
Spark01
Spark中的一些概念:
Application:类似Hadoop MR,用户编写的Spark应用程序
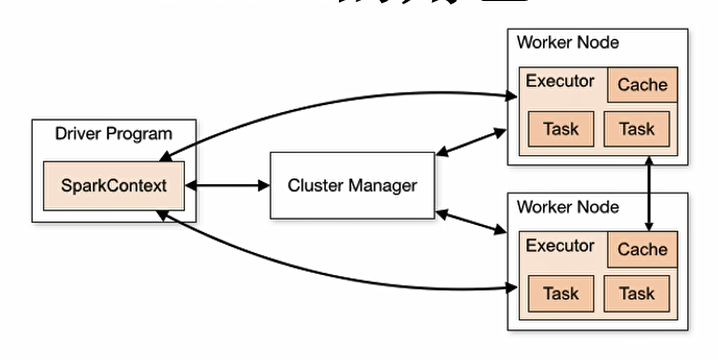
Driver:SparkContext,通过它和Cluster Manager通信,进行资源申请、任务分配、监控等,
Executor:运行某些Task,且负责将磁盘存在内存或磁盘上
Cluster Manager:集群获取资源的外部服务,standalone,Mesos,Yarn等
Worker:集群中任何可以运行Application的节点,在Spark on Yarn中就是指NodeManager
RDD:弹性分布式数据集
Task:具体执行任务,分为ShuffleMap和ResultTask两种,类似于Hadoop中的Map和Reduce
Job:用户提交的作业,1个Job可能有1个或多个Task组成
Stage:Job分成的阶段,1个Job可能划分为多个阶段
Partition:数据分区,一个RDD可以分成多少个分区
NarrowDependency:窄依赖,即子RDD依赖于父RDD中固定的Partition,其分为OneToOneDependency和RangeDependency
ShuffleDependency:宽依赖,即子RDD对父RDD中所有的Partition都有依赖
DAGScheduler:有向无环图,反应RDD间的依赖关系
TaskScheduler:将Taskset分配给Worker
共享变量:两种,可缓存于各个节点的广播变量,支持加法操作实现求和的累加变量
Spark的核心功能:
SparkContext:提交Application前初始化,其包含了网络通信,分布式部署,消息通信,存储能力,计算能力,缓存,测量系统,文件服务,web服务等
存储体系:优先考虑各个节点的内存作为存储,内存不足时考虑磁盘
计算引擎:由SparkContext中的DAGScheduler、RDD以及具体节点上的Executer负责执行的Map Reduce任务组成,在任务提交和执行前,会将Job中的RDD组织成DAG,并对stage划分。
部署模式:多节点
Spark扩展:
Spark SQL:
Spark Streaming:
GraphX:
MLlib:
Spark集群:Cluster Manager(资源分配),Worker(工作节点),Executor(执行任务的进程),Driver App(客户端驱动程序)
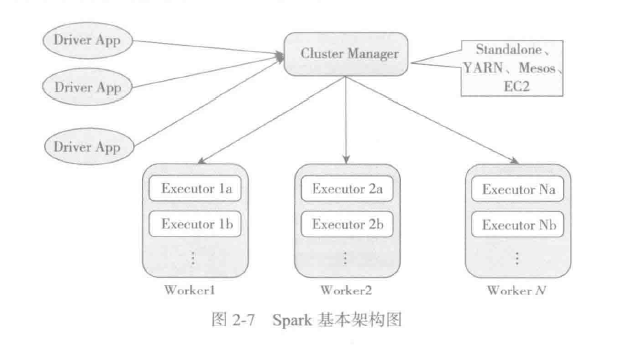
Master节点--分配Applications到Worker节点以维护,Driver,Application的状态:
Spark四种运行模式:
![]()
其中,
单机
spark-shell --master local[4]
单机集群
spark-shell --master local-cluster[2, 3, 1024] x代表要生成的executor数,y和z分别代表每个executor所拥有的core和memory数
standalone
spark-shell --master spark://wl1:7077 --deploy-mode client
①Master进程做为cluster manager,用来对应用程序申请的资源进行管理
②SparkSubmit 做为Client端和运行driver程序
③CoarseGrainedExecutorBackend 用来并发执行应用程序
spark-submit --master spark://wl1:6066 --deploy-mode cluster
①客户端的SparkSubmit进程会在应用程序提交给集群之后就退出
②Master会在集群中选择一个Worker进程生成一个子进程DriverWrapper来启动driver程序
③而该DriverWrapper 进程会占用Worker进程的一个core,所以同样的资源下配置下,会比第3种运行模式,少用1个core来参与计算
④应用程序的结果,会在执行driver程序的节点的stdout中输出,而不是打印在屏幕上
# Run application locally on 8 cores ./bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master local[8] \ /path/to/examples.jar \ 100 # Run on a Spark standalone cluster in client deploy mode ./bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master spark://207.184.161.138:7077 \ --executor-memory 20G \ --total-executor-cores 100 \ /path/to/examples.jar \ 1000 # Run on a Spark standalone cluster in cluster deploy mode with supervise ./bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master spark://207.184.161.138:7077 \ --deploy-mode cluster \ --supervise \ --executor-memory 20G \ --total-executor-cores 100 \ /path/to/examples.jar \ 1000 # Run on a YARN cluster export HADOOP_CONF_DIR=XXX ./bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master yarn \ --deploy-mode cluster \ # can be client for client mode --executor-memory 20G \ --num-executors 50 \ /path/to/examples.jar \ 1000 # Run a Python application on a Spark standalone cluster ./bin/spark-submit \ --master spark://207.184.161.138:7077 \ examples/src/main/python/pi.py \ 1000 # Run on a Mesos cluster in cluster deploy mode with supervise ./bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master mesos://207.184.161.138:7077 \ --deploy-mode cluster \ --supervise \ --executor-memory 20G \ --total-executor-cores 100 \ http://path/to/examples.jar \ 1000

