
Redis 学习笔记1:数据类型
Redis支持五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及 zset(sorted set:有序集合)。
一、Redis 数据类型-STRING
1、常用命令

SET key value #存 GET key #取 Del key #删除key INCR key #自增key对应的value的值,增量为1 INCRBY key increment #自增key对应的value的值,增量为 increment DECR key #递减key对应的value的值,增量为-1 getset key value #命令用于设置指定 key 的值,并返回 key 的旧值。 当 key 没有旧值时,即 key 不存在时,返回 nil 当 key 存在但不是字符串类型时,返回一个错误
2、实例
实例1: set key value
D:\Redis>redis-cli.exe -h 127.0.0.1 -p 6379 127.0.0.1:6379> set set:test 1 # 返回ok 说明成功 OK 127.0.0.1:6379> set set:test1 1 OK 127.0.0.1:6379> set set:test2 1 OK 127.0.0.1:6379> keys * # 列出所有的key 1) "set:test" 2) "set:test2" 3) "set:test1" 127.0.0.1:6379> set system:user 1 OK 127.0.0.1:6379> set system:role 1 OK 127.0.0.1:6379> set system:group 1 OK 127.0.0.1:6379> keys * 1) "system:role" 2) "set:test" 3) "set:test1" 4) "set:test2" 5) "system:group" 6) "system:user" 127.0.0.1:6379>
说明:
set system:user 1
key就是 system:user ;value就是1
实例2:切库
127.0.0.1:6379> select 1 OK 127.0.0.1:6379[1]> keys * (empty list or set) 127.0.0.1:6379[1]> select 0 OK 127.0.0.1:6379> keys * 1) "system:role" 2) "set:test" 3) "set:test1" 4) "set:test2" 5) "system:group" 6) "system:user" 127.0.0.1:6379>
在 redis.conf 文件中,配置项 database 16 设置了数据库的数量为16,默认数据库是0。
可以使用select 命令在连接上指定数据库id。
当我们没有默认选择库时,默认使用 0 库。
实例3:get key
127.0.0.1:6379> set a 1 OK 127.0.0.1:6379> get a "1" 127.0.0.1:6379> set b {a:b,1:2} OK 127.0.0.1:6379> get b "{a:b,1:2}" 127.0.0.1:6379>
实例4:del key
127.0.0.1:6379> keys * 1) "system:role" 2) "b" 3) "set:test" 4) "set:test1" 5) "set:test2" 6) "system:group" 7) "system:user" 8) "a" 127.0.0.1:6379> del a # 删除成功 (integer) 1 127.0.0.1:6379> keys * 1) "system:role" 2) "b" 3) "set:test" 4) "set:test1" 5) "set:test2" 6) "system:group" 7) "system:user" 127.0.0.1:6379> 127.0.0.1:6379> del a #删除失败 (integer) 0
实例5:递增key
127.0.0.1:6379> incr test (integer) 1 127.0.0.1:6379> get test "1" 127.0.0.1:6379> incr test (integer) 2 127.0.0.1:6379> get test "2" 127.0.0.1:6379> incr test (integer) 3 127.0.0.1:6379> get test "3" 127.0.0.1:6379> incrby test 3 (integer) 6 127.0.0.1:6379> get test "6"
当值(字符串)里是数字时,才可以自增。
实例6:递减key
127.0.0.1:6379> DECR test (integer) 5
实例7:先取再设置(同时进行)
127.0.0.1:6379> getset test1 1 (nil) 127.0.0.1:6379> get test1 "1" 127.0.0.1:6379> getset test1 2 "1" 127.0.0.1:6379> get test1 "2" 127.0.0.1:6379>
redis getset 命令用于设定指定key的值,并返回key的旧值。
3、STRING 类型的实际场景
场景1:做商品详情和缓存
127.0.0.1:6379> set spu:10001 '{"color":"red","struct":"glass","length":30,"width":25,"price":"1345.20"}' OK 127.0.0.1:6379> get spu:10001 "{\"color\":\"red\",\"struct\":\"glass\",\"length\":30,\"width\":25,\"price\":\"1345.20\"}" 127.0.0.1:6379>
说明:比如客户端发起请求查询 sup:10001 商品信息,api程序先去redis拿,拿到了就直接返回给api程序,api返回给客户端,这样就起到了做缓存的目的。
场景2:给数据做唯一编码
有一些数据需要唯一的编码去命名,如用例编码。
使用redis 用incr 生成用例编码
127.0.0.1:6379> incr test_case_no (integer) 1 127.0.0.1:6379> incr test_case_no (integer) 2 127.0.0.1:6379> incr test_case_no (integer) 3
场景3:做分布式锁
1、什么是分布式锁:针对多服务的情况,在外面加个分布式锁,每个服务都要在获得分布式锁后进行操作。
2、Redis为什么可以做分布式锁:因为redis是单线程运行的,没有并发,所有请求都是一个一个操作。
3、redis怎么做分布式锁:
expire [key] time #设置一个key有效期
exists [key] # 判断key是否存在
伪代码:
先判断锁是否存在(key存在,exists): 如果存在:pass 如果不存在:set key 'xxx' && 设置过期时间 操作
4、如何设置过期时间&如何判断key是否存在
127.0.0.1:6379> set hqq2 'a' OK 127.0.0.1:6379> exists hqq2 #判断key是否存在 (integer) 1 127.0.0.1:6379> expire hqq2 10 #设置过期时间为10s (integer) 1 10秒后再次操作 127.0.0.1:6379> exists hqq2 (integer) 0 127.0.0.1:6379>
5、设置过期时间的实际应用场景:
set key '限时活动' expire key 10 while get key: 继续活动 活动结束
127.0.0.1:6379> set 618day 'huodong' OK 127.0.0.1:6379> expire 618day 100 (integer) 1 127.0.0.1:6379> get 618day "huodong" 127.0.0.1:6379> get 618day (nil)
4、总结STRING
1、一个key对应一个value
2、Redis的String可以包含任何数据,比如 jpg图片或者序列的对象
3、一个key最大能存储512MB
二、Redis 数据类型-HASH
1、什么是哈希值
哈希值是通常用一个短的随机字母和数字组成的字符串来代表,是一组任意长度的输入信息通过哈希算法得到的“数据指纹”。因为计算机在底层机器码是采用二进制的模式。因此通过哈希算法得到的任意长度的二进制值映射为较短的固定长度的二进制值,即哈希值。此外,哈希值是一段数据唯一且极其紧凑的数值表示形式,如果通过哈希一段明文得到哈希值,哪怕只更改该段明文中的任意一个字母,随后得到的哈希值都将不同。
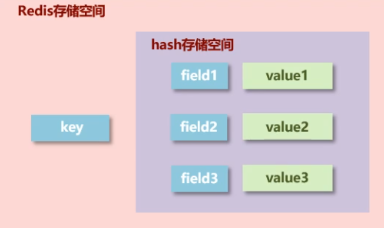
Redis hash 是一个键值对集合;
Redis hash 是一个string类型的field 和 value 的映射表;
hash 适合存储对象
3、设置
127.0.0.1:6379> hset htest1 key1 1 (integer) 1 127.0.0.1:6379> hget htest1 key1 "1" 127.0.0.1:6379> hset htest1 key2 2 (integer) 1 127.0.0.1:6379> hget htest1 key2 "2"
结构:

4、删除
127.0.0.1:6379[1]> hdel htest1 key1 (integer) 1 127.0.0.1:6379[1]> hget htest1 key1 (nil)
5、是否存在
127.0.0.1:6379[1]> HEXISTS htest1 key1 (integer) 0 #不存在 127.0.0.1:6379[1]> HEXISTS htest1 key2 (integer) 1 #存在
6、展示key的所有的value(第二级的key)
127.0.0.1:6379[1]> hset htest1 key3 3 (integer) 1 127.0.0.1:6379[1]> hset htest1 key4 'a' (integer) 1 127.0.0.1:6379[1]> hkeys htest1 1) "key2" 2) "key3" 3) "key4"
结构:

7、展示key 的所有的最后一级value
127.0.0.1:6379[1]> hvals htest1 1) "2" 2) "3" 3) "a" 127.0.0.1:6379[1]>
8、获取key下面的所有的键和值
127.0.0.1:6379[1]> hgetall htest1 1) "key2" 2) "2" 3) "key3" 4) "3" 5) "key4" 6) "a"
9、进阶实例
127.0.0.1:6379[1]> hmset w3ckey name 'redis tutorial' description 'redis basic commands for caching' likes 20 visitors 23000 OK 127.0.0.1:6379[1]> hgetall w3ckey 1) "name" 2) "redis tutorial" 3) "description" 4) "redis basic commands for caching" 5) "likes" 6) "20" 7) "visitors" 8) "23000" 127.0.0.1:6379[1]>
说明:
设置了redis的一些描述信息(name,description,likes,visitors)到hash表的w3ckeys中。
10、redis hash 命令
|
序号
|
命令及描述
|
|
1
|
HDEL key field2 [field2] 删除一个或多个哈希表字段
|
|
2
|
HEXISTS key field 查看哈希表 key 中,指定的字段是否存在。
|
|
3
|
HGET key field 获取存储在哈希表中指定字段的值/td>
|
|
4
|
HGETALL key 获取在哈希表中指定 key 的所有字段和值
|
|
5
|
HINCRBY key field increment 为哈希表 key 中的指定字段的整数值加上增量 increment 。
|
|
6
|
HINCRBYFLOAT key field increment 为哈希表 key 中的指定字段的浮点数值加上增量 increment 。
|
|
7
|
HKEYS key 获取所有哈希表中的字段
|
|
8
|
HLEN key 获取哈希表中字段的数量
|
|
9
|
HMGET key field1 [field2] 获取所有给定字段的值
|
|
10
|
HMSET key field1 value1 [field2 value2 ] 同时将多个 field-value (域-值)对设置到哈希表 key 中。
|
|
11
|
HSET key field value 将哈希表 key 中的字段 field 的值设为 value 。
|
|
12
|
HSETNX key field value 只有在字段 field 不存在时,设置哈希表字段的值。
|
|
13
|
HVALS key 获取哈希表中所有值
|
|
14
|
HSCAN key cursor [MATCH pattern] [COUNT count] 迭代哈希表中的键值对。
|
三、Redis 数据类型-LIST
1、redis 列表是简单的字符串列表,按照插入顺序排序。
2、可以添加一个元素到列表的头部(左边)或者尾部(右边)。
3、redis list可以做什么:
1)列表可以做什么:index-value pop append
2)redis list同样可以 pop
4、常用基本命令
5、实践
实践1:从左边插入
127.0.0.1:6379[1]> lpush ltest 1 #从左边插入 (integer) 1 127.0.0.1:6379[1]> lpush ltest 1 (integer) 2 #返回的是添加到第几个数 127.0.0.1:6379[1]> lpush ltest 2 (integer) 3 127.0.0.1:6379[1]> llen ltest #看长度 (integer) 3 127.0.0.1:6379[1]> lrange ltest 0 -1 #第一个0,最后一个-1 1) "2" 2) "1" 3) "1"
得到的结构类似:ltest:[2,1,1]
实践2:从右边插入
127.0.0.1:6379[1]> rpush ltest 3 (integer) 4 127.0.0.1:6379[1]> lrange ltest 0 -1 1) "2" 2) "1" 3) "1" 4) "3"
得到的结构类似:ltest:[2,1,1,3]
实践3:删除
127.0.0.1:6379[1]> lpop ltest #从左边删除 "2" 127.0.0.1:6379[1]> lrange ltest 0 -1 1) "1" 2) "1" 3) "3" 127.0.0.1:6379[1]> rpop ltest #从右边删除 "3" 127.0.0.1:6379[1]> lrange ltest 0 -1 1) "1" 2) "1"
6、redis list 可以在实际工作中做什么?--消息队列
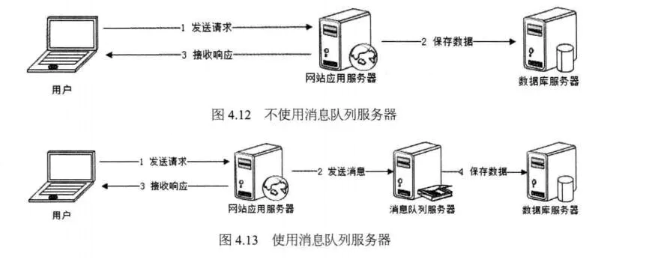
在不使用消息队列服务器的时候,用户的请求数据直接写入数据库,在高并发的情况下数据库压力剧增,使得响应速度变慢。

四、Redis 数据类型-SET(集合)
127.0.0.1:6379[1]> sadd stest redis (integer) 1 127.0.0.1:6379[1]> sadd stest mongdb (integer) 1 127.0.0.1:6379[1]> sadd stest mysql (integer) 1 127.0.0.1:6379[1]> sadd stest mysql (integer) 0 127.0.0.1:6379[1]> smembers stest 1) "mysql" 2) "mongdb" 3) "redis" 127.0.0.1:6379[1]> srem stest redis #删除某个元素 (integer) 1 127.0.0.1:6379[1]> smembers stest 1) "mysql" 2) "mongdb" 127.0.0.1:6379[1]> 127.0.0.1:6379[1]> scard stest #查看有几个元素 (integer) 2 127.0.0.1:6379[1]> sadd stest hqq (integer) 1 127.0.0.1:6379[1]> scard stest (integer) 3 127.0.0.1:6379[1]> smembers stest 1) "hqq" 2) "mysql" 3) "mongdb" 127.0.0.1:6379[1]> 随机删除:(因为是无序的) 127.0.0.1:6379[1]> spop stest "mysql" 127.0.0.1:6379[1]> spop stest "mongdb"
5、实际应用场景
1)可以使用Redis的Set数据类型跟踪一些唯一性数据
五、Redis 数据类型-SORTEDSET
4、实战
127.0.0.1:6379[1]> zadd ztest 1 case1 (integer) 1 127.0.0.1:6379[1]> zadd ztest 2 case3 (integer) 1 127.0.0.1:6379[1]> zadd ztest 3 case2 (integer) 1 127.0.0.1:6379[1]> zrange ztest 0 -1 1) "case1" 2) "case3" 3) "case2" 127.0.0.1:6379[1]>
长度: 127.0.0.1:6379[1]> zcard ztest (integer) 3 删除指定元素: 127.0.0.1:6379[1]> zrem ztest case1 (integer) 1 127.0.0.1:6379[1]> zrange ztest 0 -1 1) "case3" 2) "case2" 127.0.0.1:6379[1]> 返回索引: 127.0.0.1:6379[1]> zrank ztest case2 (integer) 1 127.0.0.1:6379[1]> zrank ztest case3 (integer) 0
5、实际应用场景
六、Redis 的数据库操作
• select [index]
• keys [partten]
• del [key]
• type [key]
• exists [key] #判断是否存在key
• expire [key] time #设置超时时间
• ttl a #查看key还剩多长时间
• flushdb #删除指定db
• flushall #删除所有db

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步