
20182316胡泊 第7周学习总结
20182316胡泊 2019-2020-1 《数据结构与面向对象程序设计》第7周学习总结
教材学习内容总结
第十二章:算法分析
- 增长函数与O
- 增长函数:就是一个表示问题大小与 所用的时间(时间复杂度)或空间(空间复杂度)之间的关系
- 时间复杂度的阶称为渐进复杂度,它反映了函数增长的快慢,变量越大,变化越明显。
- 阶由算法增长函数的主项决定,即函数中增长率最大(趋向无穷大时)的那个项。
- 计算复杂度(O)
- 最直接,最简单的方法就是看最内层的语句执行了几次
第十四章:栈
- 对象、封装与接口的关系:一个好的对象应该是内部封装的,意味着从外面不能访问对象内部的变量或方法,因为对象内部的变量绝大部分都是定义为私有的,因此用户要想使用对象的方法,就必须通过接口来实现对象的共有方法,这些方法代表对象提供的服务。
- 数据类型:指的是一组值以及定义在值上的操作
- 抽象数据类型(abstract data type,ADT):指其值和操作都没有定义的一种数据类型。
- 数据结构:用来实现集合的基本程序设计结构。
- 栈
- 示意图(后进先出)

- 栈的操作:
| 操作 | 描述 |
|---|---|
| boolean empty() | 测试堆栈是否为空 |
| Object peek( ) | 查看堆栈顶部的对象,但不从堆栈中移除它 |
| Object pop( ) | 移除堆栈顶部的对象,并作为此函数的值返回该对象 |
| Object push(Object element) | 把项压入堆栈顶部 |
| int size() | 返回栈中元素的个数 |
- 泛型
- 之前涉及过通过继承实现多态,而Object则是所有类型的父类,因此只要将一个数组指向Object类型,那么该数组理论上就可以保存所有类型的数据了,这是一种极端情况
- 但是,当使用了Object后,容易出现兄弟类型之间转换的问题,编译不会报错,但是运行时会出错。
- 泛型:可以定义一个类,可以保存数据及操作,但只有当实例化时才确定类型(一般用T来表示泛型)
class Box<T>
{
T类型对象的声明与操作代码
}
当要使用Box定义的数据时,通过实例化来实现它的具体类型,来替代T
Box<Integer> box1=new Box<Integer>;
Box<String> box2=new Box<String>;
...
- 计算后缀表达式
- 原理:后缀表达式及为运算符号在数字的后面,而放在栈中实现,就是:碰到数字就push到栈里面,碰到运算符号就pop两位数字,然后进行相应的运算,再将结果push回链表中,继续参加运算。
String temp;
int a,b,result = 0;
Scanner scan=new Scanner(System.in);
Stack<Integer> stack = new Stack<>();
System.out.println("input: (n to stop)");
temp=scan.nextLine();
while(!(temp.equals("n"))){
if(temp.equals("+")||temp.equals("-")||temp.equals("*")||temp.equals("/")){
//检测是否为运算符
a=stack.pop();
b=stack.pop();
// 弹出位于栈顶的两个元素
Calculate c=new Calculate(temp,a,b); //计算
result=c.jisuan();
stack.push(result); //push回去
} //循环
else{
stack.push(Integer.parseInt(temp));
} // 若为数字则直接输入栈
temp=scan.nextLine();
}
System.out.println(stack);
-
管理容量
- 初始化一定容量的栈
Object[] collection=Object[500];- 如果栈满了,还想要输入,那么就必须扩容
- 扩容的实质是新建一个容量更大的栈(一般为两倍),然后将原始栈的元素赋到新的栈中,因为栈的容量不能改变。
-
链(Linked)
-
我的理解:链式结构就是保存一串相同数据类型的方式,其特殊之处在于要新定义一个类,此类必须有其内容,以及一个该类型的next变量,指向下一项,next初始化为null,当要使用时再赋值,链的各种方法也是基于此。
-
方法
1.插入结点
在插入的时候一定要让后插入的结点,先和后面的接起来,否则直接连的话就会导致后面节点的丢失。
public static Number InsertNode(Number Head, Number node1,Number node2) { Number point=Head; while(point.num!=node1.num){ point=point.next; } node2.next=point.next; point.next=node2; return Head; }2.删除结点
删除就直接将删除结点的前一个结点与后一个结点相连
但删除的关键是怎样找到删除结点的前一个结点的位置,这里用的是.next,不找删除点,直接找到他的前一个。
这里要注意,point.next=point.next.next;不能写成
point.next=node.next;因为这样看似很科学,将删除结点的前一个与结点后一个直接相连,但是!!! 此时node并不是那个要删除的结点,它只是与删除节点的内容相同,最重要的是node后面并没有删除结点应该有的next(node.next等于null),所以这样会导致直接将后面的都删除了(惨痛教训)!!!
public static Number Delete(Number Head,Number node){ Number point=Head; while(point.next.num!=node.num){ point=point.next; } point.next=point.next.next; return Head; }3.结点排序
- 结点的排序有两种方法:交换指针、交换内容
- 交换内容明显比交换指针更简单,因此这里我用的是交换内容
- 而排序方法用的则是冒泡排序法,方法中规中矩就不多赘述了。
public static Number Sort(Number Head){ Number point,point2; int i,temp,j,max; for(point=Head;point!=null;point=point.next){ max=point.num; for(point2=point;point2!=null;point2=point2.next){ if(point2.num>max){ max=point2.num; temp=point.num; point.num=point2.num; point2.num=temp; System.out.println(Head); System.out.println(all(Head)); } } } return Head; }结点输出、结点查找、链表长度统计等较为简单
-
栈的实现(数组与链表)
- ArrayStack类
- 我的理解:就是以数组的形式存储数据,但同时具有栈的性质与方法,数组下标为0的位置为栈底,下标更大的为栈顶,实用性更强
public class ArrayStack<T> implements Stack<T> {
private final int LENGTH=10;
private int count;
private T[] stack;
T t3,t4;
public ArrayStack(T t1,T t2) {
count =0;
stack=(T[]) (new Object[LENGTH]);
push(t1);
push(t2);
}
@Override
public void push(T element) {
if(count==stack.length){
expandCapacity();
}
stack[count]=element;
count++;
}
@Override
public T peek() throws EmptyCollectionException {
try {
if(isEmpty())
throw new EmptyCollectionException("nothing in stack");
}
catch (EmptyCollectionException exception)
{
System.out.println("nothing in stack");
}
return stack[count-1];
}
// 这里只展示push和peek操作
-
LinkedStack实现
- 我的理解:首先LinkedStack类是实现Stack接口的,因此它具有Stack所定义的共有方法push、pop等等,而其中保存的变量则是LinerNode(结点)类型的,即类内部的数据具有链表性质,而类则可以使用Stack方法。
import Sta.EmptyCollectionException; public class LinkedStack<T> implements Stack<T> { private int count; private LinearNode<T> top; public LinkedStack(){ count=0; top=null; } @Override public void push(T ele) { LinearNode<T> temp=new LinearNode<T>(ele); temp.setNext(top); top=temp; count++; } @Override public T pop() throws EmptyCollectionException{ if(count==0) throw new EmptyCollectionException("pop operation failed."+ "the stack is empty"); T result=top.getElement(); top=top.getNext(); count--; return result; } @Override public T peek() throws EmptyCollectionException { if(count==0) throw new EmptyCollectionException("peek operation failed."+ "the stack is empty"); T result=top.getElement(); return result; } @Override public boolean isEmpty() { if(top.getElement()==null) return true; else return false; } @Override public int size() throws EmptyCollectionException { int i = 1; if (count == 0) { throw new EmptyCollectionException("peek operation failed." + "the stack is empty"); } else { while (top.getNext()!=null) { top=top.getNext(); i++; } return i;} } @Override public String toString() { String result="<top>"+"\n"; LinearNode current=top; while(current!=null){ result+=current.getElement()+"\n"; current=current.getNext(); } return result+"<bottom>"; } }
教材学习中的问题和解决过程
-
问题1:静态查找和动态查找的区别
-
问题1解决方法:静态或者动态都是针对查找表而言的,动态表指查找表中有删除和插入操作的表。
-
问题2:ASL的含义
-
问题2解决方法:平均查找长度(Average Search Length,ASL):需和指定key进行比较的关键字的个数的期望值,称为查找算法在查找成功时的平均查找长度。用于衡量算法的效率。
-
问题3:利用栈进行计算时,计算完毕条件的判断,我一开始以为是当栈中只剩下一个元素即为预算完毕,像这样:
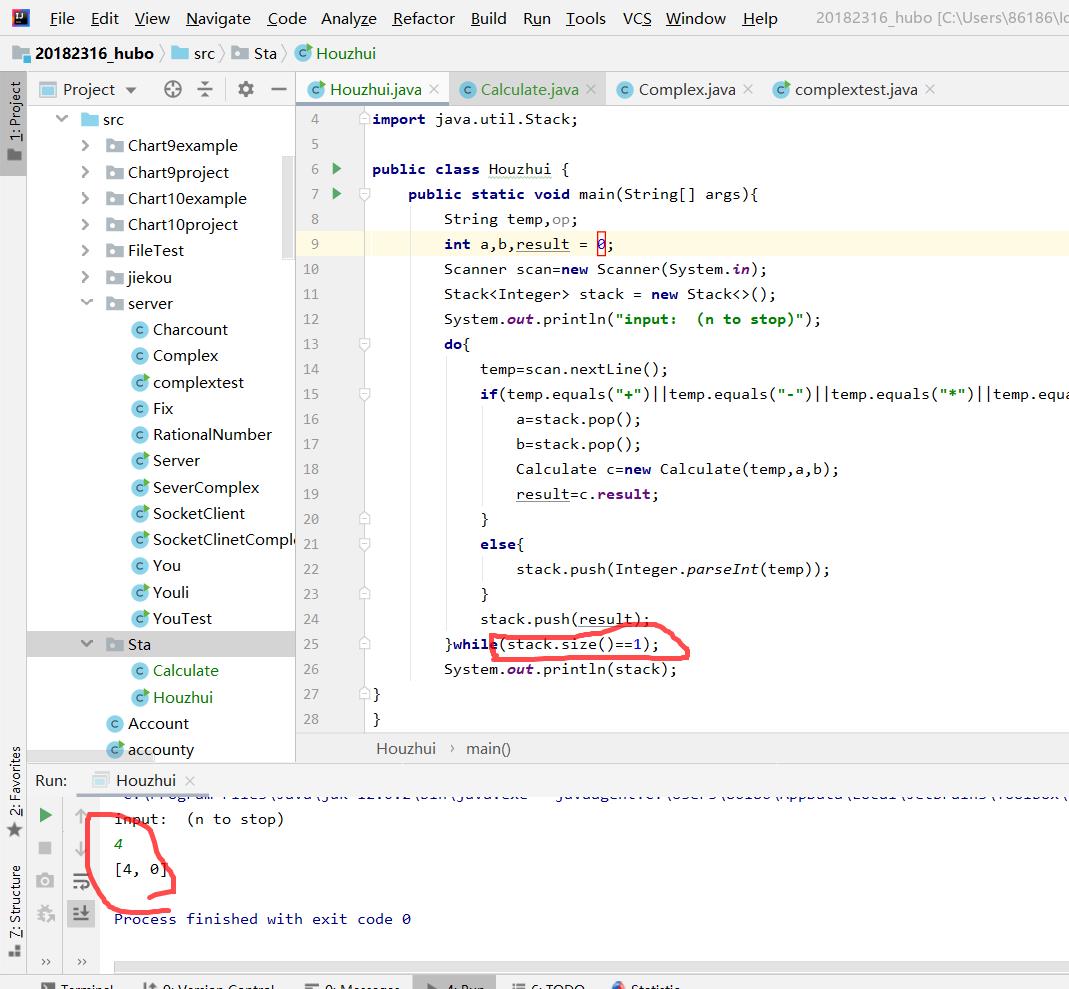
-
问题3解决方法:之前的方法当栈中有元素时可行,但是当栈为空,然后push了一个元素后,程序就终止了,因为满足了仅剩一个元素的条件。于是我把判断条件改为,手动输入“n”才终止。
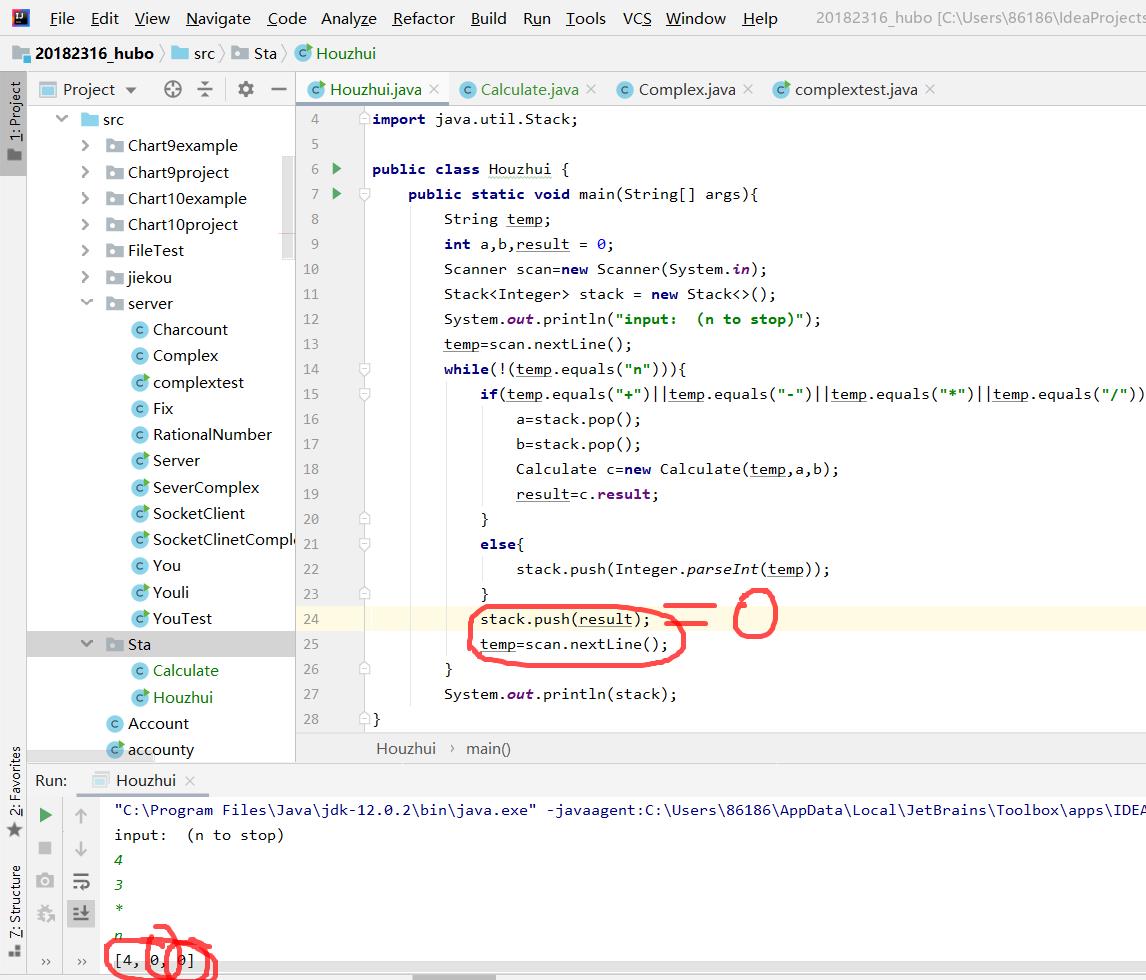
代码调试中的问题和解决过程
- 问题1:StackOverflowError
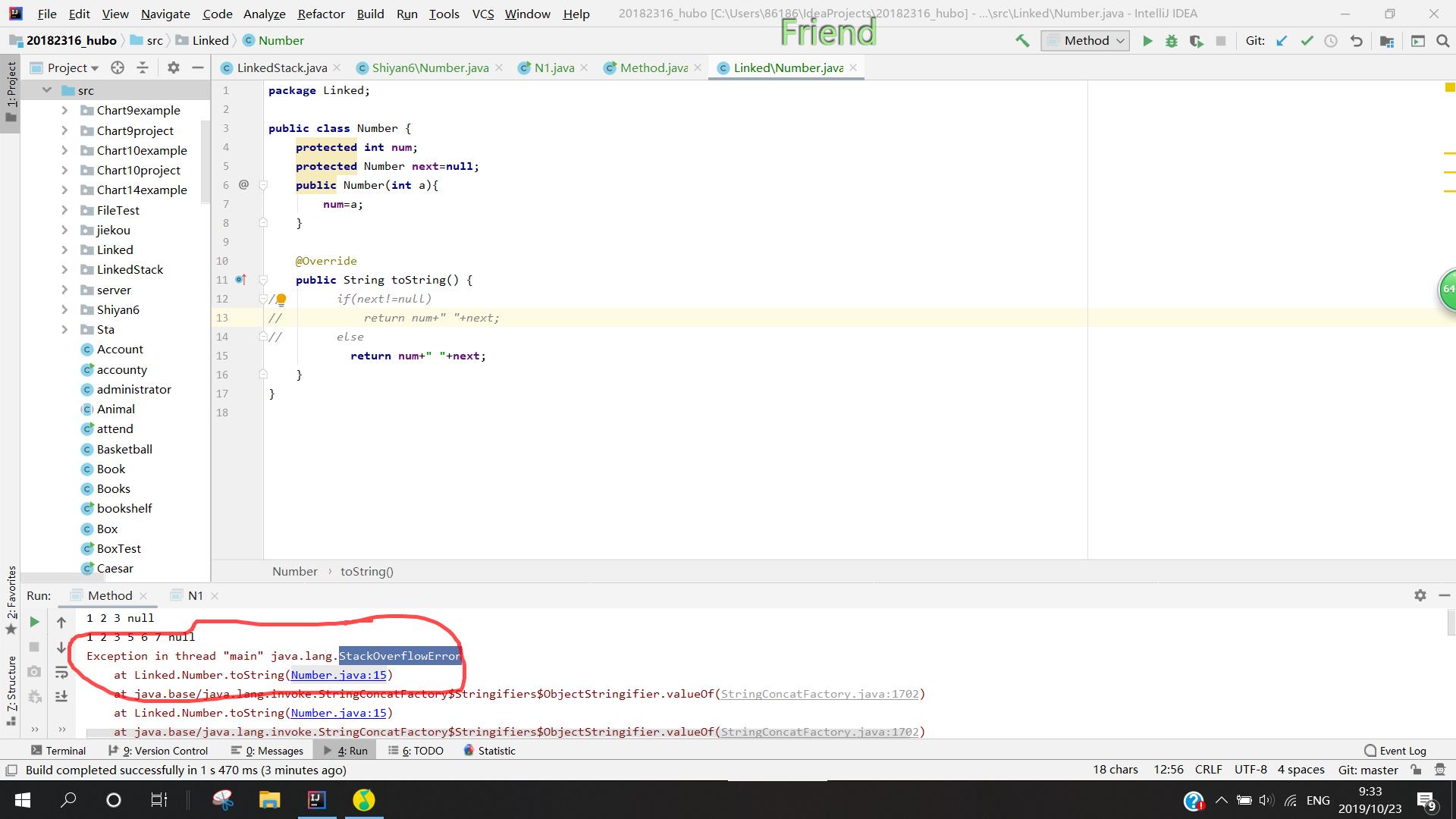
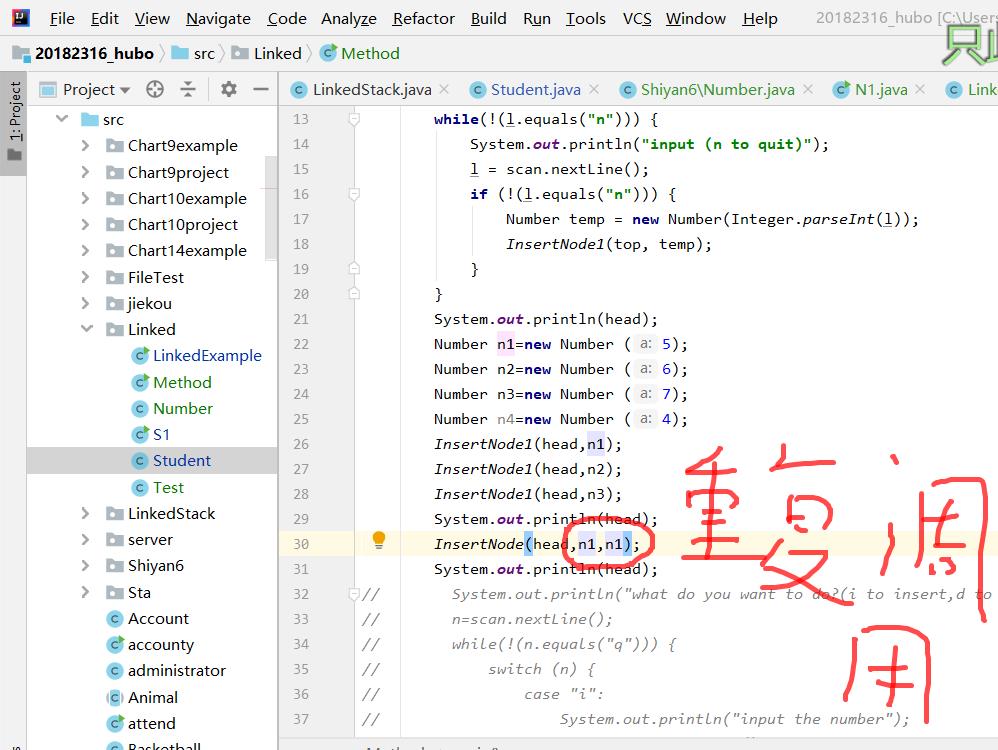
-
问题1解决方法:查了csdn后看到,这个问题是函数调用栈太深了,代码中可能有循环调用方法而无法退出的情况,我找了好久,终于发现我在使用插入方法时,想要将n1插入到n1的后面,我以为这就是个简单插入一个值的问题,但是仔细思考后,发现你n1是我定义的链表(Number)类型的,自带有一个next(Number型),因此将n1插到n1后面,n1.next -->n1.next -->n1,就出现了重复调用的情况。因此定义一个新的结点等于n1就可以了。
参考:StackOverflowError -
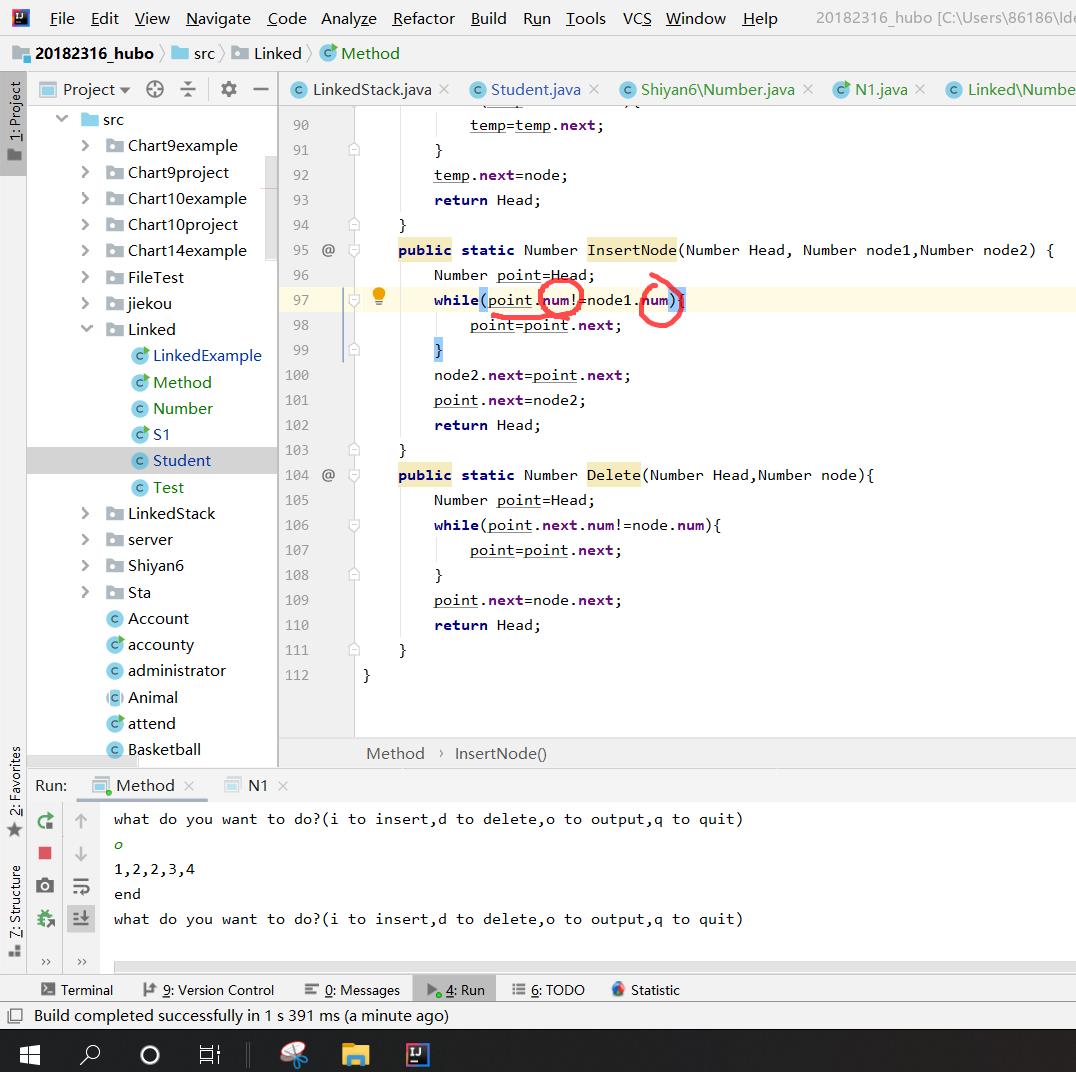
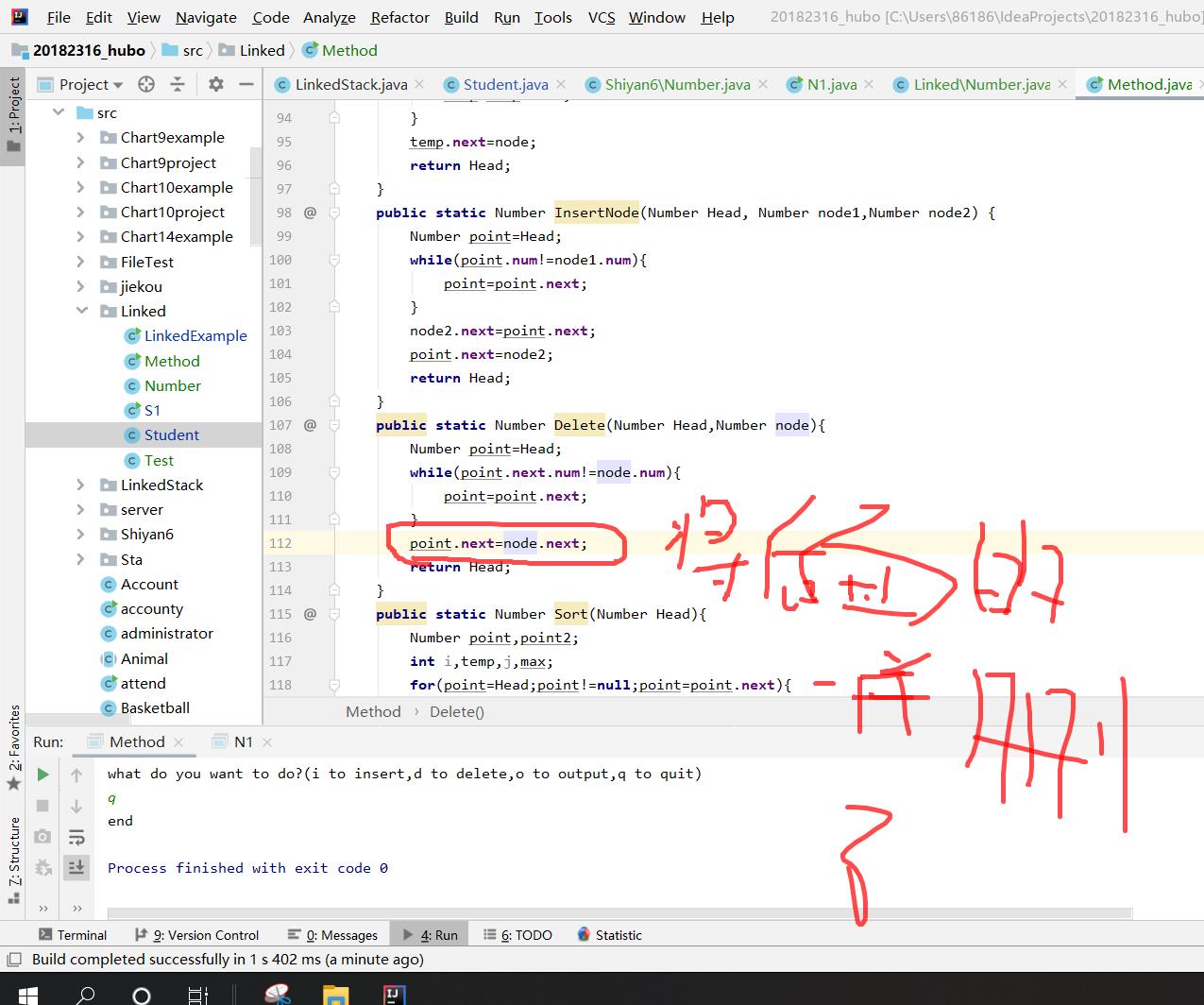
问题2:在编写delete操作时,总是将想要删除的元素以及之后的元素都删除了
- 问题2解决方案:
我原来的方法是:先用point指针指向top,然后向下查找到删除元素的前一位,将其next指向删除元素的下一位,就将删除元素跳过(删除)了。
但是我的代码是
point.next=node.next;
我以为node就是链表里要删除的元素,因为他被当做了循环判定条件,但是他其实只是传过来的、与删除元素值相同的一个节点,他的 .next 其实为空,因此就将后面的一起删掉了。
将代码改为
point.next=point.next.next;

-
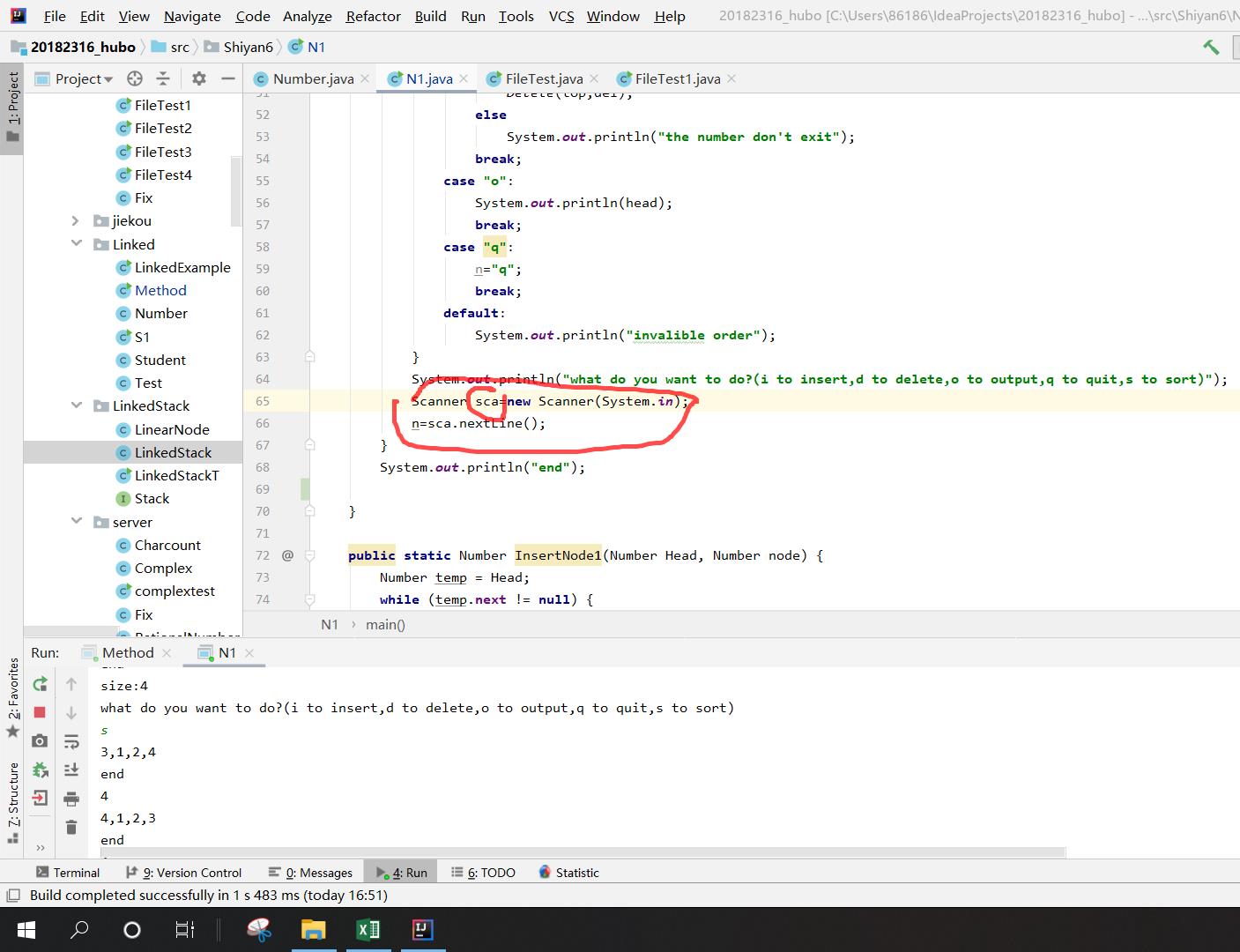
问题3:缓冲区清理的问题:用了一个switch语句,在语句结束时,从键盘输入一个字符串型,作为循环判断条件,case中有int型有String型的输入,在输入int型后,会出现吃回车问题,循环无法结束,因此用了之前用过的清缓冲区方法,打两遍 n=scan.nextLine(); ,但是这样的话当前面switch输入字符型后,又会要输两遍才能给n赋值,于是之前的方法都用不了了。
-
问题3解决方案:重新实例化一个输入变量
Scanner sca=new Scanner(System.in);
n=sca.nextLine();
这样的话就不存在什么缓冲区的问题了。
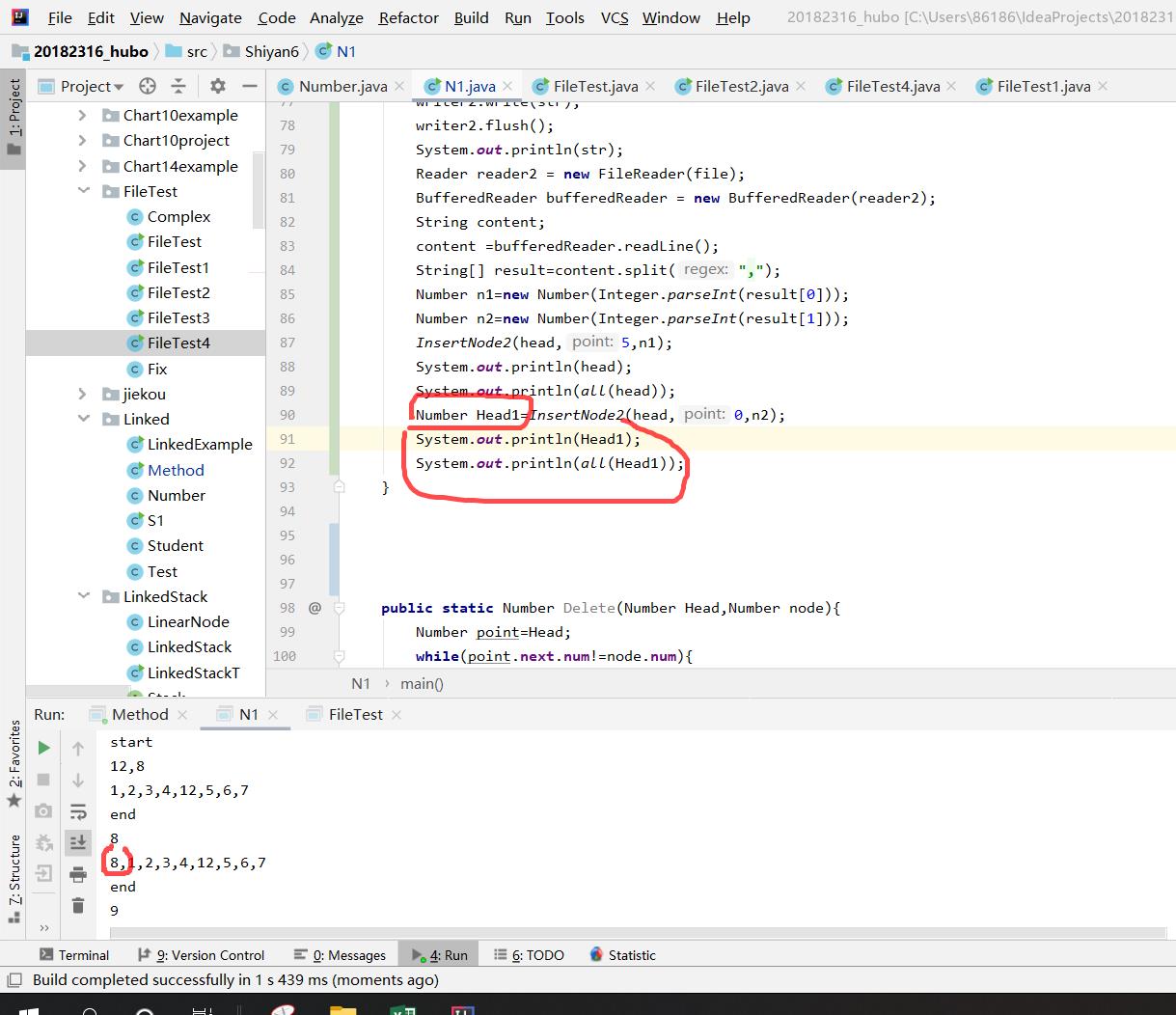
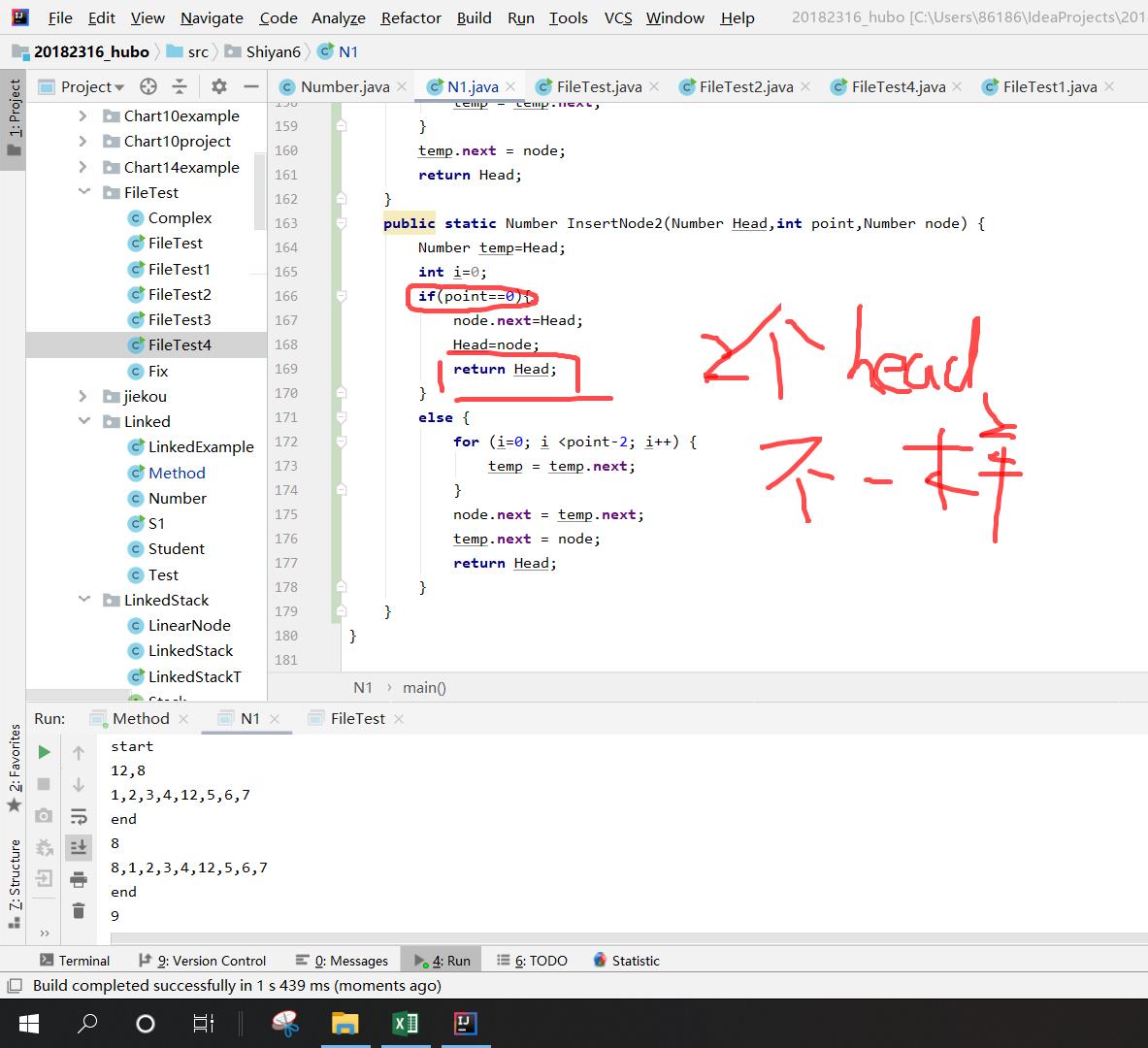
- 问题4:在插入到链表头时,插不进去。(后来知道是插进去了,但是打印时出错了)
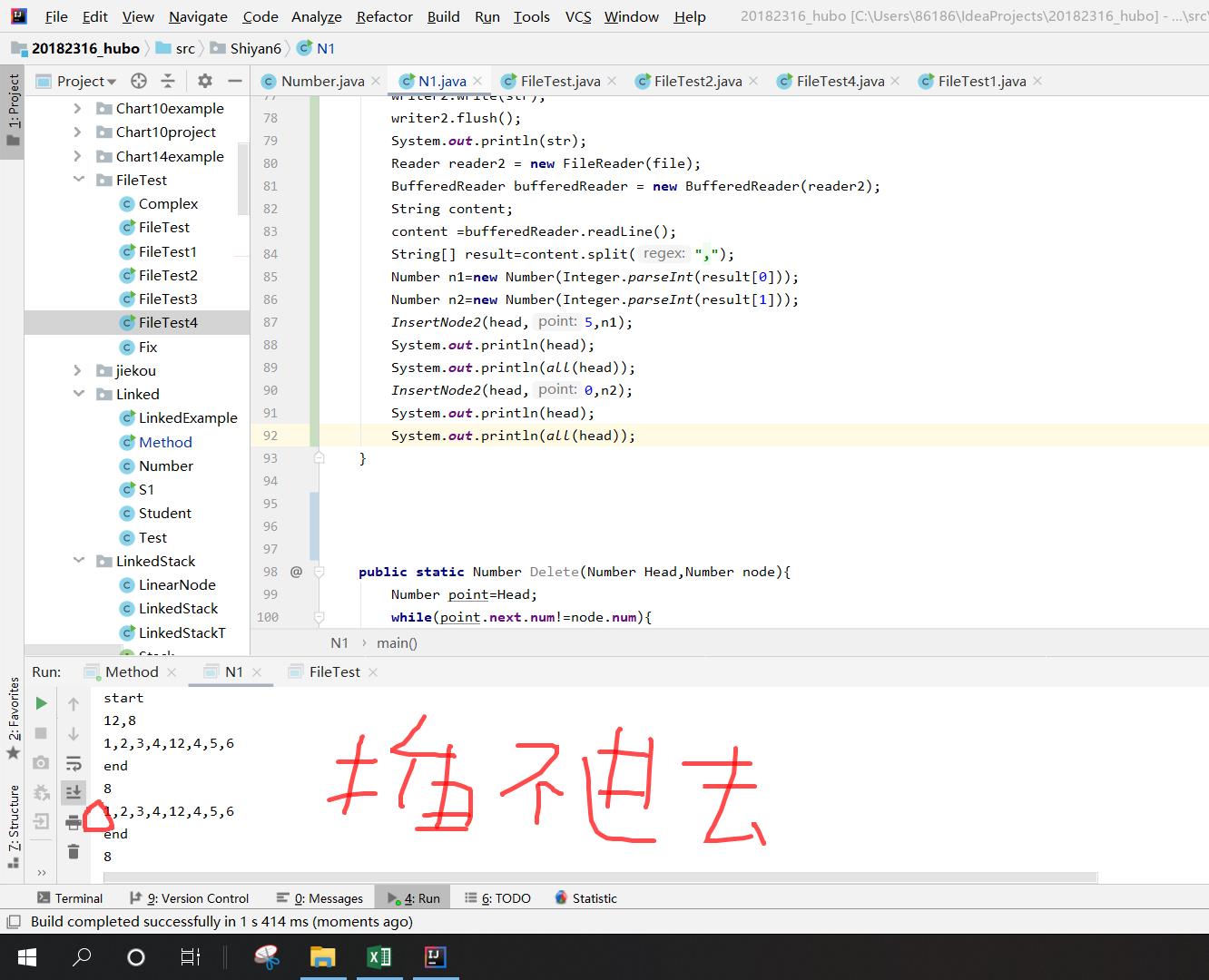
- 问题4解决方法:在插入到链表头的方法中增加一个return head(新的)
if(point==0)
{
node.next=Head;
Head=node;
return Head;
}
而在主函数中则是
InsertNode2(head,0,n2);
System.out.println(head);
因此,并不是没有插进去,而是这时链表的头已经不是head了,因为在方法中改变了他的头,此时n2才是头,而打印的是从原来的头到结尾。
于是我就定义了一个新的变量来接受返回的Head变量,再打印新的链表。
代码托管
上周考试错题总结
结对及互评
-
博客中值得学习的或问题:
- 对上周的错题进行了仔细的更正和课后复习,我对上周考试题的复习较为草率。
- 博客撰写详细,有理有据。
- 在撰写博客的过程中可以加入更多自己的理解。
-
代码中值得学习的或问题:
- 代码风格良好,便于阅读。
-
基于评分标准,我给本博客打分:13分。得分情况如下:
-
正确使用Markdown语法(加1分):
- 不使用Markdown不加分
- 有语法错误的不加分(链接打不开,表格不对,列表不正确...)
- 排版混乱的不加分
-
模板中的要素齐全(加1分)
- 缺少“教材学习中的问题和解决过程”的不加分
- 缺少“代码调试中的问题和解决过程”的不加分
- 代码托管不能打开的不加分
- 缺少“结对及互评”的不能打开的不加分
- 缺少“上周考试错题总结”的不能加分
- 缺少“进度条”的不能加分
- 缺少“参考资料”的不能加分
-
教材学习中的问题和解决过程(3分)
-
代码调试中的问题和解决过程(3分)
-
本周有效代码超过300分行的(加0分)
-
其他加分:
- 周五前发博客的加1分
- 感想,体会不假大空的加1分
- 进度条中记录学习时间与改进情况的加1分
- 有动手写新代码的加1分
- 错题学习深入的加1分
- 点评认真,能指出博客和代码中的问题的加1分
- 结对学习情况真实可信的加1分
点评过的同学博客和代码
- 本周结对学习情况
-
结对照片
-
结对学习内容
对上周及本周的考试内容进行了探讨,并通过上网查询等方式深入分析,直到将问题理解。
一起制作博客,markdown,遇到问题相互询问,并解决。
其他(感悟、思考等,可选)
- 找到自己程序里千奇百怪的问题感觉很爽,许多问题都是打的时候没有好好考虑,那些有难度的只有一小部分。
- 这周学的链表,栈,以及队列很好用,在之后很多程序里都可以用到,并且很方便。
- 在打程序时,有些自带一串变量的变量,比如链表的next、二叉树的left和right,有时候只要它的值,而有时候要这个变量以及后面带着的变量,一定要想好,看好。
- 本来以为单步调试(DeBug)会跟c语言一样,要手动输入变量名字才能查看变量当前数值,但是idea不愧是java编程语言开发的集成环境,以及业界被公认为最好的java开发工具,直接将所有的变量显示了出来,很好用!
- 最近我花在java上的时间是真的多啊,上大学以来,从来没有不得不这么用心学一门课。。。
学习进度条
| 代码行数(实际/预期) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 10000行 | |||
| 第一周 | 119/119 | 3/3 | 20/20 | |
| 第二周 | 302/300 | 2/5 | 25/45 | |
| 第三周 | 780/800 | 2/7 | 25/70 | |
| 第四周 | 1500/1300 | 2/9 | 25/95 | |
| 第五周 | 3068/2500 | 3/12 | 25/120 | |
| 第六周 | 4261/4000 | 2/14 | 25/145 | |
| 第七周 | 7133/7000 | 3/17 | 25/170 |
-
计划学习时间:30小时
-
实际学习时间:25小时
参考资料
- 《Java程序设计与数据结构教程(第二版)》
- StackOverflowError(https://blog.csdn.net/gentlezuo/article/details/90580116)

