2017.07.28 Python网络爬虫之爬虫实战 今日影视2 获取JS加载的数据
1.动态网页指几种可能:
1)需要用户交互,如常见的登录操作;
2)网页通过js / AJAX动态生成,如一个html里有<div id="test"></div>,通过JS生成<divid="test"><span>aaa</span></div>;
3)点击输入关键字后进行查询,而浏览器url地址不变
2.想用Python获取网站中JavaScript返回的数据,目前有两种方法:
第一种方法:直接url法
(1)认真分析页面结构,查看js响应的动作;
(2)借助于firfox的firebug分析js点击动作所发出的请求url;
(3)将此异步请求的url作为scrapy的start_url或yield request再次进行抓取。
第二种方法:借助于selenium
Selenium基于JavaScript 并结合其WebDriver来模拟用户的真实操作,它有很好的处理Ajax的能力,并且支持多种浏览器(Safari,IE,Firefox,Chrome),可以运行在多种操作系统上面,Selenium可以调用浏览器的API接口,selenium 会打开一个浏览器,然后在新打开的浏览器中执行程序中模拟的动作。
如图:

3.下面安装Selenium模块:

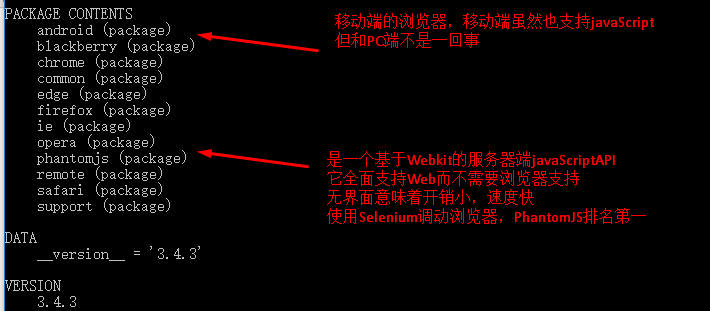
4.浏览器的选择:在编写Python网络爬虫时,主要用到Selenium的Webdriver,Selenium.Webdriver不可能支持所有浏览器,也没必要支持所有浏览器。
Webdriver支持列表:
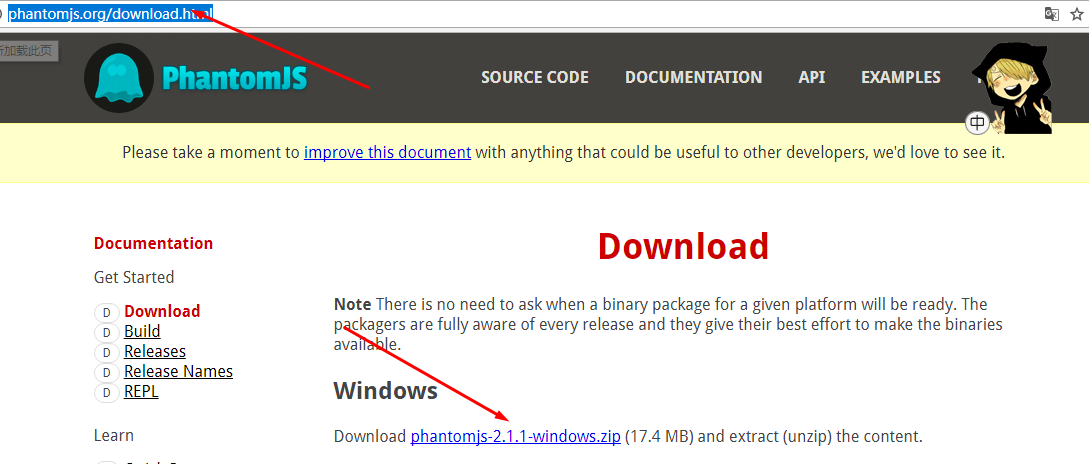
5.安装PhantomJS:
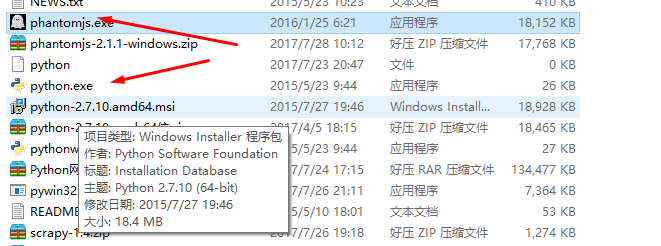
下载解压后,和python放到一个文件夹:
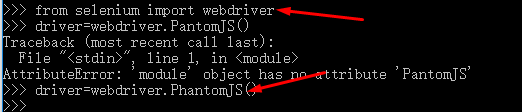
windows下的PhantomJS环境配置好后,测试成功:
6.Selenium&PhantomJS抓取数据:
(1)网站获取返回数据
(2)定位“有效数据”的位置
(3)从定位中获取“有效数据”
7.以百度搜索为例,使用百度搜索“python selenium”,并保存第一页搜索结果的标题和链接:
(1)获取搜索结果:直接用Selenium&PhantomJS打开百度首页,然后模拟搜索关键字
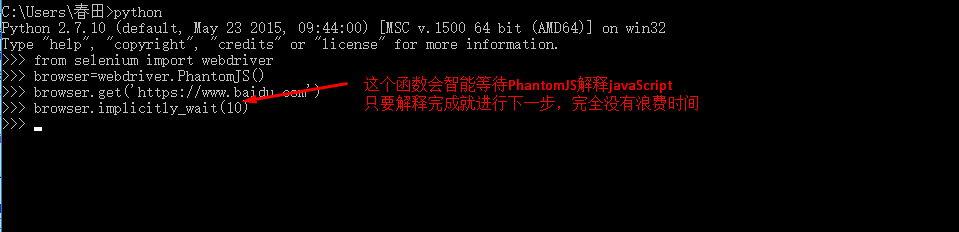
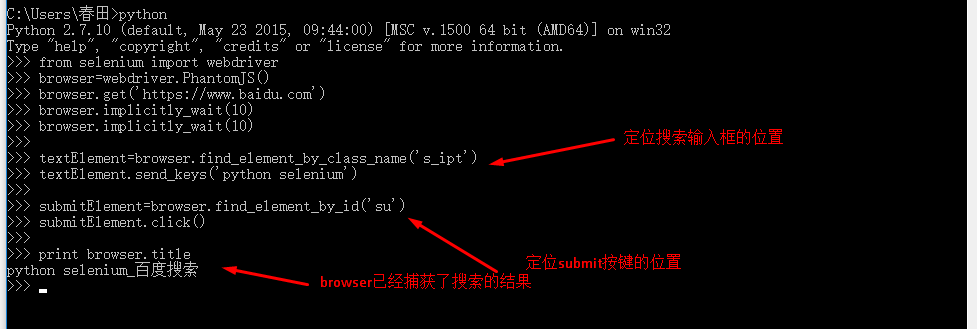
(2)定位表单框架或“有效数据”位置,可以用import导入bs4来完成,也可以用Selenium本身自带的函数完成:总共有8中F方法从返回数据中定位“有效数据”:

可以看出文本框里有class,name,id属性,可以使用find_element_by_class_name,find_element_by_id,find_element_by_name来定位:
下边三个定位函数任意选择一个:
textElement=browser.find_element_by_class_name('s_ipt')
textElement=browser.find_element_by_id('kw')
textElement=browser.find_element_by_name('wd')
发送搜索关键字:
textElement.send_keys('python selenium')
定位提交按钮:

从图中可以看出,submit按键有id,class属性,可以用find_element_by_class_name和find_element_by_id定位:
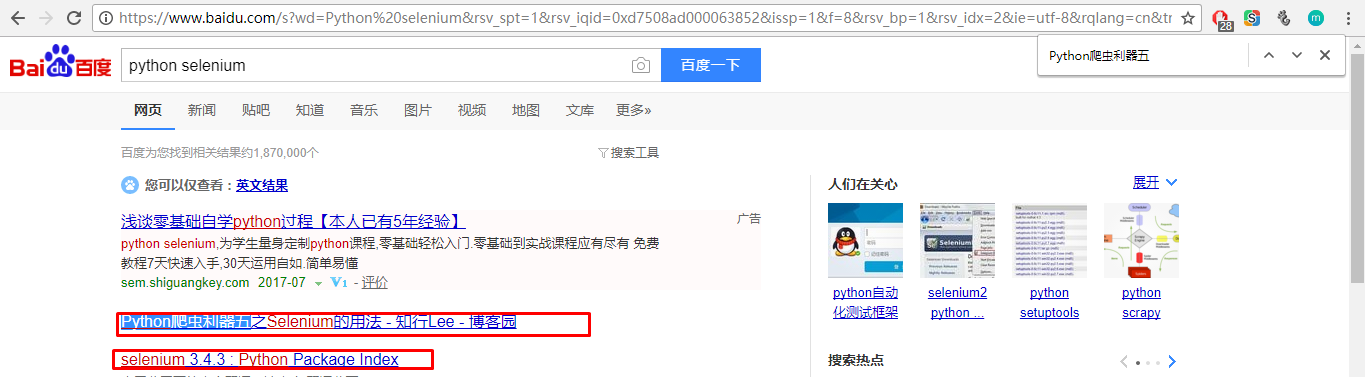
8.获取有效数据的位置:先定位搜索结果的标题和链接:查看搜索结果的源码:
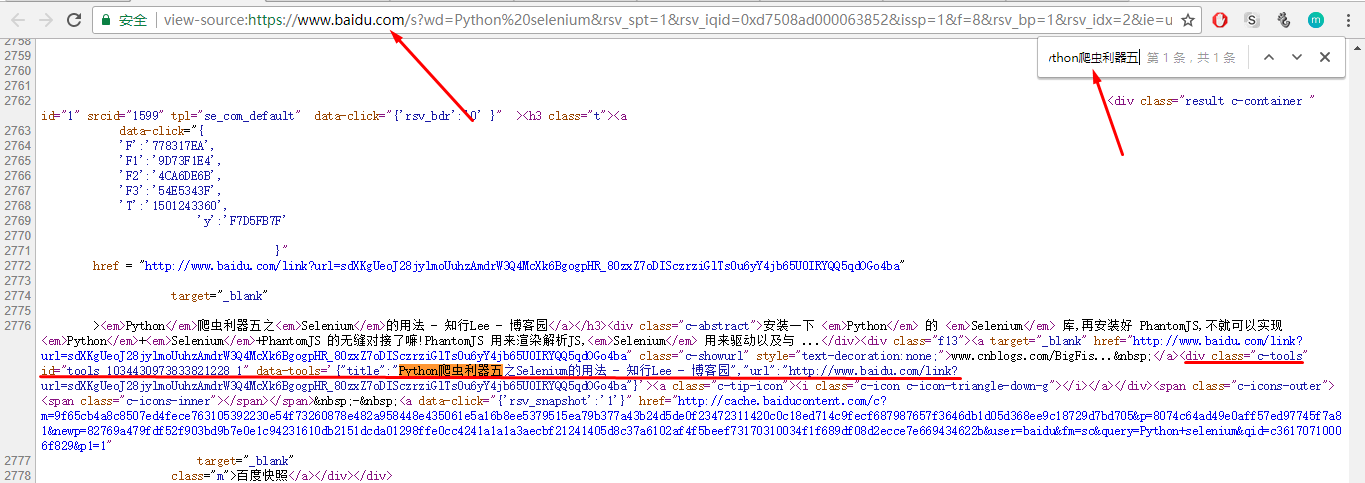
发现一个特殊属性:class="c-tools",搜索这个属性:
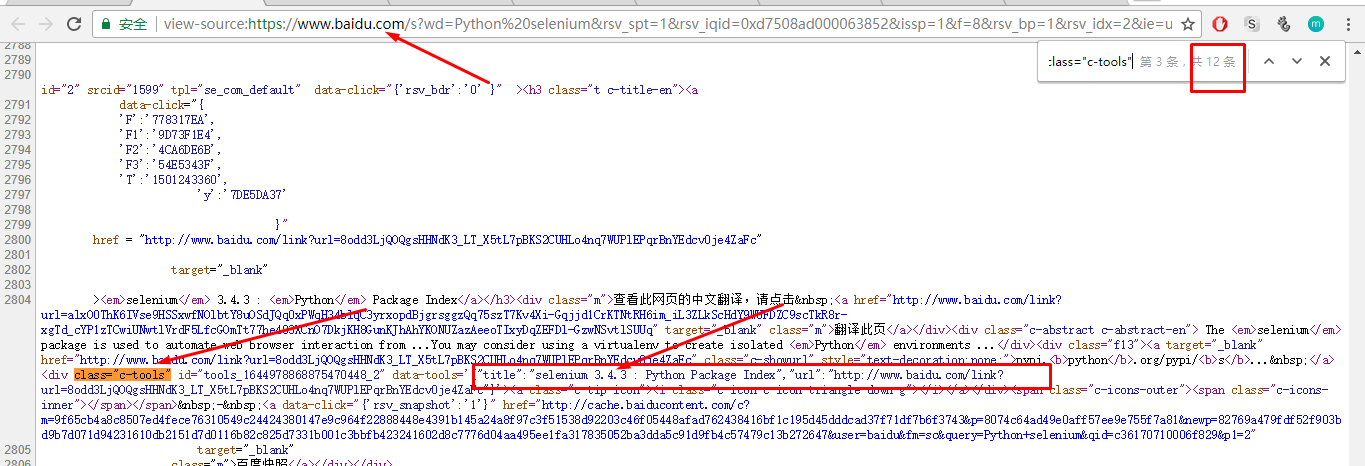
发现一共12条,并且第二条搜索结果的标题和搜索页面中的第二个搜索结果相同,可以确定所有的搜索结果中都包含class="c-tools"标签
可以用find_element_by_class_name定位所有搜索结果了:

9.从位置中获取有效数据:有效数据的位置确定后,如何从位置中过滤出有效的数据呢?
Selenium有自己独特的方法:
element.text()
element.get_attribute(name)

所需的有效数据就是data-tools属性的值:执行命令

遍历resultElements列表,可以获取所有搜索结果的title和url。
