【原创】Kernel调试追踪技术之 eBPF on ARM64
【原创】Kernel调试追踪技术之 eBPF on ARM64
本文目标:
- 理解eBPF的核心概念和实现方法
- 探索ARM64 Linux上eBPF的使用
1. eBPF是什么?
eBPF是一种不需要修改kernel代码,不需要加载内核模块,就可以扩展内核功能的技术。可用于网络包过滤,kernel行为监控和观测,安全检查等。
1.1 BPF and tcpdump
BPF (Berkeley Packet Filter) 是1992年就有的技术,最初用在unix上,用于网络包过滤。
BPF的实现原理是把包过滤命令翻译成字节码(bytecode),在kernel中转译并执行这些字节码。通过在Kernel各处加入钩子函数,实现网络数据包的捕获的过滤,例如tcpdump就是基于bpf实现的。
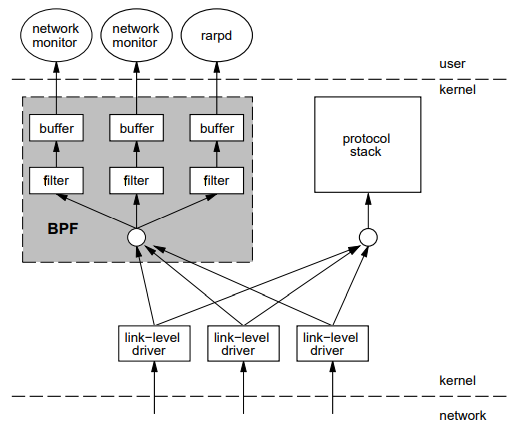
classic BPF Overview http://www.tcpdump.org/papers/bpf-usenix93.pdf
-
tcpdump 的-d参数可以dump出执行的字节码
$ sudo tcpdump -i enp0s10 port 22 -d [sudo] password for yu: (000) ldh [12] (001) jeq #0x86dd jt 2 jf 10 (002) ldb [20] (003) jeq #0x84 jt 6 jf 4 (004) jeq #0x6 jt 6 jf 5 (005) jeq #0x11 jt 6 jf 23 (006) ldh [54] (007) jeq #0x16 jt 22 jf 8 (008) ldh [56] (009) jeq #0x16 jt 22 jf 23 (010) jeq #0x800 jt 11 jf 23 (011) ldb [23] (012) jeq #0x84 jt 15 jf 13 (013) jeq #0x6 jt 15 jf 14 (014) jeq #0x11 jt 15 jf 23 (015) ldh [20] (016) jset #0x1fff jt 23 jf 17 (017) ldxb 4*([14]&0xf) (018) ldh [x + 14] (019) jeq #0x16 jt 22 jf 20 (020) ldh [x + 16] (021) jeq #0x16 jt 22 jf 23 (022) ret #262144 (023) ret #0
1.2 eBPF
2011年左右, Plumgrid公司的Alexei Starovoitov 等人觉得经典BPF(也叫cBPF)有些过时,比如其字节码指令只使用2个32位寄存器,功能和效率都受限,开始对BPF做出大幅修改,新版命名为extended BPF,并且使其可以用于网络(Networking)以外的领域,比如跟踪(Tracing)和安全等,使得BPF向通用化技术演进。
eBPF对经典BPF(cBPF)做了兼容,所以现在说的BPF通指eBPF。
eBPF对cBPF做了如下优化:
- 字节码寄存器从32位变为64位
- 寄存器数从2个增加到10个,可以实现主流处理器的ABI的直接映射
- JIT支持,预先翻译成汇编指令,执行速度大增
- 实现了bpf()系统调用
下图为eBPF的框架结构图:
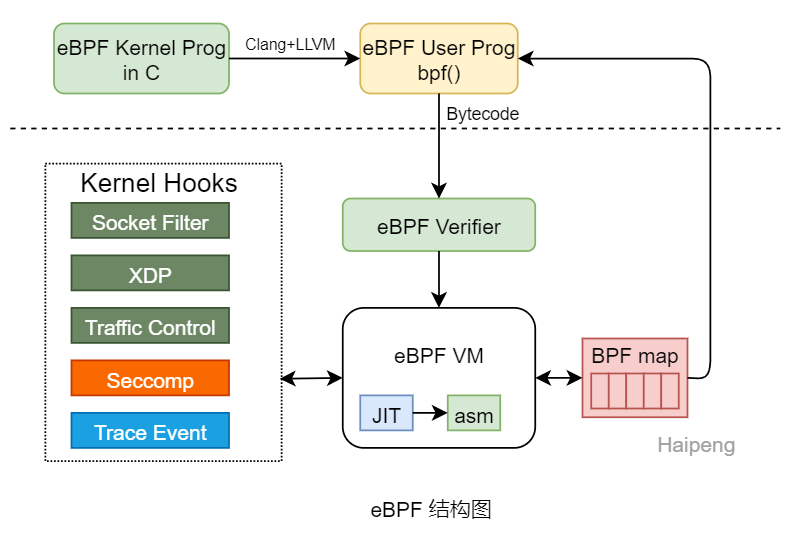
下面对BPF的核心概念做简要介绍。
Verifier
BPF字节码程序传入Kernel后,首先要进行严格的检验,由Verifier(检验器)模块完成。
- 不能包含循环(Direct Acyclic),如果是小循环会被展开
- 检查越界指令
- 检查所有分支指令,并且仿真运行
- 寄存器必须先初始化再使用,
- 不允许指针计算
- 禁止随机内存访问
只有通过verifier验证后的程序才能被运行。
Map
BPF中定义各种map数据结构存放数据,用于kernel和用户层的数据交换,比如传递数据包、Trace 数据等。
include/uapi/linux/bpf.h
98 enum bpf_map_type {
99 BPF_MAP_TYPE_UNSPEC,
100 BPF_MAP_TYPE_HASH, // 哈希
101 BPF_MAP_TYPE_ARRAY, // 数组
102 BPF_MAP_TYPE_PROG_ARRAY, // 程序数组
103 BPF_MAP_TYPE_PERF_EVENT_ARRAY, // PERF EVENT数组
104 BPF_MAP_TYPE_PERCPU_HASH, // PERCPU 哈希
105 BPF_MAP_TYPE_PERCPU_ARRAY, // PERCPU 数组
106 BPF_MAP_TYPE_STACK_TRACE, // 栈
107 BPF_MAP_TYPE_CGROUP_ARRAY, // Cgroup数组
108 BPF_MAP_TYPE_LRU_HASH, // LRU 哈希
109 BPF_MAP_TYPE_LRU_PERCPU_HASH,
110 BPF_MAP_TYPE_LPM_TRIE, // Longest-pre match
111 BPF_MAP_TYPE_ARRAY_OF_MAPS, // map的数组
112 BPF_MAP_TYPE_HASH_OF_MAPS, // map的哈希
113 BPF_MAP_TYPE_DEVMAP,
114 BPF_MAP_TYPE_SOCKMAP,
115 };
这些map在编写BPF kernel程序时定义,在BPF user程序中通过bpf() 系统调用读到用户空间。
bpf() syscall
eBPF应用程序通过唯一的系统调用接口与kernel通信。
SYSCALL_DEFINE3(bpf, int, cmd, union bpf_attr __user *, uattr, unsigned int, size)
-
cmd 参数指定执行的操作
enum bpf_cmd { BPF_MAP_CREATE, // 创建一个map BPF_MAP_LOOKUP_ELEM, // 查询一个map 元素 BPF_MAP_UPDATE_ELEM, // 更新一个map 元素 BPF_MAP_DELETE_ELEM, // 删除一个map 元素 BPF_MAP_GET_NEXT_KEY, // 获取下一个map的key值 BPF_PROG_LOAD, // 加载bpf程序 BPF_OBJ_PIN, // pin bpf program和map 组成的对象,防止进程退出后删除 BPF_OBJ_GET, // 获取object BPF_PROG_ATTACH, // attach bpf 程序到cgroup BPF_PROG_DETACH, BPF_PROG_TEST_RUN, // 测试性执行一次 BPF_PROG_GET_NEXT_ID, // 获取下一个prog ID BPF_MAP_GET_NEXT_ID, // 获取下一个map ID BPF_PROG_GET_FD_BY_ID, // 通过ID获取prog的fd BPF_MAP_GET_FD_BY_ID, // 通过ID获取map的fd BPF_OBJ_GET_INFO_BY_FD, // 通过fd获取obj的信息 }; -
uattr 是针对各个CMD传入的参数,比如map信息,program信息等,size是uattr的大小。
JIT (Just-in-time Compilation)
JIT是在运行时把Bytecode翻译成Machine Code(机器码)的技术,JAVA就是通过JIT技术使得性能大幅提升。因为Bytecode是一种虚拟的指令集,不能直接运行在CPU上,如果不支持JIT,bytecode要被通过C语言仿真执行,效率很低。目前Kernel支持的主流处理器架构都支持JIT,比如X86,ARM64, Powerpc。
BPF程序通过verifier后会被通过JIT翻译成ASM,构造成一个函数,注册到struct bpf_prog的bpf_func 接口上,这样bytecode的执行效率和原生代码就几乎没差别了。
Clang 和LLVM
因为BPF使用自身特定的Bytecode,需要把C代码编译成bytecode,LLVM实现了BPF后端支持,所以目前主要使用Clang+LLVM的方法。GCC 需要GCC10版本才支持。
Clang是LLVM的C语言前端,负责把C编译成LLVM的中间语言IR,再由LLVM的bpf后端编译成bytecode。
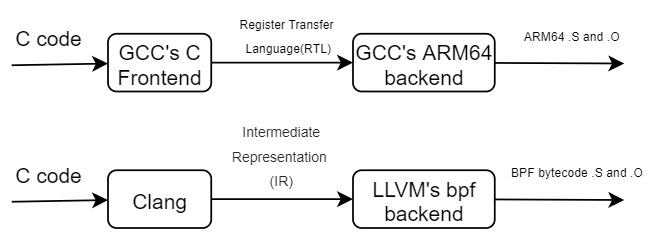
详细比较可参看 https://stackoverflow.com/questions/24836183/understanding-g-vs-clang-vs-llvm
eBPF工具和项目
2014年Alexei去Netflix拜访性能分析的大神Brendan Gregg,介绍了eBPF,Brendan大赞,认为eBPF可以更方便地实现很多性能分析工具,因为类似虚拟机运行,可以对执行代码进行验证(Verify),安全性高,可以方便用于生产系统。Brendan把他之前开发的很多工具用eBPF改写,且扩充了许多工具,促进了eBPF的大发展和普及。
并且写了一本书《BPF Performance Tool - Linux System and Application Observation》。

http://www.brendangregg.com/blog/2019-07-15/bpf-performance-tools-book.html。
为了方便eBPF应用开发,eBPF开发者开发了BCC (BPF Compiler Collection),包含BPF的辅助库和对Python、Lua等前端程序的支持,降低了编程难度。 BCC 放在ioviso (https://github.com/iovisor)项目中,除此之外还有bpftrace、ply等项目。
eBPF被称为目前Linux上新的supper power,因为可以在产品系统中使用,可以基于eBPF在应用层实现许多网络应用程序,例如:
- Cilium & Hubble 基于eBPF的网络管理、监控软件
- Cilium可以算是eBPF的官方项目,由eBPF主要设计者开发,是cilium eBPF的详细设计和使用文档。
- Sysdig 系统行为可视化工具
- 最初由Kernel module实现,后基于eBPF实现
eBPF对于Kernel,就像Javascript对于HTML一样 [BPF-Rethink the Linux kernel]。
1.3 eBPF和Ftrace的区别
eBPF和tracing是不同的技术。
tracing往往会产生大量数据,需要做筛选,甚至编写解析程序实现可视化和统计。
eBPF对内核事件、数据的获取更有针对性,方便编成实现精细控制。
ftrace的优势在于大多kernel原生支持,方便使用;
eBPF优势在于扩展性极强。
2. eBPF的实现
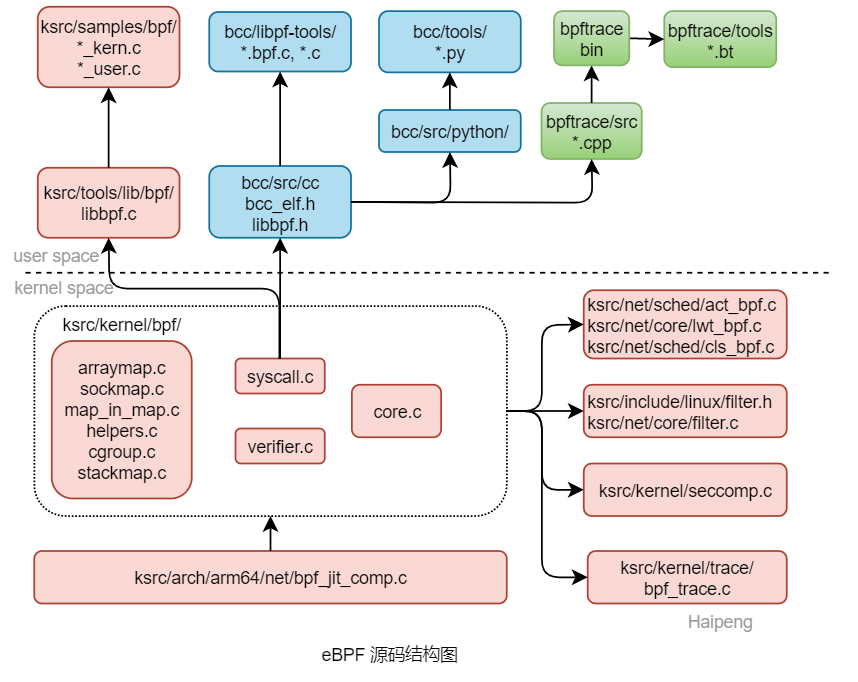
2.1 代码框图
eBPF的相关代码可以分成三个部分
- Kernel代码
- 包括bpf核心实现
- 处理器相关的JIT支持
- 各个子系统对bpf的支持
- Kernel代码树的用户层代码
- 在tools/lib/bpf中的辅助函数库libbpf.c
- 在samples/bpf/中的例子程序和测试程序
- iovisor项目中的BCC、bpftrace、ply等BPF开发框架和工具的代码
- 包括bpf的C库和python、Lua、CC等前端支持,以及应用程序
下图为eBPF源码结构图:
2.2 bpf程序加载
用户通过Clang+LLVM编译好的bpf bytecode 通过bpf() syscall的BPF_PROG_LOAD命令传入kernel。
进入kernel后进行license检查、verify、JIT、创建文件描述符,最后得到一个有符号名的bpf 函数,
# echo 1 > /proc/sys/net/core/bpf_jit_kallsyms
# cat /proc/kallsyms | grep -E "bpf_prog_.+_sys_[enter|exit]"
ffff000000086a84 t bpf_prog_f173133dc38ccf87_sys_enter [bpf]
ffff000000088618 t bpf_prog_c1bd85c092d6e4aa_sys_exit [bpf]
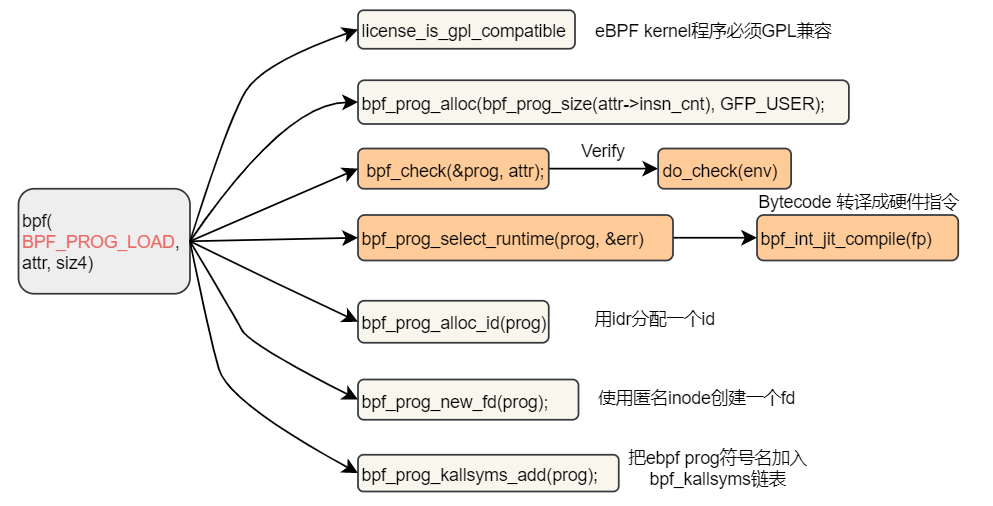
2.3 eBPF core, ARM64 JIT
Bytecode到ARM执行的转换,需要先定义eBPF和ARM寄存器和指令的映射关系,代码如下:
//寄存器映射
41 /* Map BPF registers to A64 registers */
42 static const int bpf2a64[] = {
43 /* return value from in-kernel function, and exit value from eBPF */
44 [BPF_REG_0] = A64_R(7),
45 /* arguments from eBPF program to in-kernel function */
46 [BPF_REG_1] = A64_R(0),
47 [BPF_REG_2] = A64_R(1),
48 [BPF_REG_3] = A64_R(2),
49 [BPF_REG_4] = A64_R(3),
50 [BPF_REG_5] = A64_R(4),
51 /* callee saved registers that in-kernel function will preserve */
52 [BPF_REG_6] = A64_R(19),
53 [BPF_REG_7] = A64_R(20),
54 [BPF_REG_8] = A64_R(21),
55 [BPF_REG_9] = A64_R(22),
56 /* read-only frame pointer to access stack */
57 [BPF_REG_FP] = A64_R(25),
58 /* temporary registers for internal BPF JIT */
59 [TMP_REG_1] = A64_R(10),
60 [TMP_REG_2] = A64_R(11),
61 [TMP_REG_3] = A64_R(12),
62 /* tail_call_cnt */
63 [TCALL_CNT] = A64_R(26),
64 /* temporary register for blinding constants */
65 [BPF_REG_AX] = A64_R(9),
66 };
// 指令映射
320 static int build_insn(const struct bpf_insn *insn, struct jit_ctx *ctx)
321 {
...
346
347 switch (code) {
348 /* dst = src */
349 case BPF_ALU | BPF_MOV | BPF_X:
350 case BPF_ALU64 | BPF_MOV | BPF_X:
351 emit(A64_MOV(is64, dst, src), ctx);
352 break;
353 /* dst = dst OP src */
354 case BPF_ALU | BPF_ADD | BPF_X:
355 case BPF_ALU64 | BPF_ADD | BPF_X:
356 emit(A64_ADD(is64, dst, dst, src), ctx);
357 break;
..
539 case BPF_JMP | BPF_JSGE | BPF_X:
540 case BPF_JMP | BPF_JSLE | BPF_X:
541 emit(A64_CMP(1, dst, src), ctx);
542 emit_cond_jmp:
543 jmp_offset = bpf2a64_offset(i + off, i, ctx);
544 check_imm19(jmp_offset);
545 switch (BPF_OP(code)) {
546 case BPF_JEQ:
547 jmp_cond = A64_COND_EQ;
548 break;
....
下图为Bytecode转换为ARM64指令的函数调用过程:
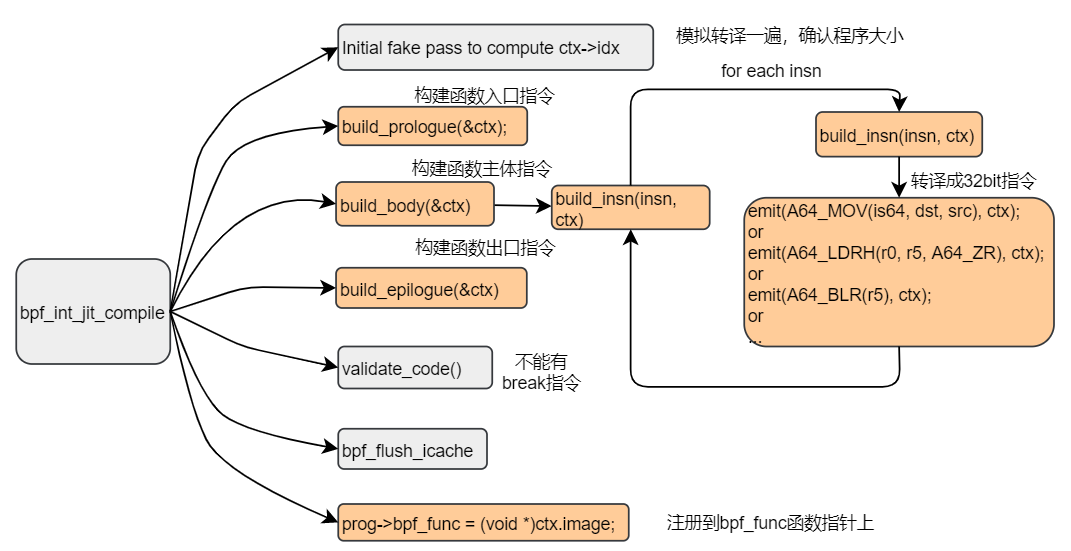
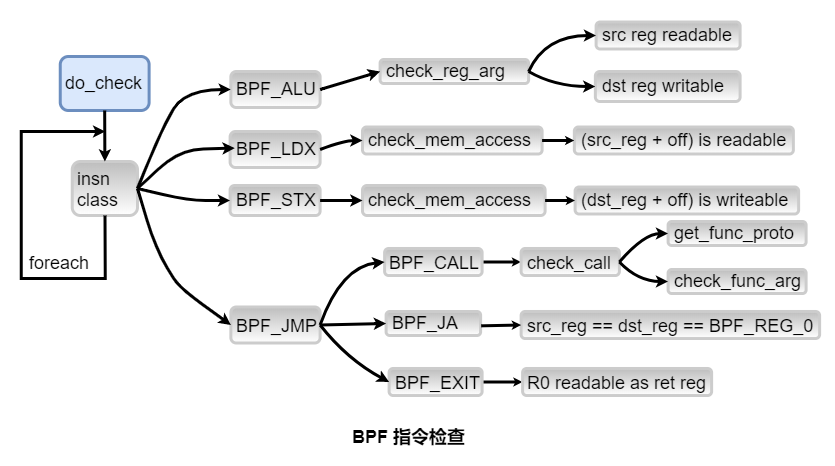
2.4 Verifier
Verifier是一个静态代码分析器,用来分析传入Kernel 的BPF程序。
eBPF程序是从在用户空间传入的,必须进行严格限制,防止其导致kernel 崩溃或性能下降,所以Verifier定义了严格的审查规则。
Verifier对用户是透明的,但是理解Verifier,对于理解eBPF非常有帮助,ksrc/kernel/bpf/verifier.c 开头的一段注释解释了verifier的核心验证规则,要点如下图:

验证主要分成两个阶段。
第一个阶段检查函数的深度和指令数,使用深度优先遍历,并且确保没有循环(DAG:有向无环图),用压栈出栈的方式实现。
第二个阶段检查每条bytecode指令,根据指令的分类(class),检查其操作寄存器的读写属性、内存访问是否越界、BPF_CALL是否符合接口协议等。
下图为指令检查过程:
BCC中runqlen工具的转译实例:
src/iovisor/bcc-master/libbpf-tools/bin $ ./bpftool prog show
...
59: cgroup_skb tag 2a142ef67aaad174 gpl
loaded_at 2020-09-02T08:23:41+0800 uid 0
xlated 296B jited 200B memlock 4096B map_ids 58,59
73: perf_event name do_perf_event tag 168815884b13b0c4 gpl
loaded_at 2020-09-02T09:33:25+0800 uid 0
xlated 360B jited 210B memlock 4096B map_ids 67
$ sudo bcc.runqlen
C code
int do_perf_event()
{
unsigned int len = 0;
pid_t pid = 0;
struct task_struct *task = NULL;
struct cfs_rq_partial *my_q = NULL;
task = (struct task_struct *)bpf_get_current_task();
my_q = (struct cfs_rq_partial *)task->se.cfs_rq;
len = my_q->nr_running;
if (len > 0)
len--;
STORE
return 0;
}
Tranlated Bytecode
$ sudo ./bpftool prog dump xlated tag 168815884b13b0c4
0: (85) call bpf_get_current_task#-59136
1: (b7) r6 = 0
2: (7b) *(u64 *)(r10 -8) = r6
3: (07) r0 += 472
4: (bf) r1 = r10
5: (07) r1 += -8
6: (b7) r2 = 8
7: (bf) r3 = r0
8: (85) call bpf_probe_read#-56224
9: (79) r3 = *(u64 *)(r10 -8)
10: (63) *(u32 *)(r10 -8) = r6
...
40: (07) r3 += -8
41: (b7) r4 = 1
42: (85) call htab_map_update_elem#109984
43: (b7) r0 = 0
**** 44: (95) exit
2.5 BPF_CALL
BPF程序只能调用通过BPF_CALL声明的kernel接口,这样可以保障安全和性能。
这些接口主要是在网络、trace和bpf核心代码中实现的的一些帮助函数。
bpf程序通过这些接口和kernel各个模块进行交互。
Kerne4.14.74中有78个,kernel5.8.0中有170个
# Helper
./kernel/bpf/helpers.c:31: BPF_CALL_2(bpf_map_lookup_elem, struct bpf_map *, map, void *, key)
./kernel/bpf/helpers.c:46: BPF_CALL_4(bpf_map_update_elem, struct bpf_map *, map, void *, key,
./kernel/bpf/helpers.c:64: BPF_CALL_2(bpf_map_delete_elem, struct bpf_map *, map, void *, key)
./kernel/bpf/helpers.c:85: BPF_CALL_0(bpf_get_smp_processor_id)
./kernel/bpf/helpers.c:96: BPF_CALL_0(bpf_get_numa_node_id)
./kernel/bpf/helpers.c:107: BPF_CALL_0(bpf_ktime_get_ns)
./kernel/bpf/helpers.c:119: BPF_CALL_0(bpf_get_current_pid_tgid)
./kernel/bpf/helpers.c:135: BPF_CALL_0(bpf_get_current_uid_gid)
./kernel/bpf/helpers.c:155: BPF_CALL_2(bpf_get_current_comm, char *, buf, u32, size)
./kernel/bpf/core.c:1423: BPF_CALL_0(bpf_user_rnd_u32)
./kernel/bpf/stackmap.c:118:BPF_CALL_3(bpf_get_stackid, struct pt_regs *, regs, struct bpf_map *, map,
./kernel/bpf/sockmap.c:901: BPF_CALL_4(bpf_sock_map_update, struct bpf_sock_ops_kern *, bpf_sock,
# Trace
./kernel/trace/bpf_trace.c:64: BPF_CALL_3(bpf_probe_read, void *, dst, u32, size, const void *, unsafe_ptr)
./kernel/trace/bpf_trace.c:84: BPF_CALL_3(bpf_probe_write_user, void *, unsafe_ptr, const void *, src,
./kernel/trace/bpf_trace.c:128: BPF_CALL_5(bpf_trace_printk, char *, fmt, u32, fmt_size, u64, arg1,
./kernel/trace/bpf_trace.c:258: BPF_CALL_2(bpf_perf_event_read, struct bpf_map *, map, u64, flags)
./kernel/trace/bpf_trace.c:329: BPF_CALL_5(bpf_perf_event_output, struct pt_regs *, regs, struct bpf_map *, map,
./kernel/trace/bpf_trace.c:390: BPF_CALL_0(bpf_get_current_task)
./kernel/trace/bpf_trace.c:401: BPF_CALL_2(bpf_current_task_under_cgroup, struct bpf_map *, map, u32, idx)
./kernel/trace/bpf_trace.c:426: BPF_CALL_3(bpf_probe_read_str, void *, dst, u32, size,
./kernel/trace/bpf_trace.c:537: BPF_CALL_5(bpf_perf_event_output_tp, void *, tp_buff, struct bpf_map *, map,
./kernel/trace/bpf_trace.c:561: BPF_CALL_3(bpf_get_stackid_tp, void *, tp_buff, struct bpf_map *, map,
# Network
./net/core/filter.c:161: BPF_CALL_0(__get_raw_cpu_id)
./net/core/filter.c:112: BPF_CALL_1(__skb_get_pay_offset, struct sk_buff *, skb)
./net/core/filter.c:117: BPF_CALL_3(__skb_get_nlattr, struct sk_buff *, skb, u32, a, u32, x)
./net/core/filter.c:137: BPF_CALL_3(__skb_get_nlattr_nest, struct sk_buff *, skb, u32, a, u32, x)
./net/core/filter.c:1521: BPF_CALL_5(bpf_l3_csum_replace, struct sk_buff *, skb, u32, offset,
./net/core/filter.c:1565: BPF_CALL_5(bpf_l4_csum_replace, struct sk_buff *, skb, u32, offset,
./net/core/filter.c:1618: BPF_CALL_5(bpf_csum_diff, __be32 *, from, u32, from_size,
./net/core/filter.c:1657: BPF_CALL_2(bpf_csum_update, struct sk_buff *, skb, __wsum, csum)
./net/core/filter.c:1758: BPF_CALL_3(bpf_clone_redirect, struct sk_buff *, skb, u32, ifindex, u64, flags)
./net/core/filter.c:1808: BPF_CALL_2(bpf_redirect, u32, ifindex, u64, flags)
./net/core/filter.c:1885: BPF_CALL_1(bpf_get_cgroup_classid, const struct sk_buff *, skb)
./net/core/filter.c:1897: BPF_CALL_1(bpf_get_route_realm, const struct sk_buff *, skb)
./net/core/filter.c:1909: BPF_CALL_1(bpf_get_hash_recalc, struct sk_buff *, skb)
./net/core/filter.c:1926: BPF_CALL_1(bpf_set_hash_invalid, struct sk_buff *, skb)
./net/core/filter.c:3035: BPF_CALL_1(bpf_get_socket_cookie, struct sk_buff *, skb)
./net/core/filter.c:3047: BPF_CALL_1(bpf_get_socket_uid, struct sk_buff *, skb)
./net/core/filter.c:1942: BPF_CALL_2(bpf_set_hash, struct sk_buff *, skb, u32, hash)
./net/core/filter.c:1844: BPF_CALL_4(bpf_sk_redirect_map, struct sk_buff *, skb,
./net/core/filter.c:1499: BPF_CALL_2(bpf_skb_pull_data, struct sk_buff *, skb, u32, len)
./net/core/filter.c:1432: BPF_CALL_5(bpf_skb_store_bytes, struct sk_buff *, skb, u32, offset,
./net/core/filter.c:1469: BPF_CALL_4(bpf_skb_load_bytes, const struct sk_buff *, skb, u32, offset,
./net/core/filter.c:3065: BPF_CALL_5(bpf_setsockopt, struct bpf_sock_ops_kern *, bpf_sock,
./net/core/filter.c:1960: BPF_CALL_3(bpf_skb_vlan_push, struct sk_buff *, skb, __be16, vlan_proto,
./net/core/filter.c:1987: BPF_CALL_1(bpf_skb_vlan_pop, struct sk_buff *, skb)
./net/core/filter.c:2163: BPF_CALL_3(bpf_skb_change_proto, struct sk_buff *, skb, __be16, proto,
./net/core/filter.c:2202: BPF_CALL_2(bpf_skb_change_type, struct sk_buff *, skb, u32, pkt_type)
./net/core/filter.c:2318: BPF_CALL_4(bpf_skb_adjust_room, struct sk_buff *, skb, s32, len_diff,
./net/core/filter.c:2367: BPF_CALL_3(bpf_skb_change_tail, struct sk_buff *, skb, u32, new_len,
./net/core/filter.c:2418: BPF_CALL_3(bpf_skb_change_head, struct sk_buff *, skb, u32, head_room,
./net/core/filter.c:2722: BPF_CALL_5(bpf_skb_event_output, struct sk_buff *, skb, struct bpf_map *, map,
./net/core/filter.c:2752: BPF_CALL_4(bpf_skb_get_tunnel_key, struct sk_buff *, skb, struct bpf_tunnel_key *, to,
./net/core/filter.c:2819: BPF_CALL_3(bpf_skb_get_tunnel_opt, struct sk_buff *, skb, u8 *, to, u32, size)
./net/core/filter.c:2855: BPF_CALL_4(bpf_skb_set_tunnel_key, struct sk_buff *, skb,
./net/core/filter.c:2925: BPF_CALL_3(bpf_skb_set_tunnel_opt, struct sk_buff *, skb,
./net/core/filter.c:2974: BPF_CALL_3(bpf_skb_under_cgroup, struct sk_buff *, skb, struct bpf_map *, map,
./net/core/filter.c:2458: BPF_CALL_2(bpf_xdp_adjust_head, struct xdp_buff *, xdp, int, offset)
./net/core/filter.c:2639: BPF_CALL_2(bpf_xdp_redirect, u32, ifindex, u64, flags)
./net/core/filter.c:2662: BPF_CALL_4(bpf_xdp_redirect_map, struct bpf_map *, map, u32, ifindex, u64, flags,
./net/core/filter.c:3010: BPF_CALL_5(bpf_xdp_event_output, struct xdp_buff *, xdp, struct bpf_map *, map,
每个BPF_CALL都要定义一个对应的proto接口,用于verifier做参数检检查
const struct bpf_func_proto bpf_map_lookup_elem_proto = {
.func = bpf_map_lookup_elem,
.gpl_only = false,
.pkt_access = true,
.ret_type = RET_PTR_TO_MAP_VALUE_OR_NULL,
.arg1_type = ARG_CONST_MAP_PTR,
.arg2_type = ARG_PTR_TO_MAP_KEY,
};
2.6 BPF xxx_kern.c , xxx_user.c
BPF的编程包括两个部分
- bpf 的kernel程序
- 定义map数据结构
- 使用有限的C语言特性,比如不能有循环
- 可以定义多个bpf prog函数,被调用的函数要用inline
- 只能调用BPF_CALL的kernel的接口
- bpf的用户程序
- 一个可执行程序
- 调用bpf()系统调用传入bpf kernel程序编译后的的bytecode
- 使用循环获取map值
示例代码:
BPF kernel 代码
samples/bpf/tracex4_kern.c
#include <linux/ptrace.h>
#include <linux/version.h>
#include <uapi/linux/bpf.h>
#include "bpf_helpers.h"
struct pair { //Hash map的value
u64 val;
u64 ip;
};
struct bpf_map_def SEC("maps") my_map = {
.type = BPF_MAP_TYPE_HASH, // 使用Hash类型的map
.key_size = sizeof(long), // key是一个long,实际是分配的内存的指针
.value_size = sizeof(struct pair),
.max_entries = 1000000, // 存放1M个记录
};
/* kprobe is NOT a stable ABI. If kernel internals change t
* example will no longer be meaningful
*/
// void kmem_cache_free(struct kmem_cache *s, void *x)
SEC("kprobe/kmem_cache_free") // 使用kprobe event,探测kmem_cache_free()接口
int bpf_prog1(struct pt_regs *ctx)
{
long ptr = PT_REGS_PARM2(ctx); // 得到kmem_cache_free第二个参数, 即要释放的地址
bpf_map_delete_elem(&my_map, &ptr); // 删除hash map entry
return 0;
}
// void *kmem_cache_alloc_node(struct kmem_cache *s, gfp_t gfpflags, int node)
SEC("kretprobe/kmem_cache_alloc_node") //使用kretprobe event,记录分配内存的指针
int bpf_prog2(struct pt_regs *ctx)
{
long ptr = PT_REGS_RC(ctx); // 存放返回指针的寄存器是R0
long ip = 0;
/* get ip address of kmem_cache_alloc_node() caller */
BPF_KRETPROBE_READ_RET_IP(ip, ctx); // 记录caller 到ip,即内存分配者
struct pair v = {
.val = bpf_ktime_get_ns(),
.ip = ip,
};
bpf_map_update_elem(&my_map, &ptr, &v, BPF_ANY); // 记录pair到hash map
return 0;
}
char _license[] SEC("license") = "GPL";
u32 _version SEC("version") = LINUX_VERSION_CODE;
BPF user 代码
samples/bpf/tracex4_user.c
#include "libbpf.h"
#include "bpf_load.h"
struct pair {
long long val;
__u64 ip;
};
static __u64 time_get_ns(void)
{
struct timespec ts;
clock_gettime(CLOCK_MONOTONIC, &ts);
return ts.tv_sec * 1000000000ull + ts.tv_nsec;
}
static void print_old_objects(int fd)
{
long long val = time_get_ns();
__u64 key, next_key;
struct pair v;
key = write(1, "\e[1;1H\e[2J", 12); /* clear screen */
key = -1;
while (bpf_map_get_next_key(map_fd[0], &key, &next_key) == 0) { //遍历map
bpf_map_lookup_elem(map_fd[0], &next_key, &v); // 得到map entry的值
key = next_key;
if (val - v.val < 1000000000ll)
/* object was allocated more then 1 sec ago */
continue;
printf("obj 0x%llx is %2lldsec old was allocated at ip %llx\n",
next_key, (val - v.val) / 1000000000ll, v.ip);
}
}
int main(int ac, char **argv)
{
struct rlimit r = {RLIM_INFINITY, RLIM_INFINITY};
char filename[256];
int i;
snprintf(filename, sizeof(filename), "%s_kern.o", argv[0]);
if (setrlimit(RLIMIT_MEMLOCK, &r)) {
perror("setrlimit(RLIMIT_MEMLOCK, RLIM_INFINITY)");
return 1;
}
// load_bpf_file -> do_load_bpf_file -> load_and_attach -> bpf_load_program -> sys_bpf(BPF_PROG_LOAD, &attr, sizeof(attr))
| | | |
samples/bpf/bpf_load.c samples/bpf/bpf_load.c tools/lib/bpf/bpf.c tools/lib/bpf/bpf.c
if (load_bpf_file(filename)) {
printf("%s", bpf_log_buf);
return 1;
}
for (i = 0; ; i++) {
print_old_objects(map_fd[1]);
sleep(1);
}
return 0;
}
3. Arm64 Linux上使用eBPF工具集BCC
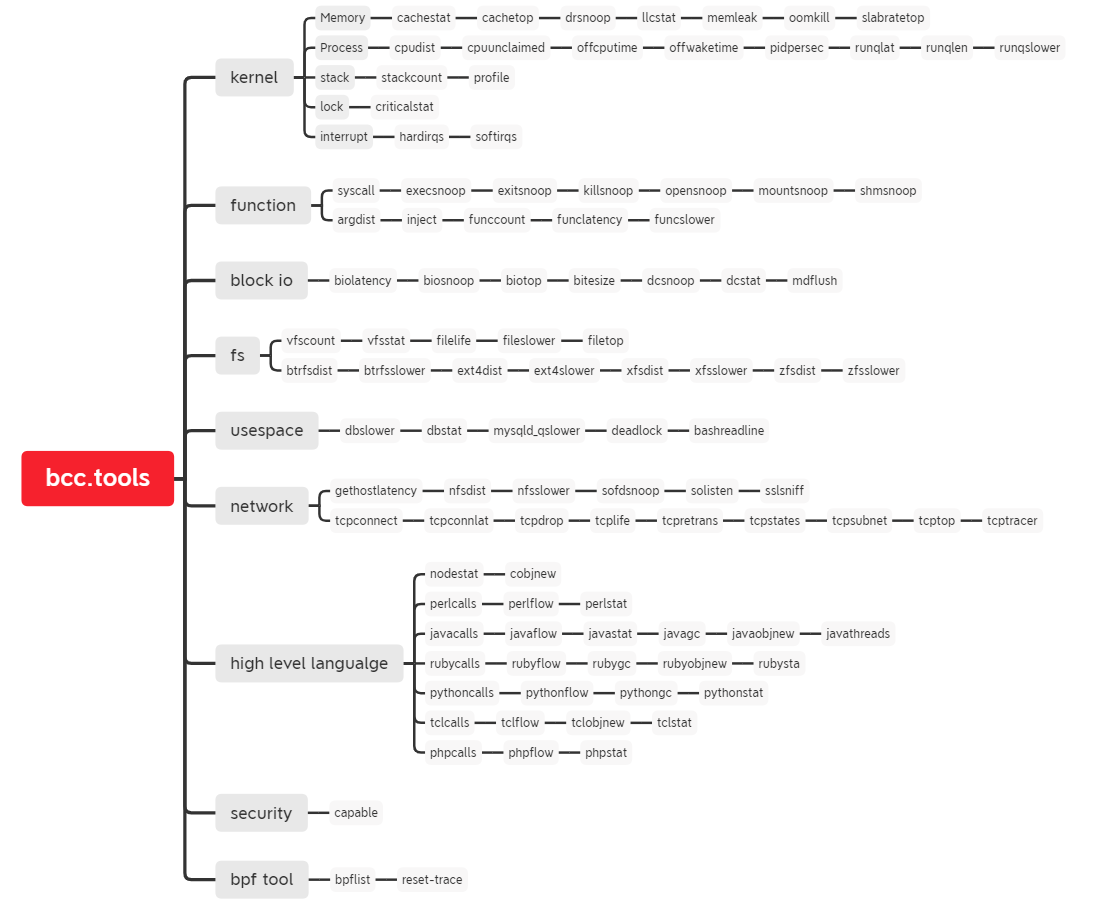
BCC是eBPF最主要的支持库和工具集,可以基于BCC写自己的bpf程序,也可以使用已有的100多个bcc 工具进行跟踪或性能分析。
但是因为BCC依赖于Clang+LLVM,导致大量的库依赖,交叉编译难度较大。
目前Android等Arm Linux系统比较方便的方案是使用adeb(Android Debian)项目的adeb。 [https://github.com/joelagnel/adeb] 。
adeb相当于预先构建一个ARM64的Debian rootfs,传到板子上(或通过nfs挂载)后,用chroot切换到debian文件系统,就可以直接使用里面编译好的Clang+LLVM+GCC工具链了。
这个ARM64 Debian文件系统是从Debian源里直接下载安装的,可以根据需要定制安装包,可以自动解决依赖关系。
Debian源里的BCC版本可能比较老,也可以在下载最新BCC源码,直接在板子上编译。
kernel需要打开的BPF相关配置:
CONFIG_BPF_SYSCALL=y
CONFIG_BPF_JIT_ALWAYS_ON=y
CONFIG_BPF_STREAM_PARSER=y
CONFIG_HAVE_BPF_JIT=y
CONFIG_BPF_JIT=y
CONFIG_BPF_EVENTS=y
3.1 adeb安装
adeb为Android系统设计,默认使用adb和Android的/data目录,也支持ssh,做少许修改就可以使用
diff --git a/androdeb b/androdeb
index a2ee65b..f215508 10075
--- a/androdeb
+++ b/androdeb
@@ -14,11 +14,11 @@ source $spath/utils/remote
# Set default vars
DISTRO=buster; ARCH=arm64
ADB="adb"
-REMOTE="adb"
-FULL=0 # Default to a minimal install
+REMOTE="ssh"
+FULL=1 # Default to a minimal install
DOWNLOAD=1 # Default to downloading from web
-SKIP_DEVICE=0 # Skip device preparation
-INSTALL_BCC=0 # Decide if BCC is to be installed
+SKIP_DEVICE=1 # Skip device preparation
+INSTALL_BCC=1 # Decide if BCC is to be installed
完全安装包需要2GB空间,可以放在/userdata分区,sd卡里,或者nfs映射。
nfs相对比较快捷,因为每次解压安装可能需要十几分钟时间。
-
方法一: 安装到板板子上,
# 板子确保/userdata有2G空间,执行: mkdir /userdata/data mount -o remount,rw / ln -s /data /userdata/data # Linux上执行: 解压adeb.tgz cd adeb ./adeb --ssh root@192.168.2.12 prepare --archive tars/androdeb-fs.tgz # 等待安装完成,大概十几分钟... ./adeb --ssh root@192.168.2.12 shell cd /usr/share/bcc/tools/ ls # 即可执行bcc命令。 -
方法二:nfs挂载
# Linux上执行: cd adeb/tars tar xvf androdeb-fs.tgz # 板子上挂载nfs mount -o remount,rw / mkdir /data/ mount -t nfs -o nolock 192.168.2.123:/home/yu/adeb/tars/debian /data ./adeb --ssh root@192.168.2.12 shell cd /usr/share/bcc/tools/ ls # 即可执行bcc命令。
2. bcc 工具使用。
bcc自带了100多个工具,/usr/share/bcc/tools/doc/下有每个工具的说明文档
$ pwd
/home/yu/src/bpf/adeb/tars/debian/usr/share/bcc/tools/doc
yu@yu doc (master) $ ls
argdist_example.txt fileslower_example.txt opensnoop_example.txt stackcount_example.txt
bashreadline_example.txt filetop_example.txt perlcalls_example.txt statsnoop_example.txt
biolatency_example.txt funccount_example.txt perlflow_example.txt syncsnoop_example.txt
biosnoop_example.txt funclatency_example.txt perlstat_example.txt syscount_example.txt
biotop_example.txt funcslower_example.txt phpcalls_example.txt tclcalls_example.txt
bitesize_example.txt gethostlatency_example.txt phpflow_example.txt tclflow_example.txt
bpflist_example.txt hardirqs_example.txt phpstat_example.txt tclobjnew_example.txt
btrfsdist_example.txt inject_example.txt pidpersec_example.txt tclstat_example.txt
btrfsslower_example.txt javacalls_example.txt profile_example.txt tcpaccept_example.txt
cachestat_example.txt javaflow_example.txt pythoncalls_example.txt tcpconnect_example.txt
cachetop_example.txt javagc_example.txt pythonflow_example.txt tcpconnlat_example.txt
capable_example.txt javaobjnew_example.txt pythongc_example.txt tcpdrop_example.txt
cobjnew_example.txt javastat_example.txt pythonstat_example.txt tcplife_example.txt
cpudist_example.txt javathreads_example.txt reset-trace_example.txt tcpretrans_example.txt
cpuunclaimed_example.txt killsnoop_example.txt rubycalls_example.txt tcpstates_example.txt
criticalstat_example.txt lib rubyflow_example.txt tcpsubnet_example.txt
cthreads_example.txt llcstat_example.txt rubygc_example.txt tcptop_example.txt
dbslower_example.txt mdflush_example.txt rubyobjnew_example.txt tcptracer_example.txt
dbstat_example.txt memleak_example.txt rubystat_example.txt tplist_example.txt
dcsnoop_example.txt mountsnoop_example.txt runqlat_example.txt trace_example.txt
dcstat_example.txt mysqld_qslower_example.txt runqlen_example.txt ttysnoop_example.txt
deadlock_example.txt nfsdist_example.txt runqslower_example.txt vfscount_example.txt
drsnoop_example.txt nfsslower_example.txt shmsnoop_example.txt vfsstat_example.txt
execsnoop_example.txt nodegc_example.txt slabratetop_example.txt wakeuptime_example.txt
exitsnoop_example.txt nodestat_example.txt sofdsnoop_example.txt xfsdist_example.txt
ext4dist_example.txt offcputime_example.txt softirqs_example.txt xfsslower_example.txt
ext4slower_example.txt offwaketime_example.txt solisten_example.txt zfsdist_example.txt
filelife_example.txt oomkill_example.txt sslsniff_example.txt zfsslower_example.txt
https://github.com/iovisor/bcc/tree/master/tools
下面脑图是分类整理:
4. Reference
- 《BPF Performance Tool - Linux System and Application Observation》, Brendan Gregg
- LWN: A thorough introduction to eBPF
- LWN: An introduction to the BPF Compiler Collection
- https://events.static.linuxfound.org/sites/events/files/slides/ELC_2017_NA_dynamic_tracing_tools_on_arm_aarch64_platform.pdf
- eBPF In-kernel Virtual Machine & Cloud Computing
- https://elinux.org/images/d/dc/Kernel-Analysis-Using-eBPF-Daniel-Thompson-Linaro.pdf
- GCC,Clang, LLVM https://stackoverflow.com/questions/24836183/understanding-g-vs-clang-vs-llvm/24836566
- eBPF Trace from Kernel to Userspace PPT, eBPF基本概念介绍非常清楚
- Using Perf and its friend eBPF on Arm platform Leo Yan, Linaro
- LWN: BPFd: Running BCC tools remotely across systems and architectures, Joel Fernandes, Jan 2018
- Linux超能力BPF技术介绍及学习分享
— End—
文章标题:Ftrace的配置和使用
本文作者:hpyu
本文链接:https://www.cnblogs.com/hpyu/articles/14254250.html
欢迎转载,请注明原文链接# 【原创】Kernel调试追踪技术之 eBPF on ARM64

 浙公网安备 33010602011771号
浙公网安备 33010602011771号