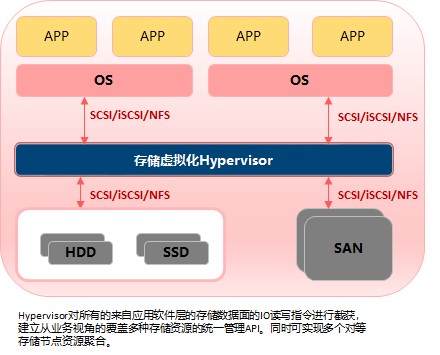
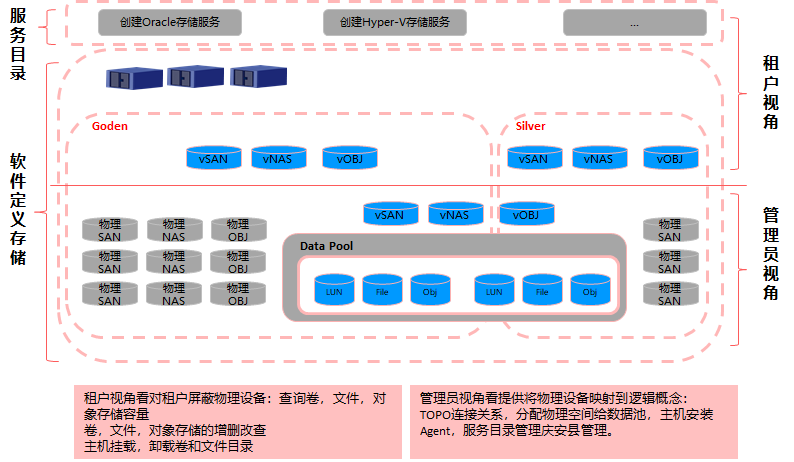
相比较于传统DC时代的存储设备,虚拟化后,存储虚拟化之后的形态,存储池(一个存储池包含LUN,文件,对象),卷,文件,桶。
n 网络虚拟化:
目前基本基于的开源的Open vSwitch实现虚拟交换机能力(openvSwitch是一个高质量的、多层虚拟交换机,使用开源Apache2.0许可协议,由 Nicira Networks开发,主要实现代码为可移植的C代码)。(说明:下面关于openvswitch的基本来自于网络相关资料,本篇之所以简要描述是为了弄清楚虚拟化后,相对于Ops来说的对象发生了哪些变化,因为这些变化对于Ops的相关发展产生什么影响)
在 OVS 中, 有几个非常重要的概念:
n Bridge: Bridge 代表一个以太网交换机(Switch),一个主机中可以创建一个或者多个 Bridge 设备。
n Port: 端口与物理交换机的端口概念类似,每个 Port 都隶属于一个 Bridge。
n Interface: 连接到 Port 的网络接口设备。在通常情况下,Port 和 Interface 是一对一的关系, 只有在配置 Port 为 bond 模式后, Port 和 Interface 是一对多的关系。
n Controller:OpenFlow 控制器。OVS 可以同时接受一个或者多个 OpenFlow 控制器的管理。
n datapath: 在 OVS 中,datapath 负责执行数据交换,也就是把从接收端口收到的数据包在流表中进行匹配,并执行匹配到的动作。
n Flow table: 每个 datapath 都和一个“flowtable”关联,当 datapath 接收到数据之后, OVS 会在 flow table 中查找可以匹配的 flow,执行对应的操作, 例如转发数据到另外的端口。
n ovs-vswitchd:守护程序,实现交换功能,和Linux内核兼容模块一起,实现基于流的交换flow-based switching。
n ovsdb-server:轻量级的数据库服务,主要保存了整个OVS的配置信息,包括接口、交换内容,VLAN等等。ovs-vswitchd会根据数据库中的配置信息工作。
基于vSwitch后数据流大致变化为如下:
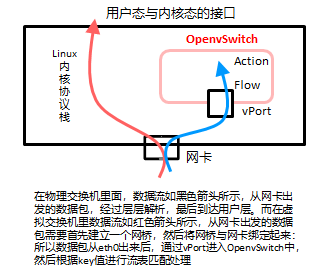
OpenvSwitch的模块结构图,主要分为三个部分,分别是外部控制器(Off-box)、用户态部分(User)和内核态部分(Kernel)。
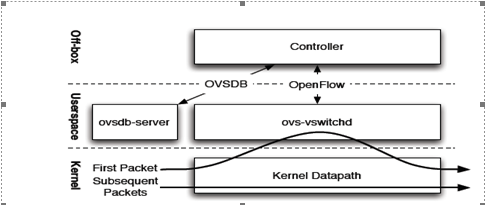
n 外部控制器:OpenvSwitch的用户可以从外部连接OpenFlow控制器对虚拟交换机进行配置管理,可以指定流规则,修改内核态的流表信息等。
n 用户态:主要包括ovs-vswitchd和ovsdb-server两个进程。ovs-vswitchd是执行OVS的一个守护进程,它实现了OpenFlow交换机的核心功能,并且通过netlink协议直接和OVS的内核模块进行通信。交换机运行过程中,ovs-vswitchd还会将交换机的配置、数据流信息及其变化保存到数据库ovsdb中,因为这个数据库由ovsdb-server直接管理,所以ovs-vswitchd需要和ovsdb-server通过Unix的soket机制进行通信以获得或者保存配置信息。数据库ovsdb的存在使得OVS交换机的配置能够被持久化存储,即使设备被重启后相关的OVS配置仍旧能够存在。
n 内核态:openvswitch_mod.ko是内核态的主要模块,完成数据包的查找、转发、修改等操作,一个数据流的后续数据包到达OVS后将直接交由内核态,使用openvswitch_mod.ko中的处理函数对数据包进行处理。
OVS交换机负责数据流发送的相关
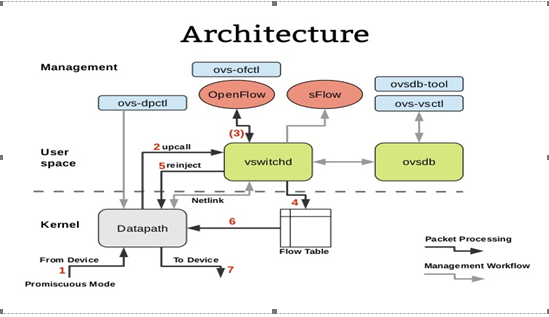
- OVS的datapath接收到从OVS连接的某个网络设备发来的数据包,从数据包中提取源/目的IP、源/目的MAC、端口等信息。
- OVS在内核状态下查看流表结构(通过Hash),观察是否有缓存的信息可用于转发这个数据包。
- 假设数据包是这个网络设备发来的第一个数据包,在OVS内核中,将不会有相应的流表缓存信息存在,那么内核将不会知道如何处置这个数据包。所以内核将发送upcall给用户态。
- 位于用户态的ovs-vswitchd进程接收到upcall后,将检查数据库以查询数据包的目的端口是哪里,然后告诉内核应该将数据包转发到哪个端口,例如eth0。
- 内核执行用户此前设置的动作。即内核将数据包转发给端口eth0,进而数据被发送出去。
- OVS交换机负责数据流接收的流程与上述流程类似,OVS为每个与外部相连的网络注册一个句柄,一旦这些设备在线上接收到了数据包,OVS将它转发到用户空间,并检查它应该发往何处以及应该对其采取什么动作。例如:如果是一个VLAN数据包,那么首先需要去掉VLAN tag,然后转发到对应的端口、
基于openvswitch实现网络虚拟化后,虚拟机之间的数据流量存在如下几种:
- 同一宿主机内的虚拟机之间互访流量
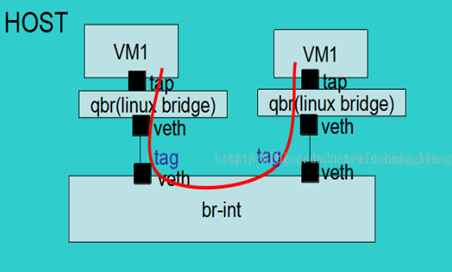
- 不同宿主机的虚拟机之间互访流量:
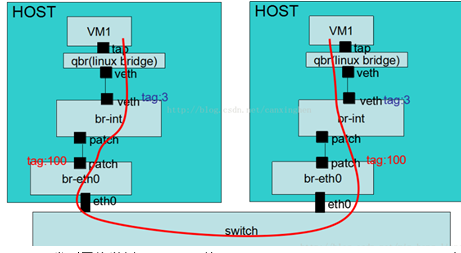
这里以vlan类型网络举例,network的segment_id为100,即vlan为100,虚拟机出来的报文在进入br-int网桥上被打上内部的vlan,举例来说打上vlan 3,下行的流量在经过对应的网络平面后,vlan会进行对应的修改,通过ovs的flow table把vlan修改成真实的vlan值100;上行流量在br-int网桥上通过flow table把vlan 100修改成内部的vlan 3,flat网络原理类似,下行流量会在br-eth通过flow table strip_vlan送出网口,vxlan类型的网络稍有不同,不过原理也是类似。
如果对于openstack的neutron网络模型,考虑上tenant network模型后,上述数据流实际还是会有所变化,就是是否要经过物理交换机经过public network的的router(虚拟路由器)。
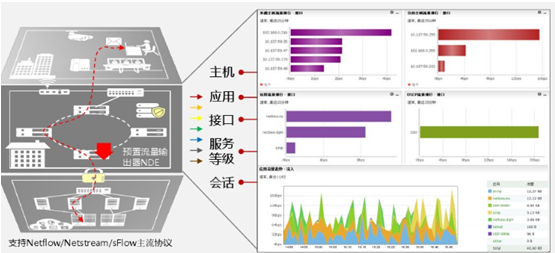
从网络虚拟化后可知,需要考虑几个问题:虚拟机的流量监控指标如何获取?虚拟网络下监控指标是否同传统设备时代相同?虚拟网络下的网络诊断如何进行?下面举几个例子:
l 1:申请的虚拟机,ping一个外部主机,譬如google。这个ping数据包会如下图所示
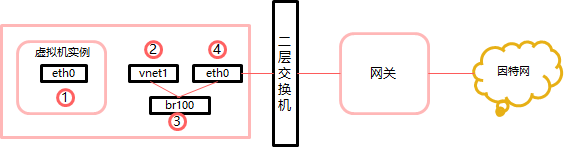
虚拟机实例生成一个数据包经过虚拟机网卡->传送到计算节点虚拟NIC:vnet1->传送到计算节点的一个网桥上br100->数据包传送到计算节点的主网卡eth0->传送到计算节点默认网关。而反过来就是ping答复的路径。可以看出数据包会经过四个不同的NIC。如果这些NIC中有一个出了问题,网络故障就会发生。所以ping不通,则缩小范围,ping计算节点IP,如果可以通过,则问题就在虚拟机实例与计算节点之间,问题出在包括连接计算节点的主NIC语实例的vnet NIC的桥接网络上。如果对于Neutron网络服务流量更加复杂些。传统网络诊断是无法诊断到宿主机内部的虚拟网络的数据流的
l 虚拟机正在运行,但是无法SSH访问,任何命令均无反应。此时VNC控制台可能显示kernel-panic错误日志,这表示VM本身的文件系统损坏了,此时如果希望恢复文件或查看虚拟机实例,可以使用qemu-nbd挂载磁盘。
l 计算节点彻底故障,譬如因为主板等硬件故障,此时其上的所有虚拟机实例都将无法使用,。如果基础监控没有检测到计算节点故障,其上虚拟机的所有用户都会投诉报障虚拟机实例无法访问。
基于上述虚拟化技术,形成了云计算领域的基础设施云平台类应用(CloudOS),如OpenStack,CloudStack等。意在构筑一个开放性的生态圈,从场景应用角度扩展了多租户,计算,存储,网络虚拟化的统一控制平台,集成更多异构虚拟化,跟多面向业务场景的模型对象。如上面所列举的场景,传统Ops是无法处理的么。传统的Ops建设与业务部门是分开的,不懂具体的业务场景和操作方式。
此时对于Ops来说,尤其是提供数据中心建设的IT企业的Ops产品来说,其Ops的对象不仅仅是物理设备,而是演进到需要Ops这种云平台应用,以及云平台应用所产生的业务对象(虚拟机,虚拟端口,虚拟路由等等),或是对其配置或是对其监控。因为触角已经延伸到应用和应用的业务,所以Ops的架构模式也发生了一定变化。一种是依然采用传统网管的模式,对于这种平台应用视为网元,依据各自业务完整性角度,此时则变为了业务系统自带一定维护监控能力,我们称之为O&M。这种的应用在这个阶段同时出现大数据平台,同样如此,这样可独立销售的模式。而这种O&M自带部署,监控,告警的初级能力。整个的Ops架构演进为了如下:
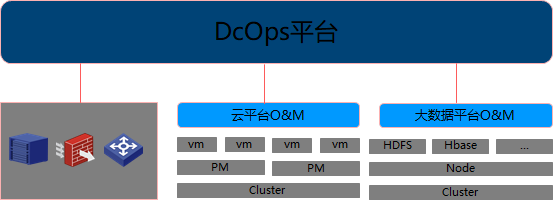
基于这种,统一Ops平台依旧可以通过业务系统O&M来获取虚拟管理单元进行监控与告警,而安装部署责任本来Ops平台的职责,丢给了业务单元。配置开通也完全丢给了业务单元。这样统一的Ops仅仅是做了有限的监控能力,而从业务操作场景上来看依旧多系统割裂跳转操作模式。
如果单从Ops的角度看,而沿用网管的这种思路,实际已经逐步难以适应,当Ops的对象触角已经延伸到应用以及业务,应该引起更高的警觉,从更广泛的角度去考虑:还有没有其它的应用?这些应用是否有如设备时代那么标准化(标准的协议:SNMP,MML等)是否应用都需要自建O&M?让应用自建O&M成本是否太大?O&M是否属于Ops?,结合后期的应用层面的深度运维技术的普及,譬如这种云平台内部调用异常如何Ops?笔者所在的环境是从传统设备行业走过来的,而Ops也依然停留在网管时代的思维,这个时候已经出现了很是尴尬的局面,譬如:第一代数据中心Ops平台是围绕物理设备的,基于标准的协议和数据承载格式(如SNMP/MIB库,IPMI等),标准的模型(框槽板卡口)。在研发的组织层面上也都是属于网管部门建设,但到了这个阶段,傻眼了,网管部门不懂云计算的业务和模型,没有标准的协议和模型,云计算在笔者所在的公司属于IT产品线,而网管属于中央软件院,这直接垮了一级的产品线。同时网管部门也没有习惯于与OM这类系统交互。类似此等窘迫的局面,就出现了另一种Ops的架构形态,如下图:
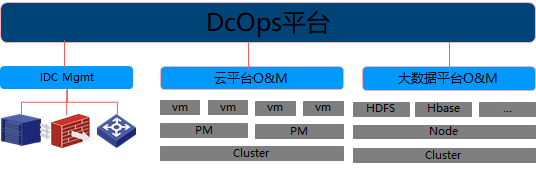
单独投资拉出了另一种产品,而将基于传统设备建立的第一代数据中心Ops平台降级为数据中心L1/L2的Ops。另起炉灶由IT线投资定位的数据中心统一管理平台。(体现了大厂真是有钱贼任性,大厂的部门强有多么的厚重,这背后堪称一部宫廷剧,譬如待基于L1/L2范围出身的第一代Ops开始意识到云计算的影响时开始也涉足云计算/大数据的Ops,这时候和IT线投资另搞的数据中心统一管理平台就开始了各种的撕逼大战,确实是屁股决定了脑袋的现实)
令人遗憾的。如果此时完全站在客户的角度看,如果客户自己开发了巨型的这种应用,Ops平台如何Ops?如何的部署,如何的监控?如果开放性并未作为一种呈现给客户的功能,依然体现在开发态,则Ops平台的开发团队陷入永无止尽的适配接入。实际上在虚拟化以及基础设施云平台稳定就绪后,迎来的All Cloud时代,这种问题彻底的爆发。此后面All Cloud时代阐述。
总结下:这个时代Ops已经触角延伸到应用和业务(实际可能更早,互联网是从应用这种由上往下发展Ops,传统设备企业是从设备往下往上发展)。此时的Ops触角已经延伸到了应用和业务,但是依然未向后来All Cloud时代版商业模式发生颠覆,走的传统解决方案-产品分销模式,依旧只Care资源为中心的Ops时代,同时对于Ops的流程上依旧没有产生后来Cloud时代的哪种要求。
3.1 All Cloud时代
1.1.1 私有云
2.1.1 公有云
3.1.1 混合云
3 架构
1.1 业务
根据前面章节的介绍了解,站在数据中心的角度(云的物理承载体就是数据中心),Ops的建设思路基本如下:
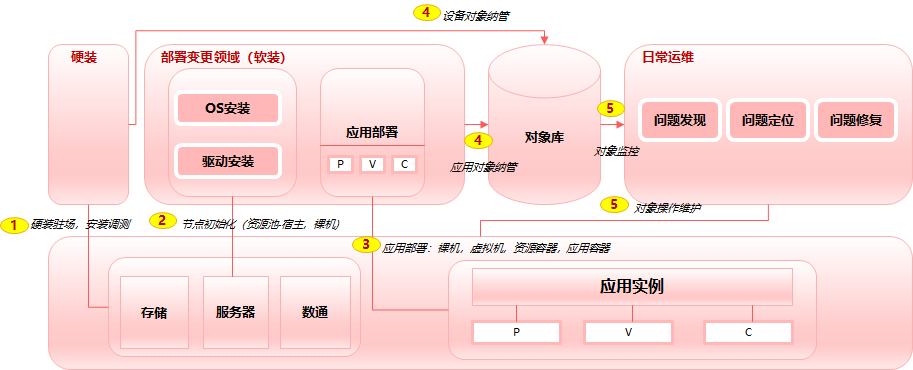
上述流程概述下为:资产采购到位后,硬装部署调测,硬装包含:L0层空调机房电力,L1层:数通,存储,服务,安全等设备,硬装完毕后软装部署调测,包含服务器上OS,以及相对应的驱动安装,服务器包含虚拟化场景下(包含容器化)资源池宿主机以及独立裸机部署的节点,也可认为是节点初始化过程。节点初始化就绪后,是软件部署,涉及裸机部署,虚拟机部署,资源容器/应用容器部署,应用部署之后产生了应用实例。应用实例,以及应用实例的承载体(裸机,虚拟机,容器)以及L0,L1层设备对象统一纳管写入对象库。日常运维的目标对象则是这些被纳管的对象,基于问题发现-定位-修复构筑自治的体系。基于上述的流程,我们打开每个步骤,看齐面对的场景有哪些,做一定的归纳整理抽象,进而给出自动化运维平台的L0层,L1层,L2层业务架构视图。
1.1 L0层
本层视图是解析一个运维平台对上需要解决的场景问题,对下是输入的对象。从前面章节介绍,Ops平台剑指的是交付和运维环节。而对于交付则应该从顶层数据中心开始。数据中心是个物理的概念,实际在业务上是不同的逻辑对象,我们以最复杂的公有云场景来说。公有云的位置逻辑模型如下:
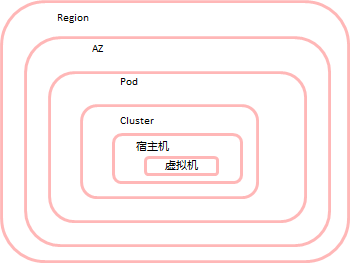
最顶层是Region,也就是大家在公有云服务网站上看到的譬如华北区,华南区这种,一般region的建设是根据物理传输的距离(带宽时延)以及国家地域因素(譬如跨国,隐私法规问题)。一个Region包含多个AZ。AZ实际对应的可以认为是物理上的机房概念,譬如一个华北的region下可以建设北京AZ和廊坊AZ。之间走内部VPN等网络,一个region下不同的AZ之间传输时延一般很小。而Pod一般指I层云平台所管理的范围。一个Pod则可认为是一个云平台实例管理的范围。集群是I层资源池的资源集合,根据不同的维度划分,譬如可以根据Hypervisor划分:KVM集群,XEN集群。也可以根据资源的等级,譬如GPU集群,IB高性能网络集群,资源容器集群等。(当然不是绝对的,可以按照资源等级对应到不同的Pod上)。对上述一个直观的展现,譬如公有云的组网和业务部署模型如下:
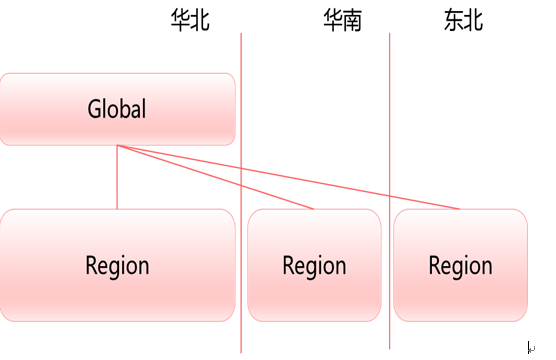
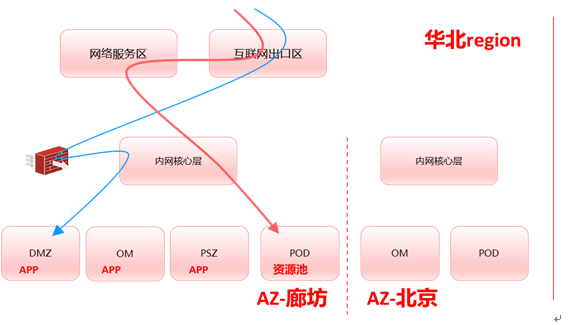
而打开包含Global域的region,内部组网大致又分为如下
实际操作上,公有云系统的组建也是基于上述逻辑模型进行流水线操作的,譬如建设公有云,规划了华北region,则初始应该是新建region,譬如随着租户增多,需要扩容region,或者是新建AZ或者是已有AZ扩容Pod。而在公有云组件完毕后,随着业务的发展,涉及频繁的服务上线,扩容,变更。也涉及运行过程中的问题如何主动发现,定位,修复,或者租户投诉报障过来如何高效便捷的运作流转。
归纳整理下,一个自动化运维平台的L0层视图概述为如下:
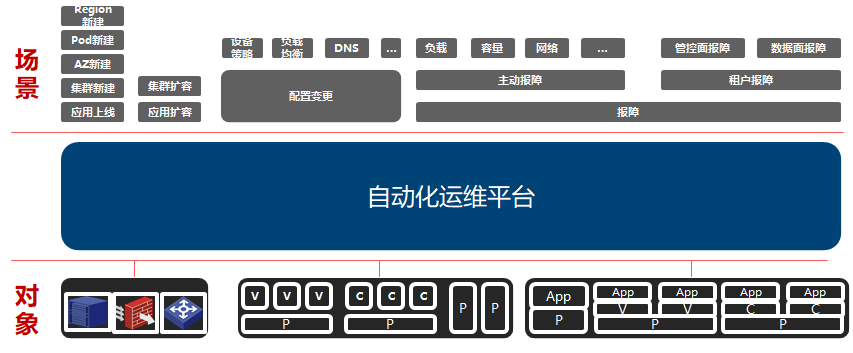
整体分为三个场景:上线场景,变更场景,报障场景。场景往往是最原始的诉求,而对应到软件层面,则是基于技术的维度考虑,譬如基于职责单一,基于数据特征,基于可复用,可扩展等等多种维度需要进行解析拆分为不同的单元(领域/服务),在考虑不同的场景如何组装这些单元(此处有涉及不同的指标:易用性等)。业务架构本质就是基于中心思想和场景需求进行解析和组装的过程。
1.2 L1层
根据前面所述,场景分为三块,上线场景,变更场景,报障场景。挨个打开各场景来概述。
对于上线场景,基本流程如下:
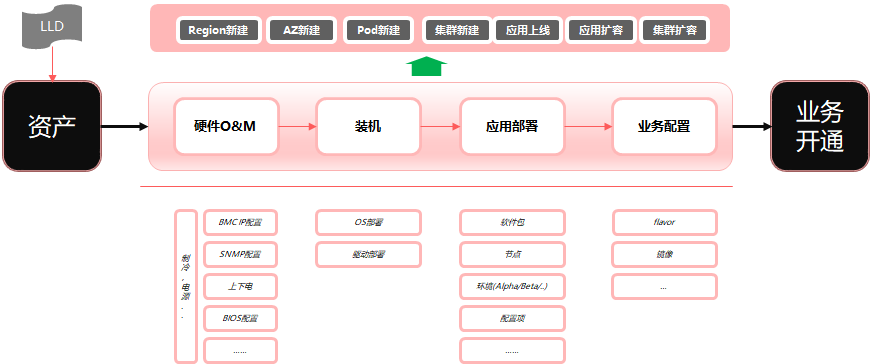
数据中心规划,最终输出LLD清单-资产采购。采购到货后根据数据中心规划进行L0层,L1层的部署调测(上架,接线,配置..),其次软装开始,装机,应用,配置,最后业务开通。根据上述流程我们划分为如下服务。
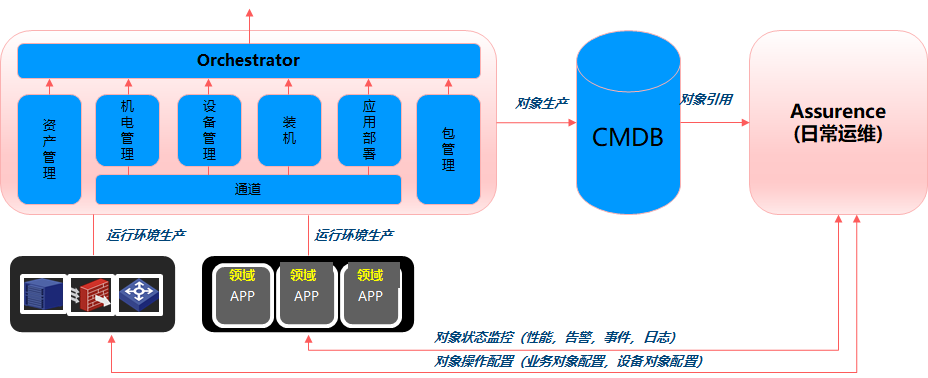
整体边界:负责业务进程起来之前的生命周期,