2017.07.26 Python网络爬虫之Scrapy爬虫框架
1.windows下安装scrapy:cmd命令行下:cd到python的scripts目录,然后运行pip install 命令

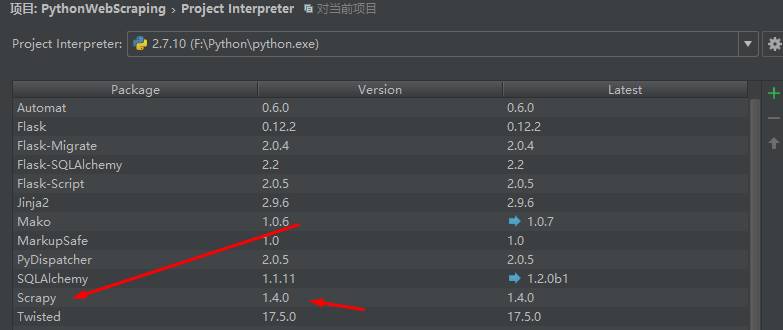
然后pycharmIDE下就有了Scrapy:
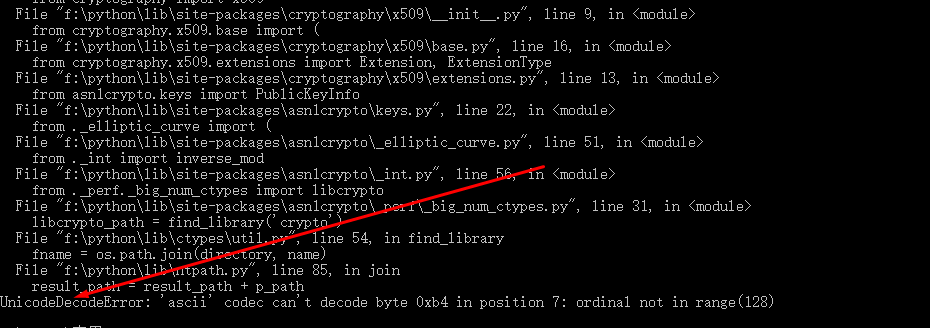
在cmd下运行scrapy命令,出错!!!:
解决方法:
在Python的Lib\site-packages文件夹下新建一个sitecustomize.py:
import sys sys.setdefaultencoding('gb2312')
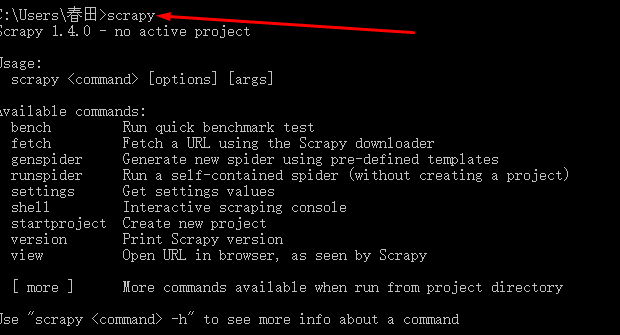
再次在cmd下运行scrapy,成功:
2.Scrapy选择器和XPath和CSS:通过特定的XPath或者CSS表达式来选择HTML文件中的某个部分
(1)XPath是一门用来在XML文件中选择节点的语言,也也可以用在HTML上,是一门在XML文档中查找信息的语言,XPath可以用来在XML文档中对元素和属性进行遍历。
XPath含有超过100个内建的函数,这些函数用于字符串值,数值,日期和时间比较,节点和QName处理,序列处理,逻辑值等等
(2)在XPath中,有7种类型的节点:元素,属性,文本,命名空间,处理指令,注释以及文档节点(或称为根节点)。XML文档是被作为节点树来对待的,树的根被称为文档节点或者根节点
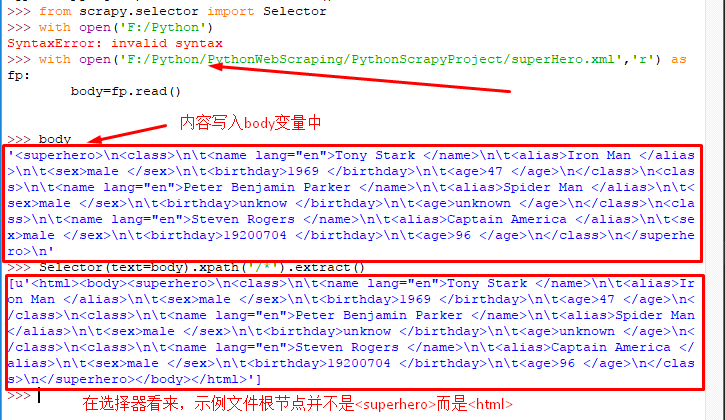
做个简单的XML文件:
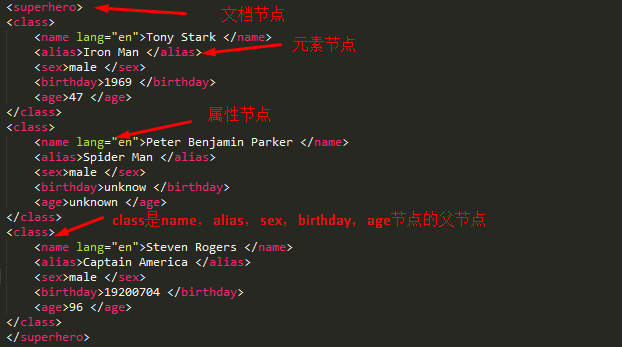
<superhero>
<class>
<name lang="en">Tony Stark </name>
<alias>Iron Man </alias>
<sex>male </sex>
<birthday>1969 </birthday>
<age>47 </age>
</class>
<class>
<name lang="en">Peter Benjamin Parker </name>
<alias>Spider Man </alias>
<sex>male </sex>
<birthday>unknow </birthday>
<age>unknown </age>
</class>
<class>
<name lang="en">Steven Rogers </name>
<alias>Captain America </alias>
<sex>male </sex>
<birthday>19200704 </birthday>
<age>96 </age>
</class>
</superhero>
(3)XPath使用路径表达式在XML文档中选取节点:常用的路径表达式如下:
nodeName:选取此节点的所有子节点
/:从根节点选取
//:从匹配选择的当前节点选择文档中的节点,不考虑它们的位置
.:选取当前节点
..:选取当前节点的父节点
@:选择属性
*:匹配任何元素节点
@*:匹配任何属性节点
Node():匹配任何类型的节点
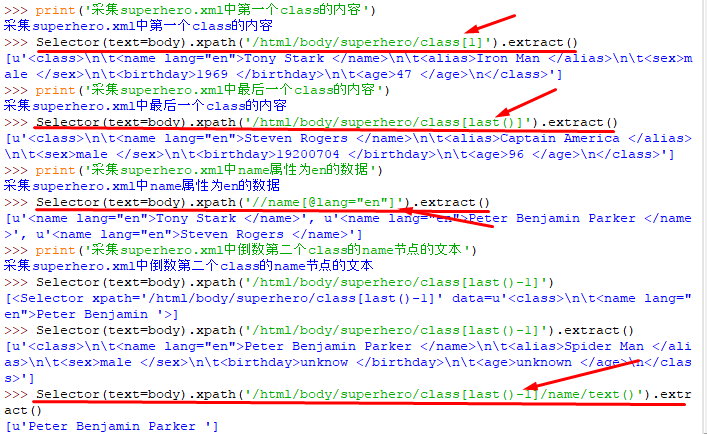
(4)XPath选择器如何收集数据:
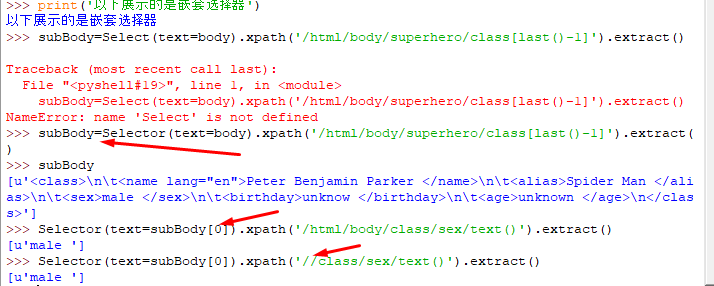
(5)嵌套选择器:
3.CSS选择器(层叠样式表):CSS规则由两个主要的部分构成:选择器,以及一条或多条声明
selector{declaration1;declaration2;.......declarationN}
CSS选择器: 例子:
.class .intro 选择class="intro"的所有元素
#id #firstname 选择id="firstname"的所有元素
* * 选择所有元素
element p 选择所有<p>元素
element,element div,p 选择所有<div>元素和所有<p>元素
element element div p 选择<div>元素内部的所有p元素
[attribute] [target] 选择带有target属性的所有元素
[attribute=value] [target=_blank] 选择target="_blank"的所有元素
4.CSS选择器测试:
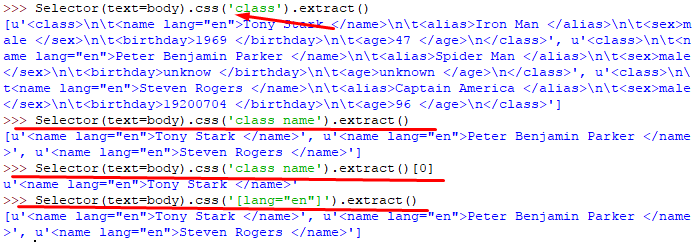
5.其他选择器:
XPath选择器还有一个.re()方法,用于通过正则表达式来提取数据,然而不同于使用.xpath()或者css(),,re()方法返回unicode字符串的列表。所以。无法构造嵌套的.re()调用


 浙公网安备 33010602011771号
浙公网安备 33010602011771号