2. 基本数据结构-列表
一、列表定义
List(列表)是python中使用最频繁的数据类型。列表可以完成大多数的数据结构实现。列表中元素的类型可以不同。它支持数字/字符串/列表(嵌套)。列表是写在[]之间的,用逗号分隔开的元素列表,和字符串一样。列表同样可以被索引和切片,列表被切片后返回一个包含所需元素的新列表。而且列表是有序的(按照你保存的顺序),有索引,可切片方便取值。python可存放32/64位,列表是可变数据类型,不可hash。
二、列表切片
1. 示意图
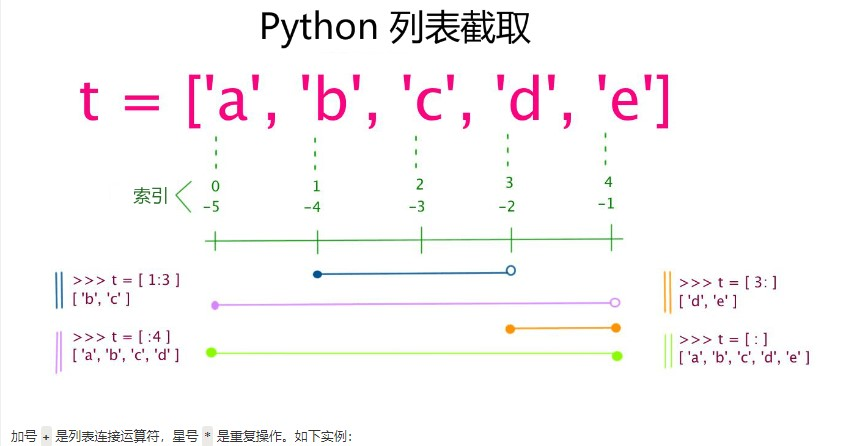
2. 列表切片操作
list = [ 'abcd', 786 , 2.23, 'run', 70.2 ]
1. 切片切得是什么类型,切后的数据就是什么类型
tinylist = [123, 'runoob']
print (list) # 输出完整列表 ['abcd', 786, 2.23, 'run', 70.2]
print (list[0]) # 输出列表第一个元素 abcd
print (list[1:3]) # 从第二个开始输出到第三个元素 [786, 2.23]
print (list[2:]) # 输出从第三个元素开始的所有元素 [2.23, 'run', 70.2]
print (tinylist * 2) # 输出两次列表 [123, 'run', 123, 'run']
print (list + tinylist) # 连接列表 ['abcd', 786, 2.23, 'run', 70.2, 123, 'run']
print(list1[-5:]) # 从第一元素取至最后一个,-5就是第一个元素['abcd', 786, 2.23, 'run', 70.2]
print(list[-5::2]) #增加步长,隔一个取一个 ['abcd', 2.23, 70.2]
print(list[-1::-2])# 倒着取值 [70.2, 2.23, 'abcd']
print(list[-1: ]) [70.2]
2.li = [1, 2, 3, 4, 5, 6, 7, 8, 9]
li[2:5] = [11, 22, 33, 44, 55]
print(li)
结果:[1, 2, 11, 22, 33, 44, 55, 6, 7, 8, 9]
三、列表操作
1. 添加
注意, list和str是不一样的. lst可以发生改变. 所以直接就在原来的对象上进行了操作
(1) append() - 尾部追加
lst = ["麻花藤", "林林俊杰", "周润发", "周芷若"]
print(lst)
lst.append("wusir")
print(lst)
lst = []
while True:
content = input("请输入你要录入的员工信息, 输入Q退出:")
if content.upper() == 'Q':
break
lst.append(content)
print(lst)
备注:
append()是浅拷贝
>>>alist = []
>>> num = [2]
>>> alist.append( num )
>>> id( num ) == id( alist[0] )
True
如果使用 num[0]=3,改变 num 后,alist[0] 也随之改变。
如不希望,需要使用 alist.append( copy.deepcopy( num ) )
(2) insert() - 插入
lst = ["麻花藤", "张德忠", "孔德福"]
lst.insert(1, "刘德华") # 在1的位置插入刘德华. 原来的元素向后移动一位
print(lst)
(3) extend() - 列表扩展
用于在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)
1. 语法
list.extend(seq)
- seq:元素列表,可以是列表/元组/集合/字典,若为字典,则仅会将键(key)作为元素依次添加至原列表的末尾
2. 案例
list1 = ['Google', 'Runoob', 'Taobao']
list2=list(range(5)) # 创建 0-4 的列表
list1.extend(list2) # 扩展列表
print ("扩展后的列表:", list1)
扩展后的列表: ['Google', 'Runoob', 'Taobao', 0, 1, 2, 3, 4]
3. 其他案例
# 语言列表
language = ['French', 'English', 'German']
# 元组
language_tuple = ('Spanish', 'Portuguese')
# 集合
language_set = {'Chinese', 'Japanese'}
# 添加元组元素到列表末尾
language.extend(language_tuple)
print('新列表: ', language)
新列表: ['French', 'English', 'German', 'Spanish', 'Portuguese']
# 添加集合元素到列表末尾
language.extend(language_set)
print('新列表: ', language)
新列表: ['French', 'English', 'German', 'Spanish', 'Portuguese', 'Japanese', 'Chinese']
2. 删除
(1) pop()
用于移除列表中的一个元素(默认最后一个元素),并且返回该元素的值;list.pop([index=-1])
lst = ["麻花藤", "王剑林林", "李李嘉诚", "王富贵"]
print(lst)
# 默认删除最后一个
deleted = lst.pop()
print("被删除的", deleted)
print(lst)
结果:
['麻花藤', '王剑林林', '李李嘉诚', '王富贵']
被删除的 王富贵
['麻花藤', '王剑林林', '李李嘉诚']
# 删除2号元素
el = lst.pop(2)
print(el)
print(lst)
(2) remove()
用于移除列表中某个值的第一个匹配项
# 删除指定元素
lst.remove("麻花藤")
print(lst)
# 删除不存在的元素会报错
lst.remove("哈哈")
print(lst)
Error: ValueError: list.remove(x): x not in list
(3) clear()
- 清空list
(4) 切片删除
del lst[1:3]
print(lst)
3. 修改
lst = ["太白", "太黑", "五色", "银王", "日天"]
lst[1] = "太污" # 把1号元素修改成太污
print(lst)
lst[1:4:3] = ["麻花藤", "哇靠"] # 切片修改也OK. 如果步长不是1, 要注意元素的个数
print(lst)
lst[1:4] = ["李李嘉诚个龟儿子"] # 如果切片没有步长或者步长是1. 则不用关心个数
print(lst)
4. 查询
1. index()
2.for el in lst:
print(el)
四、其他操作
1. count()
list.count(obj) #语法
aList = [123, 'Google', 'Runoob', 'Taobao', 123];
print ("123 元素个数 : ", aList.count(123))
print ("Runoob 元素个数 : ", aList.count('Runoob'))
/结果:
123 元素个数 : 2
Runoob 元素个数 : 1
2. len()
len(len) # 方法,返回列表个数
list1 = ['Google', 'Runoob', 'Taobao']
print (len(list1))
list2=list(range(5)) # 创建一个 0-4 的列表
print (len(list2))
/结果:
3
5
3. list()
aTuple = (123, 'Google', 'Runoob', 'Taobao')
list1 = list(aTuple)
print ("列表元素 : ", list1)
str="Hello World"
list2=list(str)
print ("列表元素 : ", list2)
/结果:
列表元素 : [123, 'Google', 'Runoob', 'Taobao']
列表元素 : ['H', 'e', 'l', 'l', 'o', ' ', 'W', 'o', 'r', 'l', 'd']
4. reverse()
函数用于翻向列表中元素
list1 = ['Google', 'Runoob', 'Taobao', 'Baidu']
list1.reverse()
print ("列表反转后: ", list1)
/结果:
列表反转后: ['Baidu', 'Taobao', 'Runoob', 'Google']
5. sort()
list.sort(cmp=None, key=None, reverse=False)#该方法没有返回值,但是会对列表的对象进行排序
cmp -- 可选参数, 如果指定了该参数会使用该参数的方法进行排序。
key -- 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
reverse -- 排序规则,reverse = True 降序, reverse = False 升序(默认)
aList = ['Google', 'Runoob', 'Taobao', 'Facebook']
aList.sort()
print ( "List : ", aList)
/结果:
List : ['Facebook', 'Google', 'Runoob', 'Taobao']
vowels = ['e', 'a', 'u', 'o', 'i']# 降序
vowels.sort(reverse=True)
print ( '降序输出:', vowels )
/结果:
降序输出: ['u', 'o', 'i', 'e', 'a']
列表的嵌套
li = ['李娜', '韩寒', 'aliex', ['妮妮', 23,'北京']]
print(li[1][1]) # 取韩寒中的寒字
li[0] = li[0].capitalize() # 找的lina首字母大写,并将li中的lina替换掉
print(li)
li[1] = li[1].replace('韩', '国') # 将韩寒的韩改成国
print(li)
n = [1, 2, 'jack', 4, 5, 5, 6, 7, 78, 8, 9, 9]
n[3:4] = 'tony alix'
print(n)
[1, 2, 'jack', 't', 'o', 'n', 'y', ' ', 'a', 'l', 'i', 'x', 5, 5, 6, 7, 78, 8, 9, 9]
n[3:4] = ['tony', 'jone']
print(n)
[1, 2, 'jack', 'tony', 'jone', 5, 5, 6, 7, 78, 8, 9, 9]
6. join
将列表转换为字符串
li = ["李嘉诚", "麻花藤", "林海峰", "刘嘉玲"]
s = "_".join(li) # 循环遍历列表,把列表中的每一项用''_''拼接
print(s)
结果:
李嘉诚_麻花藤_林海峰_刘嘉玲
li = "花闺"
s = "_".join(li)
print(s)
结果:
花_闺
7. 列表循环删除
li = ['周芷若', '王兴', '周润发', '马云', '周星星']
li_new = [] # 创建一个新列表存储要删除的元素
for el in li: # 循环li,把姓周的装进li_new
if el.startswith('周'):
li_new.append(el)
for el_new in li_new: # 循环新列表,删除li中的元素
li.remove(el_new)
print(li)
结果:['王兴', '马云']
8. 列表浅拷贝
1. old = [1,[2,3]]
new = old.copy()
2. old = [1,[2,3]]
new = [i for i in old]
3. old = [1,[2,3]]
new = []
for i in old:
new.append(old[i])
4. old = [1,[2,3]]
new = old[:]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号