1.Apache kafka fundementals
Producer -> Kafka <-Consumer
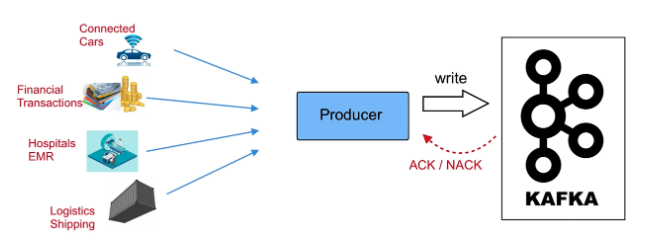
data producer:
data consumer:
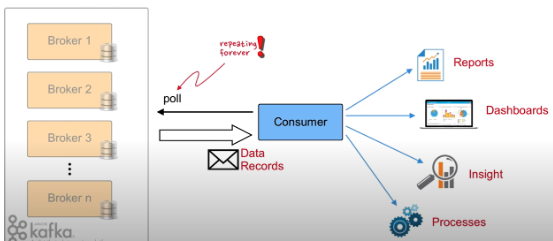
producer & consumer is decoupled producer send data (log or file or other data) to kafka instead of consumer side that more scalability for both producer or consumer .
kafka architecture

zookeeper:
cluster management , failure detection & recovery, store ACLs & secrets
if the leader broker down , the zookeeper will elected a new leader of broker .
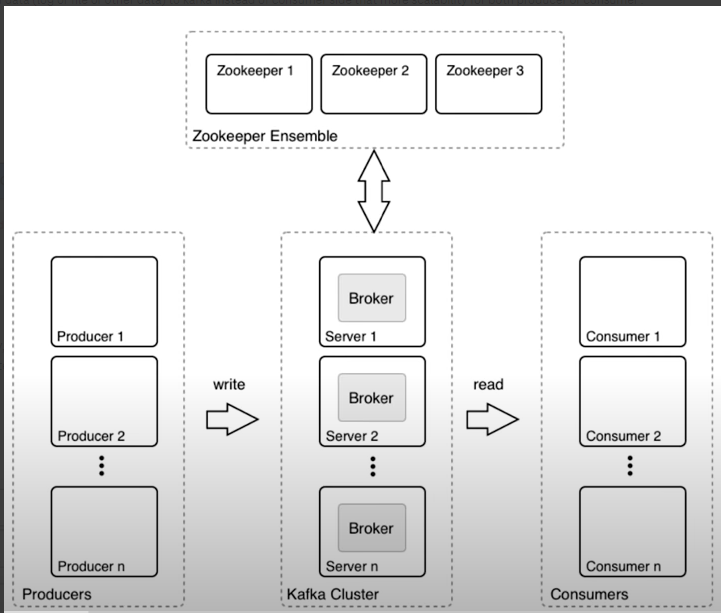
broker:
working node of kafka cluster , each broker has own disk , and topic distributed on it .
topic:
producer produce the data to kafka need to be target a topic
partition:
partition distributed on each broker node , in case one broker down, the data lost , each partition can have multi consumer to difference application
segement:
store the data on disk file.
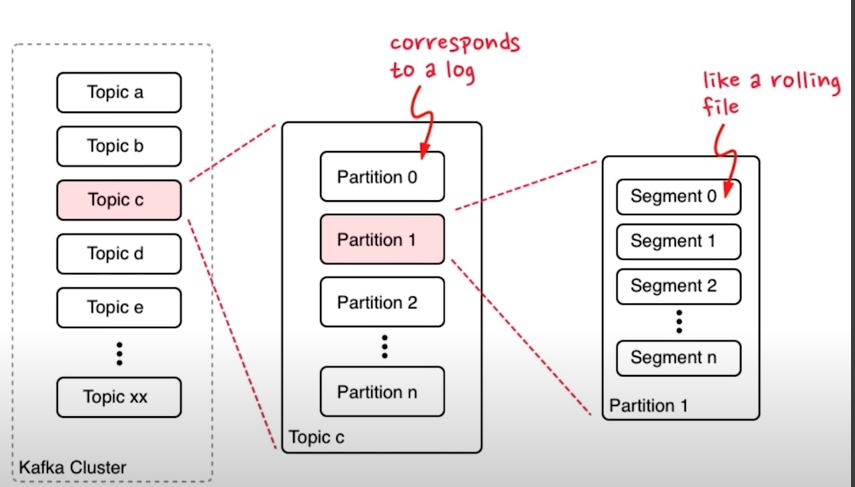
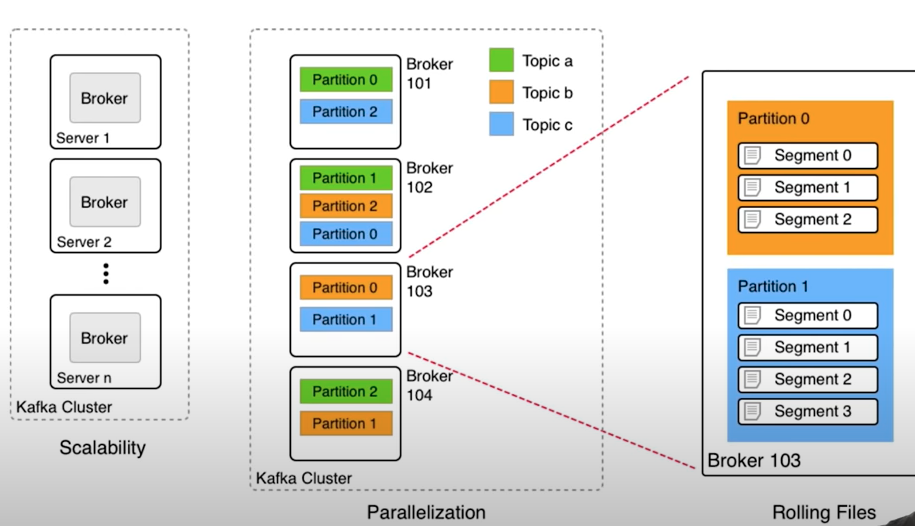
topic data strucature:
2.Kafka workflow
producer:

consumer:
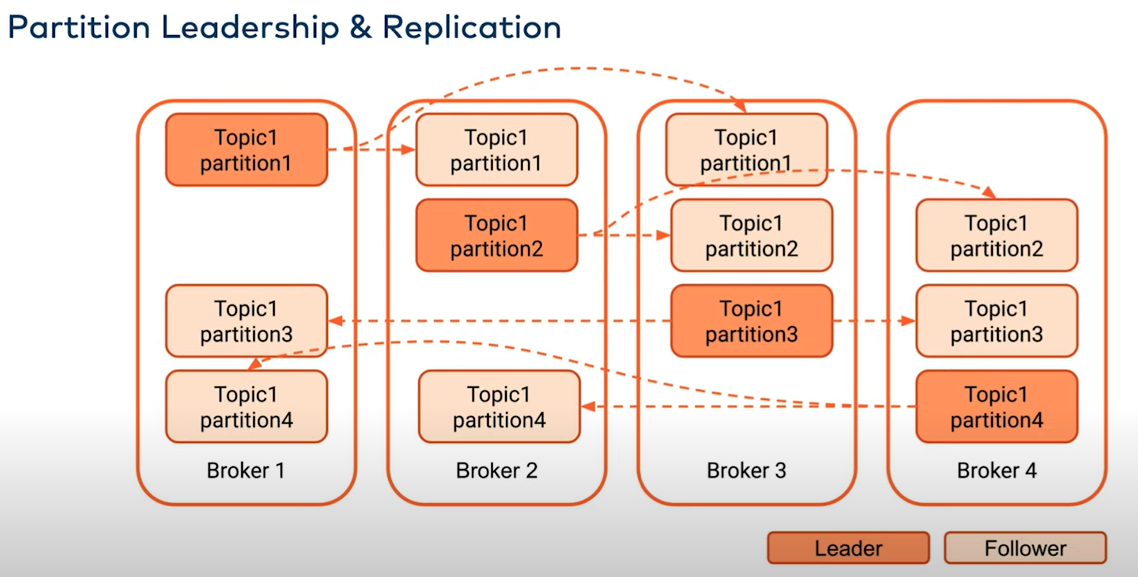
leader: producer produce the data to partition leader and consumer consume the data from partition leader
follower: follow up the leader and write data or log to it own log.
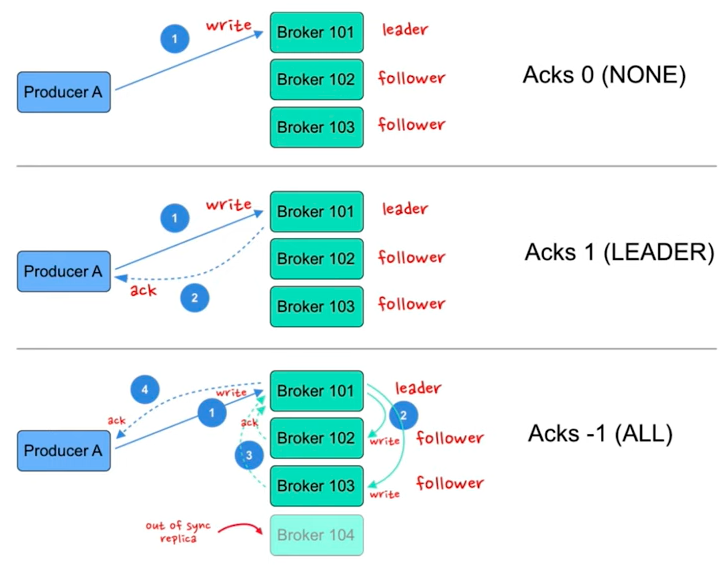
three mode:
A: low latency on producer side and might be loss data
B: wait for leader acks
C: wait for both leader and follower acks
acks: the broker write the data to disk and response to producer
trouble shooting:
1.conflunet control center
2.kafka log file
3.ssl logging
4.authorizer debugging
security:
kafka broker -> broker broker -> zookeeper can use ssl to encrpty
Serializers and Deserializers:
The serializer passes the unique ID of the schema as part of the Kafka message so that consumers can use the correct schema for deserialization. The ID can be in the message payload or in the message headers. The default location is the message payload
before transmitting the entire message to the broker, let the producer know how to convert the message into byte array we use serializers. Similarly, to convert the byte array back to the object we use the deserializers by the consumer.
schema:
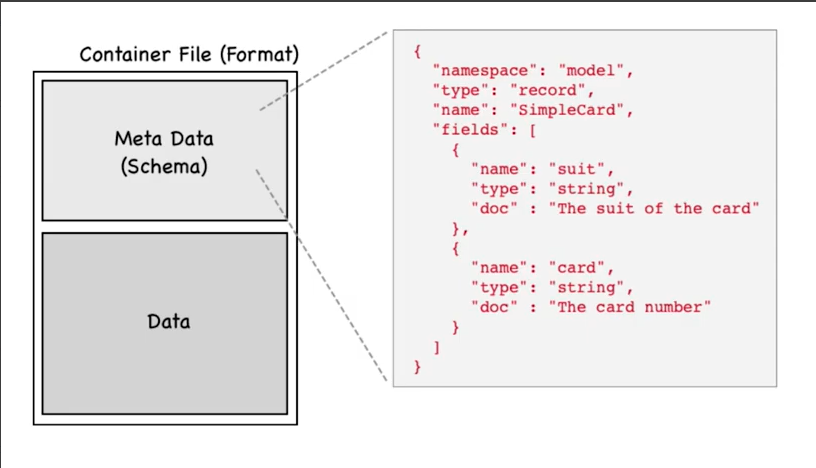
what schema is ?
A schema defines the structure of the data format. The Kafka topic name can be independent of the schema name. Schema Registry defines a scope in which schemas can evolve, and that scope is the subject
why schema registry:
-
if producer change the schema but consumer still consuming the data , it will has errors.
-
to reduce the disk space , if whole message (schema & data) persist on the disk , the disk used space will double increased .
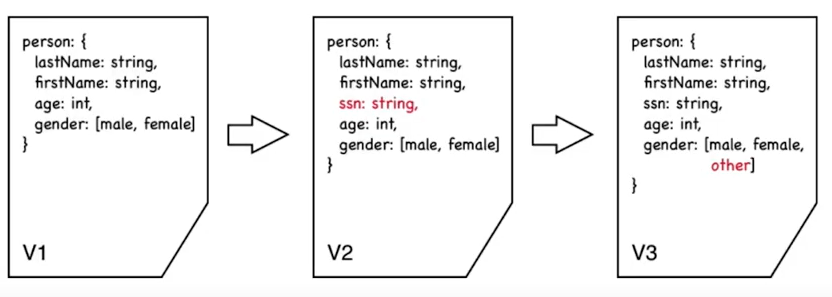
schema evolution process:
add filed or changing filed or remove filed process called schema evolution
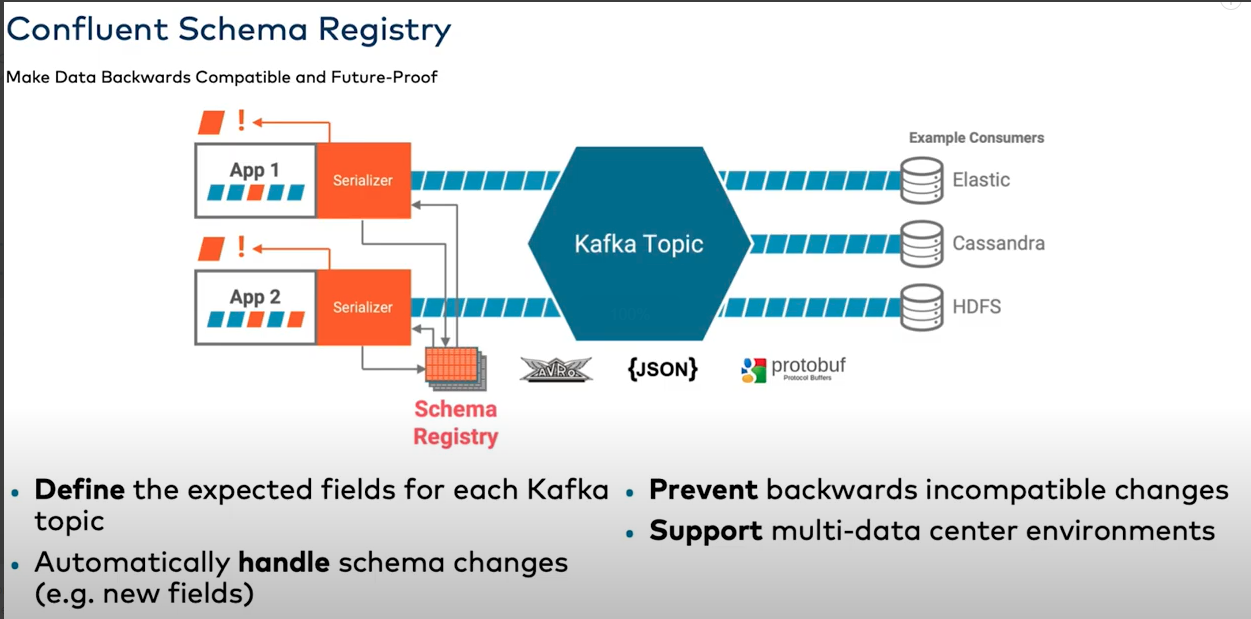

producer:
send data and message ID to kafka broker
send schema ID and definition to schema registry and schema registry will confirm that is not presents and check it compatible and cache locally .
consumer:
consume the data from kafka broker and get scheme ID, check if it's unknown schema ID then ask for schema registery to get full schema definition .
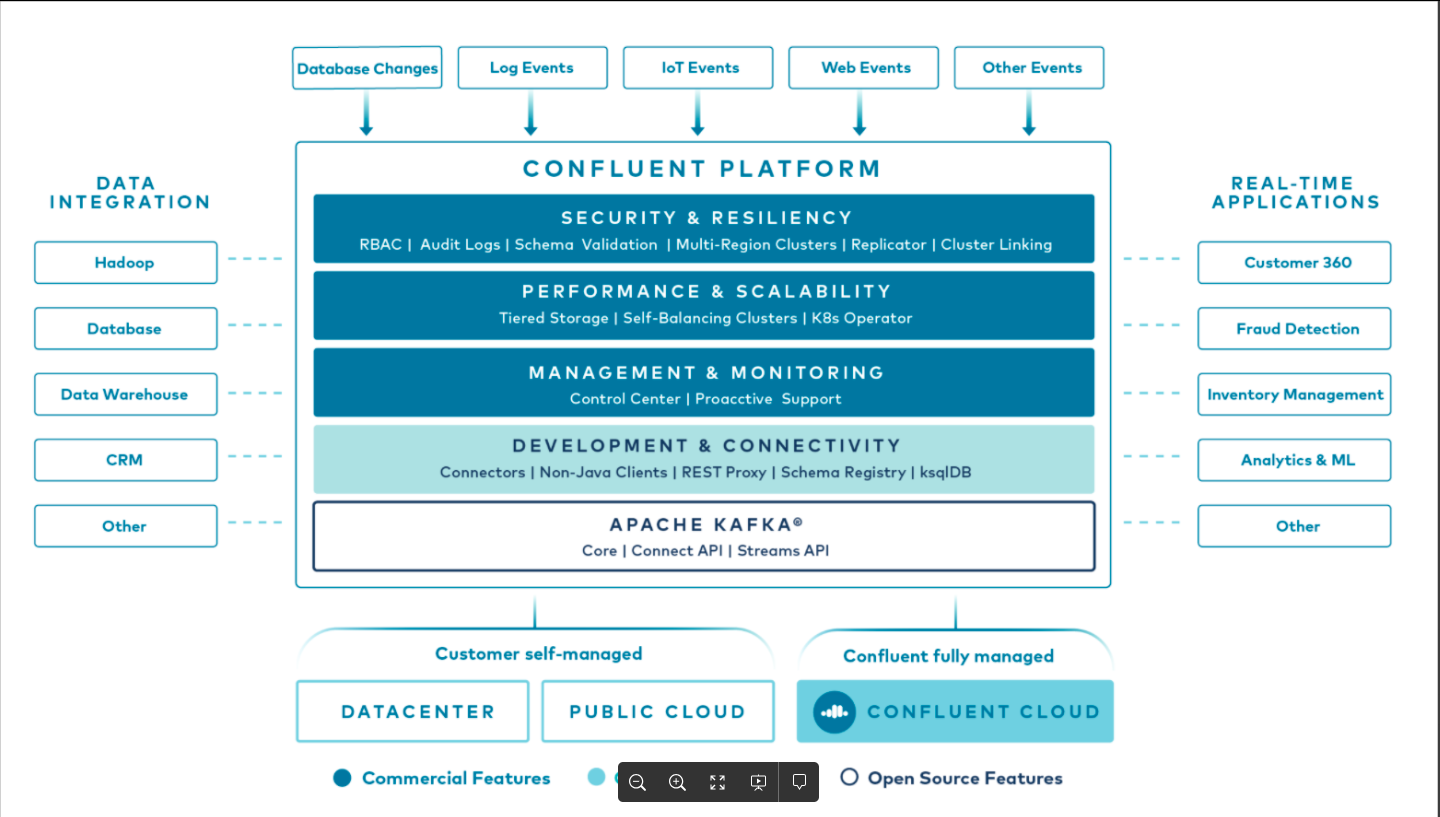
confluent platform