浅析正则表达式 — 原理篇
其实这篇文章很久之前就应该发出来,由于种种原因没有发出来,如果这篇文章中有错误,还请大家指出,小弟并改正之,没有学不会的东西,只有不想学的东西,只要功夫深,铁杵磨成针,我的至理名言:吾生也有涯而知也无涯,以有涯随无涯,殆矣。我们只要坚持将其看完,相信大家的正则表达式会有一个提升空间!本文属于.NET正则表达式里面的内容,由于不同语言正则表达式有所不同。
首先先讲解下正则表达式的基础知识:
1.字符串的组成
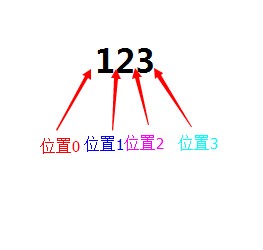
对于字符串”123“而言,包括三个字符四个位置。如下图所示:
2.占有字符和零宽度
正则表达式匹配过程中,如果子表达式匹配到东西,而并非是一个位置,并最终保存到匹配的结果当中。这样的就称为占有字符,而只匹配一个位置,或者是匹配的内容并不保存到匹配结果中,这种就称作零宽度,后续会讲到的零宽度断言等。占有字符是互斥的,零宽度是非互斥的。也就是一个字符,同一时间只能由一个子表达式匹配,而一个位置,却可以同时由多个零宽度的子表达式匹配。
3.控制权和传动
正则表达式由左到右依次进行匹配,通常情况下是由一个表达式取得控制权,从字符串的的某个位置进行匹配,一个子表达式开始尝试匹配的位置,是从前一子表达匹配成功的结束位置开始的(例如:(表达式一)(表达式二)意思就是表达式一匹配完成后才能匹配表达式二,而匹配表达式二的位置是从表达式一的位置匹配结束后的位置开始)。如果表达式一是零宽度,那表达式一匹配完成后,表达式二匹配的位置还是原来表达式以匹配的位置。也就是说它匹配开始和结束的位置是同一个。
举一个简单的例子进行说明:正则表达式:123
源数据:123
讲解:首先正则表达式是从最左侧开始进行匹配,也就是位置0处进行匹配,首先得到控制权的是正则表达式中的“1”,而不是源数据中的“1”,匹配源数据中的“1”,匹配成功,将源数据的“1”进行保存到匹配的结果当中,这就表明它占有了一个字符,接下来就将控制权传给正则表达式中的“2”,匹配的位置变成了位置1,匹配源数据中的“2”,匹配成功,将控制权又传动给了正则表达式的“3”,这时候匹配的位置变成了位置2,这时候就会将源数据中的“3”进行匹配。又有正则表达式“3”进行传动控制权,发现已经到了正则表达式的末尾,正则表达式结束。
一、元字符
| 限定符 | 描述 | 模式 |
| . |
匹配出换行符以外的任意字符 |
\d*\.\d |
|
\w |
匹配字母数字或下划线或者汉字或者下划线 |
"be+" |
| \s |
匹配任意空白符 |
"rai?n" |
| \d |
匹配数字 |
",\d{3}" |
| \b |
匹配单词开始或结束,它只是匹配一个位置 |
"\d{2,}" |
|
^ |
匹配字符串开始 |
"\d{3,5}" |
|
$ |
匹配字符串结束 |
"\d{3,5}" |
二、转义字符
如果你想要得到元字符本身的话需要使用“\”来取消这些元字符的特殊意义
三、字符类
首先字符类使用“[]”包起来的,例如以下这个例子:(大小写要区分)
①[aeiou]则表示匹配任意一个英文元音字母(这个仅仅是匹配一个,也就是说你如果匹配了a这个整个正则表达式就已经结束了,这里面的逻辑表示的是“或”的意思),再看这个例子[.!?]表示匹配.或者?或者!
②[a-zA-Z0-9]这个正则表达式表示的是匹配a到z的任意一个小写字母,或者是A到Z的任意一个字母,或者是数字0到9任意一个.
四.重复(MSDN上称作是限定符)
|
代码/语法 |
说明 |
|
* |
重复0次或多次 |
|
+ |
重复一次或多次 |
|
? |
重复零次或1次 |
|
{n} |
重复n次 |
|
{n,} |
重复至少n次 |
|
{n,m} |
重复至少n次,但不多于m次 |
五.分支条件
其实正则表达式中的分支条件,就指的是有几种规则:用“|”把不同的规则分开
来看下例子:
①0\d{2}-\d{8}|0\d{3}-\d{7}:匹配两种以连字号分隔的电话号码;一种是三位区号8位本地号(例如:010-12345678),另外一种规则则是4位区号7位本地号(例 如:0315-8834524)
②\d{5}-\d{4}|\d{5}:需要注意的是使用分支条件是一定要注意分支条件的顺序,如果改成\d{5}|\d{5}-\d{4}这个样子的话,那么只会匹配五位数字而不会匹配后面的四位数字(例如:我们利用第二个匹配12345-1234,它只会匹配12345,原因是:正则表达式是从左到右依次匹配,如果满足了某个分支的话它就不会再管其他分支了)

六.分组
你可以使用小括号()来指定字表达式
①(\d{1,3}){3}\d{3}:这个正则表达式的意思就是把我们分组的小括号里面的东西重复三次,也就是说我们至少匹配3个最多匹配9个数字,后面再加上三个数字

我们可以看图,最后一个是1234567891 123也就是说前面是十个数字按照我们的常理来分析的话就应该匹配应该最多的是9个所以匹配之后的数到2就匹配成功了。
OK我们讲到分组不知道你们对上面这幅图有没有什么想法?对,没错就是为啥还有0,1之分呢?想知道答案跟我继续看下去,保证你有意外收获哦!
也许大家会问为什么这里的写的1里面匹配的是这些数字,我们稍后我们会为你解析这是为什么会是这些数字!
七.反义字符
|
代码/语法 |
说明 |
|
\W |
匹配任意一个不是字母或数字下划线或汉字的字符 |
|
\S |
匹配任意一个不是空白符的字符 |
|
\D |
匹配不是数字的字符 |
|
\B |
匹配不是单词开头或者结尾的位置 |
|
[^X] |
匹配除了X以外的任意字符 |
|
[^aeiou] |
匹配除了aeiou这几个字母以外的任意字符 |
八.反向引用
使用小括号指定一个子表达式后,匹配这个子表达式的文本(也就是此分组捕获的内容)可以在表达式或其它程序中作进一步的处理。默认情况下,每个分组会自动拥有一个组号,规则是:从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为2,以此类推。但是其实分组号不是这么简单:
•分组0对应整个正则表达式
•实际上组号分配过程是要从左向右扫描两遍的:第一遍只给未命名组分配,第二遍只给命名组分配--因此所有命名组的组号都大于未命名的组号
•你可以使用(?:exp)这样的语法来剥夺一个分组对组号分配的参与权.
通过上面三条讲述我们可以清楚地知道分组的方式是怎样的,其实意思就是首先我们先对没有为组进行命名的组进行分配组号(从左到右依次次分配),然后再对分配组号的组进行分配组号(使用(?<组名>)方式显示分配组名称),如果你想剥夺某一个组的组号可以采用(?:exp)这种方式进行剥夺,也就是不给他分配组号,可以理解为跳过此组。看一下例子:

正则表达式:(?<work>3)(1)(2)(?<SmallDing>565)
匹配文本:312565
匹配结果表明首先0号组的是匹配的整个表达式,匹配1号组名的则是1,匹配2号组的是2,匹配3号组的就是命名为work组名的3,匹配4号组的则是匹配命名为SmallDing组名的565,显然可以看到分配组号就是按照以上的规则来分配。
说到了反向引用我们来看一下反向引用是什么概念,我们前面已经详细讲解了组号的分配,那么反向引用则用于重复搜索前面某个分组匹配的文本,例如\1代表分组1匹配的文本
请看下面的例子:
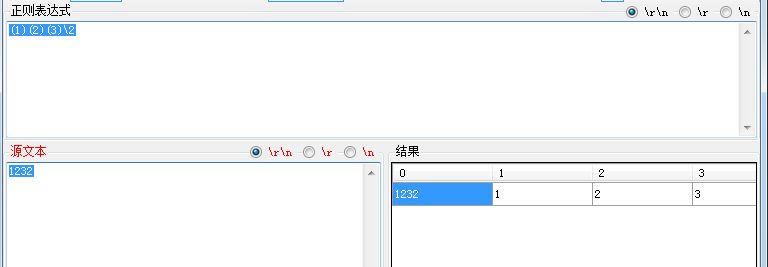
正则表达式:(1)(2)(3)\2则表示匹配123且在此匹配组号为2的内容也就是再次匹配2
匹配文本:1232
匹配结果如下图所示:
而至于想知道怎样取消分组号那就跟着我的脚步走,来看看下面的内容吧!
正则表达式:(?<work>333)(?<smallDing>222)(?:\d{3})该正则表达式代表的是显示为匹配333的组分配组名为work,显示为匹配222结果的组分配组名为222,但是如果匹配3位数字这个组已经取消了组号,所以该组号是没有的,也就是整个正则表达式是第一个组号为0,首先将所有未命名的组进行分配组号,而只有一个(?:\d{3})这个没有分配组名,但是它却将组号进行取消了,所以组号不会给它分配。
源文本为:333222123
匹配结果为:如下图所示:

那现在我们就来讲一下零宽断言和负零宽断言
常见的几种分组方法
|
分类 |
代表/语法 |
说明 |
|
捕获
|
(exp) |
匹配exp,并捕获文本到自动命名的组里 |
|
(?<name>exp) |
匹配exp,并捕获文本到名称为name的组里,也可以写成(?’name’exp) |
|
|
(?:exp) |
匹配exp,不捕获匹配文本,也不给分组分配组号 |
|
|
断言
|
(?=exp) |
匹配exp前面位置,但是不匹配exp |
|
(?<exp) |
匹配exp后面位置,但是不匹配exp |
|
|
(?!exp) |
匹配后面的不是exp的位置,但是不匹配exp |
|
|
(?<!exp) |
匹配前面不是exp的位置,但是不匹配exp |
|
|
注释 |
(?#comment) |
注释 |
零宽度断言
1.(?=exp):也叫零宽度正预测先行断言,它匹配自身出现的位置后面能匹配表达式exp
例如:\b\w+(?=ing\b)则这个正则表达式就是匹配一ing结尾的单词,但是不包含ing,这个零宽度正预测先行断言可以这样理解,我们就以上面的正则表达式作为例来进行讲解,首先我们肯定是匹配源文本为doing它会先匹配d的时候它会瞻仰一下后面跟的是不是ing,如果不是就会继续往下走,匹配到第二个字符o它会预测(或瞻仰)下后面是不是ing如果是整个表达式就结束了,并且不匹配ing。而这个可以总结一句话就是匹配exp前面的东西
2.(?<=exp):也叫零宽度正回顾断言,它匹配自身出现位置的前面匹配表达式exp,这句话听着很绕口,其实零宽度正回顾断言中解释说是自身出现位置这个自身出现位置是表示它匹配的文本,就比如说(?<=Ding)\d{3}这个正则表达式,这里的自身出现的位置仅仅是从开始匹配文本的时候也就是\d{3}也就是主动权在这个\d{3}的时候才是自身匹配的位置。举例说明源文本,比如匹配Din123,按照我们的常理理解的是数字123是自身匹配的位置,但是前面不是Ding所以匹配不成功,我们可以讲这个表达式理解为就是以exp为开始的正则表达式但是不包含exp,意思就是匹配exp后面的东西。
负向零宽断言:(可以和上面的进行对比来学哦!这个表达式的是否定的)
1.(?!exp):也叫零宽度负预测先行断言,断言此位置的后面跟的不能匹配表达式exp,
例如:\d{3}(?!123):正则表达式的含义表达了前面匹配的是三个数字,匹配的位置就是当前匹配的这三个数字后面跟的不能是123。
2.(?<!exp):零宽度负回顾断言,断言此位置前面跟的不是exp的位置。
九.平衡组
接下来我来讲一下平衡租的原理,在上面我们做下了铺垫,也就是说我们在第六节的时候提出来了一系列问题,是不是感觉一头雾水,没关系的,到了这一节终于守得云开见月明了,听过本章节的学习我相信你们会对上面的问题进行一个详细合理的回答!OK,Come On Baby!懂你们迫不及待心情,一定会说你咋这多废话呢,好,闲话少说,继续....
说到平衡组有些人就会想到分组,没错他们之间是有联系的,也就是我们前面所讲的分配组号的问题,那下面呢我们先引出语法,详细见下表
|
语法 |
说明 |
|
(?’group’) |
把捕获的内容命名为group,并压入堆栈 |
|
(?’-group’) |
从堆栈上弹出最后压入堆栈名为group的捕获内容,如果堆栈为空则本组匹配失败 |
|
(?(group)yes|no) |
如果堆栈上存在名为group的捕获内容的话,继续匹配yes部分的表达式,否则匹配no的表达式 |
|
(?!) |
零宽度负先行断言,由于没有后缀表达式,试图匹配总是失败 |
也许大家看到这些语法都不知道是什么概念,也不知道这个平衡组到底用在什么地方合适,接下来我们我们就来说一个场景分析它用在什么位置比较合适,有时我们需要匹配像( 100 * ( 50 + 15 ) )这样的可嵌套的层次性结构,这时简单地使用\(.+\)则只会匹配到最左边的左括号和最右边的右括号之间的内容(这里我们讨论的是贪婪模式,懒惰模式也有下面的问题)。假如原来的字符串里的左括号和右括号出现的次数不相等,比如( 5 / ( 3 + 2 ) ) ),那我们的匹配结果里两者的个数也不会相等。有没有办法在这样的字符串里匹配到最长的,配对的括号之间的内容呢?为了避免(和\(把你的大脑彻底搞糊涂,我们还是用尖括号代替圆括号吧。现在我们的问题变成了如何把xx <aa <bbb> <bbb> aa> yy这样的字符串里,最长的配对的尖括号内的内容捕获出来?
接下来我们对这些语法进行分析,怎么样一个平衡法,大家都见过第一个语法,语法的内容讲解的就是为一个组分配组名,这里我们为什么还强调一下分配组名的问题么?前面不是提到过这些问题了么!那现在让我们解析一下平衡法以及用这些语法去构建一个平衡。
我们先以一个例子开始,正则表达式:(?'Group'123)(?'Group'456)看这个正则表达式,你会发现一些问题,恩?怎么给两个组分配了一个组名,这样返回的Group组名获取的到底是个什么东东呢?大家来猜一下(匹配文本:123456)会是个什么结果?
先看一下测试结果:
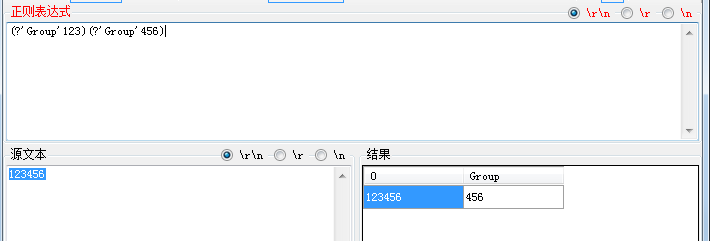
我们可以看到0组当人不让的是整个表达式的,而Group组里面获取的是456,而不是123,这是为什么呢?那么我们就来分析一下他的原理,一张图搞懂原理

OK,我们来讲一下组其实内部是一个堆栈,也就是我们分别往组名为Group的堆栈中放入了两个内容,第一个压入栈的是123,而第二压入栈的是456,Group组获取的文本是堆栈的top,也就是栈顶的数据,所以Group获取的数据是456,而不是123,那么有些人说了我不想要456,我就想要123怎么实现?这样也好办啊!我们就弹出栈顶数据不就行了么!
看下面的实例:(?'Group'123)(?'Group'456)(?’-Group’)这里的表达式(?’-Group’)就是压出堆栈栈顶的数据也就是如下图所示的:

那么现在栈顶的数据就是123了,那么我们就来看一下匹配的结果是不是我们想的这样:

那么我们就可以想到分组名的是这样没有分组名的组也是这样的匹配原理那么我们回到第六章就可以将答案找出来,为什么这个组里的数据会是这个了!剩下还有(?(group)yes|no)深入讲解下这个表达式是什么意思,我们前面已经讲到了分组是一个堆栈,可以压入和弹出,但是再弹出的时候我们不知道它有没有弹完用什么办法来可以检测它是不是已经到了栈底了呢?那么用这个正则表达式就可以检测到!它说的意思就是如果我们已经将数据全部都弹出去了就会执行一个表达式在No的位置,“|”表示分割两种不同情况,如果还存咱数据就说明还没有到栈底,就会执行yes的表达式。那么我们就开始举例说明:正则表达式:(?’group’123)(?’group’456)(?’-group’)(?(group)1|2):这个表达式含义就是如果堆栈中还有数据就匹配1,否则就匹配2,看下面测试结果表明堆栈中还有数据。

十、贪婪与非贪婪
首先先说一下关于贪婪匹配和非贪婪匹配的一些基本概念,贪婪与非贪婪模式影响的是被量词修饰的子表达式的匹配行为,贪婪模式在整个表达式匹配成功的前提下,尽可能多的匹配,而非贪婪模式在整个表达式匹配成功的前提下,尽可能少的匹配。
下面是一些限定符(限定符指定在输入字符串中必须存在上一个元素(可以是字符、组或字符类)的多少个实例才能出现匹配项)
贪婪匹配的限定符如下表所示:
| 限定符 | 描述 | 模式 | 匹配 |
| * | 匹配上一个元素零次或多次 | \d*\.\d | ".0","19.9"和"219.9" |
| + | 匹配上一个元素一次或多次 | "be+" | "been"和"bee","bent"和"be" |
| ? | 匹配前面的元素零次或一次 | "rai?n" | "ran"和"rain" |
| {n} | 匹配上一个元素恰好n次 | ",\d{3}" | "1.043.6"中的.043 |
| {n,} | 匹配上一个元素至少n次 | "\d{2,}" | "166","29"和"1930" |
| {n,m} | 匹配上一个元素至少n次,但不多于m次 | "\d{3,5}" | "166","16546","132654"中的13265 |
非贪婪是在贪婪限定符后面多加一个“?”,如下表所示:
| 限定符 | 描述 | 模式 | 匹配 |
| *? | 匹配上一个元素零次或多次,但次数尽可能少 | \d*?\.\d | ".0","19.9"和"219.9" |
| +? | 匹配上一个元素一次或多次,但次数尽可能少 | "be+?" | "been中的"be",bent"中的"be" |
| ?? | 匹配上一个元素零次或一次,但次数尽可能少 | "rai??n" | "ran"和"rain" |
| {n}? | 匹配前导元素恰好 n 次 | ",\d{3}?" | "1.043.6"中的.043 |
| {n,}? | 匹配上一个元素至少 n 次,但次数尽可能少 | "\d{2,}?" | "166","29"和"1930" |
| {n,m}? | 匹配上一个元素的次数介于 n 和 m 之间,但次数尽可能少 | "\d{3,5}?" | "166","16546","132654"中的"132","654" |
十一、贪婪匹配和非贪婪匹配原理
这是最后一章节,也是最难理解的一章节了,希望大家跟进脚步学习下!其实这节贪婪匹配与懒惰匹配应该放在重复后面讲,因为这个和重复有关系,那么下面详细介绍什么是贪婪匹配什么是非贪婪匹配,贪婪与非贪婪模式影响的是被量词修饰的子表达式的匹配行为,贪婪模式在整个表达式匹配成功的前提下,尽可能多的匹配,而非贪婪模式在整个表达式匹配成功的前提下,尽可能少的匹配。非贪婪模式只被部分NFA引擎所支持。
从原理角度分析一下贪婪匹配与懒惰匹配,接下来我们将以一个例子分析
匹配两个正则表达式,正则表达式一为:.*
正则表达式二是:.*?
源文本是:“Regex”
(1).贪婪
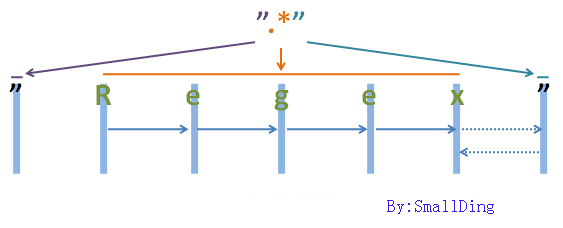
注:为了能够看清晰匹配过程,上面的空隙留得较大,实际源字符串为“"Regex"”,下同。
来看一下匹配过程。首先将控制权交给“"”,由它来匹配第一个字符"匹配成功,将控制权转交给“.*”,这时候控制权掌握在了“.*”的手上,由于“*”是优先词量,在可匹配与不可匹配的情况下,优先尝试匹配,他就会尝试匹配第一字符R,匹配成功就会继续往下匹配,匹配第二字符e,匹配成功,继续向右匹配,直到匹配到结尾的“"”,匹配成功,再向后匹配时发现已经到结尾了,“.*”结束匹配将控制权转交给""","""发现已经到了源字符串的结尾,看有没有可供回溯的状态,将控制权给了“.*”,“.*”还回一个字符“x”,然后将控制权转交给“"”,来匹配后面的字符“"”,匹配成功正则表达式结束。这句表达式只进行了一次回溯。
(2).懒惰
源字符串:"Regex"
正则表达式:".*?"

看一下非贪婪模式的匹配过程。首先由第一个“"”取得控制权,匹配位置0位的“"”,匹配成功,控制权交给“.*?”。“.*?”取得控制权后,由于“*?”是忽略优先量词,在可匹配可不匹配的情况下,优先尝试不匹配,由于“*”等价于“{0,}”,所以在忽略优先的情况下,可以不匹配任何内容。从位置1处尝试忽略匹配,也就是不匹配任何内容,将控制权交给正则表达式最后的“””。
“"”取得控制权后,从位置1处尝试匹配,由“"”匹配位置1处的“R”,匹配失败,向前查找可供回溯的状态,控制权交给“.*?”,由“.*?”吃进一个字符,匹配位置1处的“R”,再把控制权交给正则表达式最后的“"”。
“"”取得控制权后,从位置2处尝试匹配,由“"”匹配位置1处的“e”,匹配失败,向前查找可供回溯的状态,重复以上过程,直到由“.*?”匹配到“x”为止,再把控制权交给正则表达式最后的“"”。
“"”取得控制权后,从位置6处尝试匹配,由“"”匹配字符串最后的“"”,匹配成功。
此时整个正则表达式匹配成功,其中“.*?”匹配的内容为“Regex”,匹配过程中进行了五次回溯。
写的很认真但是难免会有错误,希望大家多多包涵,多多指出,时刻保持学习的身段,正所谓三人行必有我师焉。人外有人天外有天,只有保持不断学习的精神,才能达到我们的目标。我会将其更新并且改正。
这篇文章为了方便大家传阅将其写成word文档,可以进行下载,下载地址如下:
百度网盘:http://pan.baidu.com/s/1kTKB3Zx 提取密码:l6q4
其中有我在公司的技术分享视频,由于是第一次录制可能有些细节没有讲得很清楚。也在上面百度网盘中。
参考文章:
图片是从下面文章中找到的:
http://www.jb51.net/article/31491.htm
http://www.cnblogs.com/deerchao/archive/2006/08/24/zhengzhe30fengzhongjiaocheng.html#mission
测试工具也在里面:
http://deerchao.net/tutorials/regex/common.htm
谢谢各位的提的意见,从你们的意见中将这篇文章尽自己最大努力完善,这篇文章写得不完美,需要大家的努力。
接下篇对令宽度进行详细讲解:
如果有了基础之后可以进行下面的文章的学习:
转载请注明出处,版权归本人所属!
转载自:http://www.cnblogs.com/dwlsxj/p/3532458.html#undefined

 浙公网安备 33010602011771号
浙公网安备 33010602011771号