2017.07.26 Python网络爬虫之Scrapy爬虫实战之今日影视
1.创建项目:前提是在环境变量中添加了:
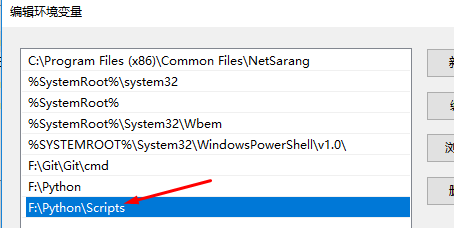
可以运行命令scrapy:
(1).scrapy startproject todayMovie

(2).scrapy genspider wuHanMovieSpider jycinema.com(搜索域)

创建scrapy项目后的文件目录结构是:

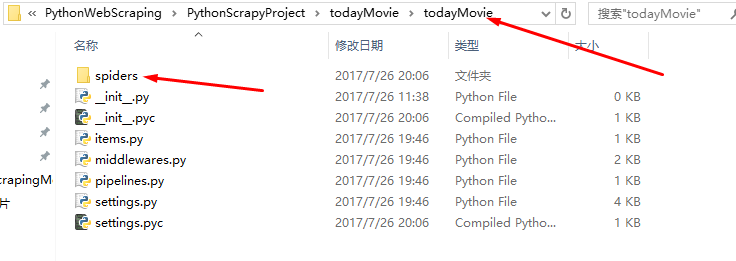
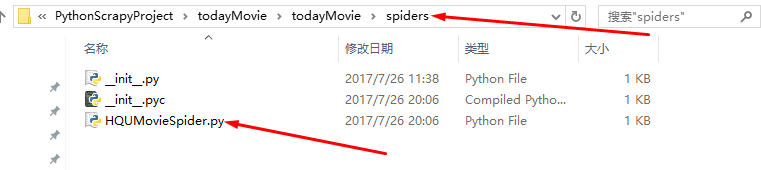
2.Scrapy文件介绍:
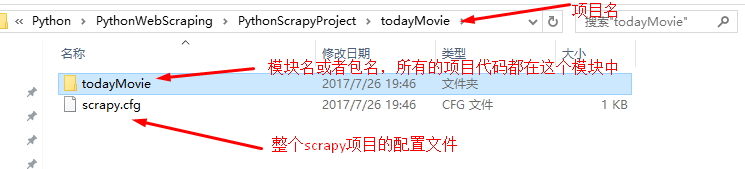
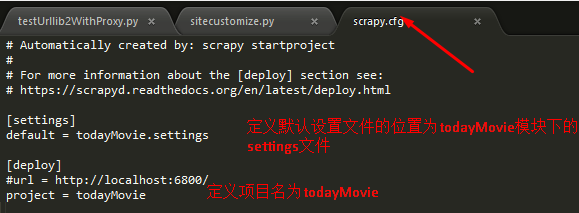
scrapy.cfg文件的意义:
第三层todayMovie模块文件夹下的文件说明:
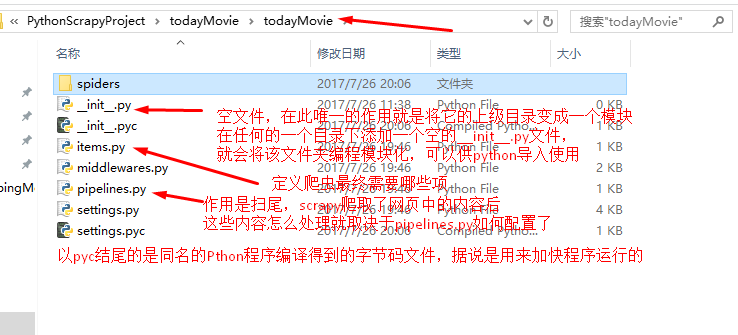
在本次项目中需要修改的只有4个文件,分别是:items.py,settings.py,pipelines.py和HQUMovieSpider.py
items.py:决定爬取哪些项目
HQUMovieSpider.py:决定怎么爬取
settings.py:决定由谁去处理爬取的内容
pipelines.py:决定爬取后的内容怎么处理
3.Scrapy爬虫编写:
(1)选择爬取的项目items.py:修改items.py文件

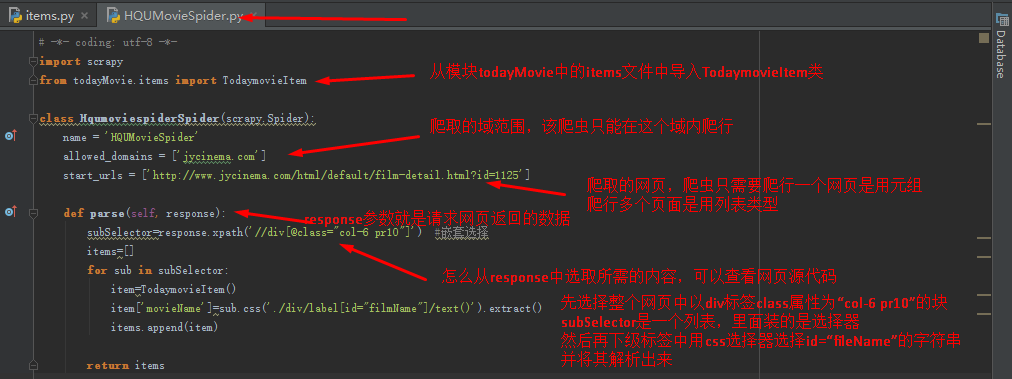
(2)定义怎么爬取HQUMovieSpider.py:
# -*- coding: utf-8 -*-
import scrapy
from todayMovie.items import TodaymovieItem
class HqumoviespiderSpider(scrapy.Spider):
name = 'HQUMovieSpider'
allowed_domains = ['jycinema.com']
start_urls = ['http://www.jycinema.com/html/default/film-detail.html?id=1125']
def parse(self, response):
subSelector=response.xpath('//div[@class="col-6 pr10"]') #嵌套选择
items=[]
for sub in subSelector:
item=TodaymovieItem()
item['movieName']=sub.css('./div/label[id="filmName"]/text()').extract()
items.append(item)
return items
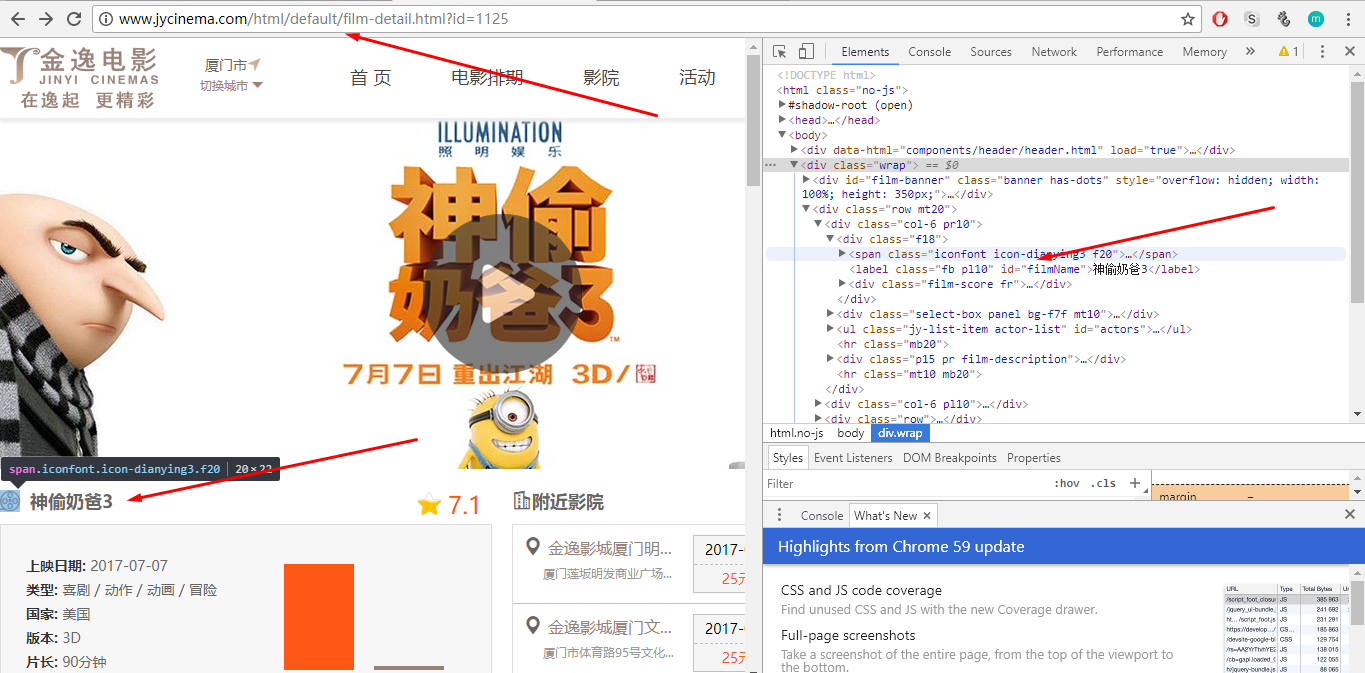
选择器的选择到底对不对?验证一下,在该项目的任意一级目录下执行:
scrapy shell http://www.jycinema.com/html/default/film-detail.html?id=1125
发现报错:

这是因为Python没有自带访问windows系统API的库的,需要下载第三方库。库的名称叫pywin32,可以从网上直接下载
下载链接:http://sourceforge.net/projects/pywin32/files%2Fpywin32/ (下载适合你的Python版本)
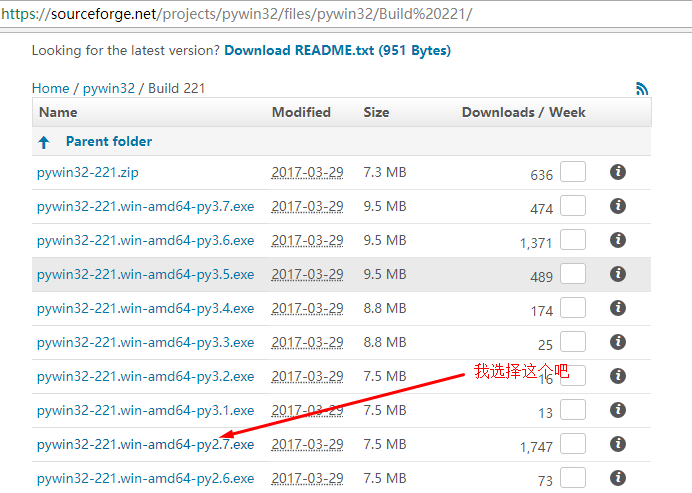
然后在cmd运行(因为我之前就配置过环境变量为F:\Python\Scripts)所以可以直接在cmd下运行easy_install命令:
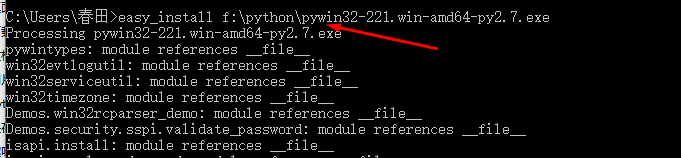

问题解决!!!
(3)继续测试选择器的选择是否正确,在该项目任意的一级目录下执行命令:scrapy shell http://www.jycinema.com/html/default/film-detail.html?id=1125
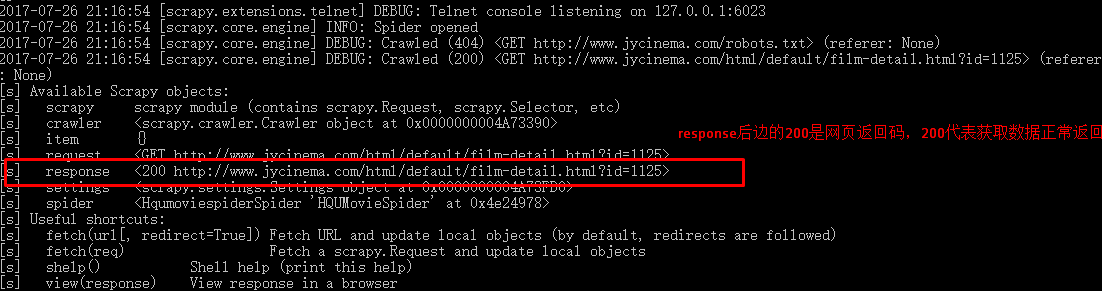
测试发现选择器选择失败!!
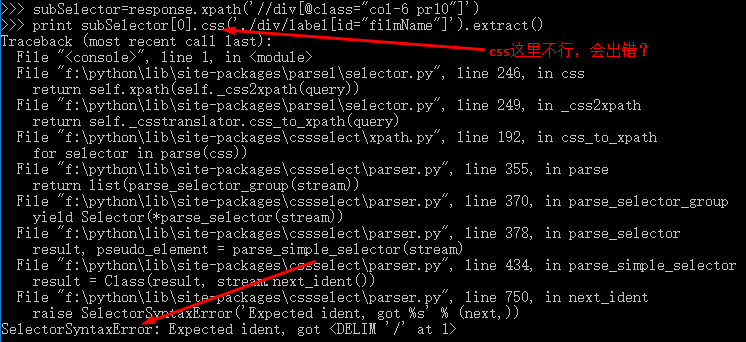
换了其他路径发现,返回是空的列表,貌似这个数据是JS动态加载的,所以获取不到:(其实是ajax动态页面)
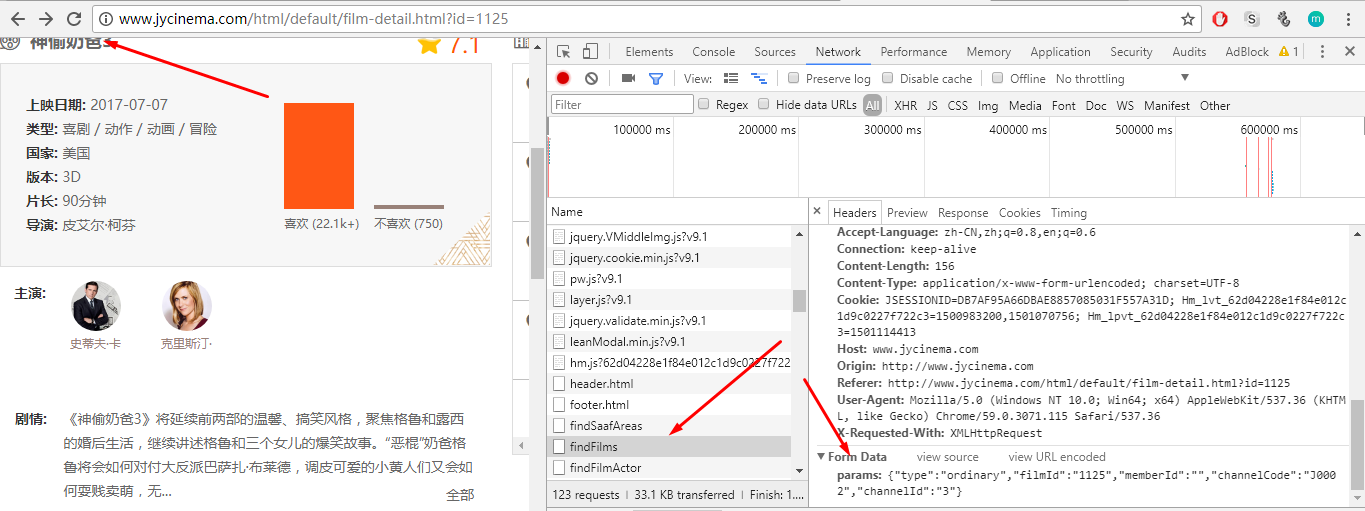
FormData类型其实是在XMLHttpRequest 2级定义的,它是为序列化表以及创建与表单格式相同的数据(当然是用于XHR传输)提供便利。
XMLHttpRequest Level 2添加了一个新的接口FormData.利用FormData对象,我们可以通过JavaScript用一些键值对来模拟一系列表单控件,我们还可以使用XMLHttpRequest的send()方法来异步的提交这个"表单".比起普通的ajax,使用FormData的最大优点就是我们可以异步上传一个二进制文件.
打开谷歌浏览器,按F12打开Network界面,查看web和后端做了哪些交互, 参数和数据都在Network中可以看到:
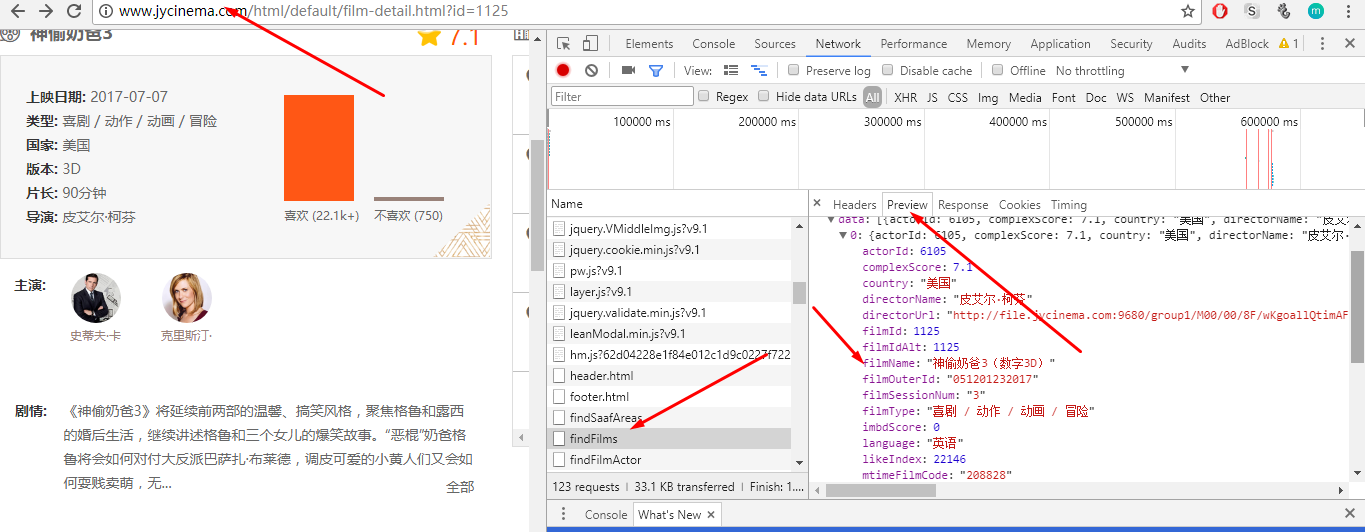
关于Scrapy抓取动态页面数据的方法,在下一篇文章中介绍吧。哎,我也很无奈啊

 浙公网安备 33010602011771号
浙公网安备 33010602011771号