TCP超时与重传
TCP提供可靠的传输层。它使用的方法之一就是确认从另一端收到的数据。但数据和确认都有可能丢失。TCP通过在发送时设置一个定时器来解决这种问题。如果当定时器溢出时还没收到确认,他就重传数该数据。对任何实现而言,关键之处就在于超时和重传的策略,即怎样决定超时间隔和如何确定重传的频率。
TCP管理四个定时器:
1)重传定时器:使用于当希望接收到另一端的确认。本文将详细讨论这个定时器以及相关问题,如拥塞避免。
2)坚持(persist)定时器:使窗口信息保持不断流动,即使另一端关闭了其接受窗口。以后文章讨论。
3)保活(keep alive)定时器:检测一个空闲连接的另一端的状态(何时崩溃或重启)。以后文章讨论。
4)2MSL定时器:前面文章讲过了,即测量一个连接处在TIME_WAIT状态的时间。
往返时间测量-RTT
主要有两大类算法:加权移动平均算法(Karn/Partridge算法)和Jacobson / Karels 算法。其实我也不懂,尤其是后者。
拥塞避免算法(Congestion Avoidance)
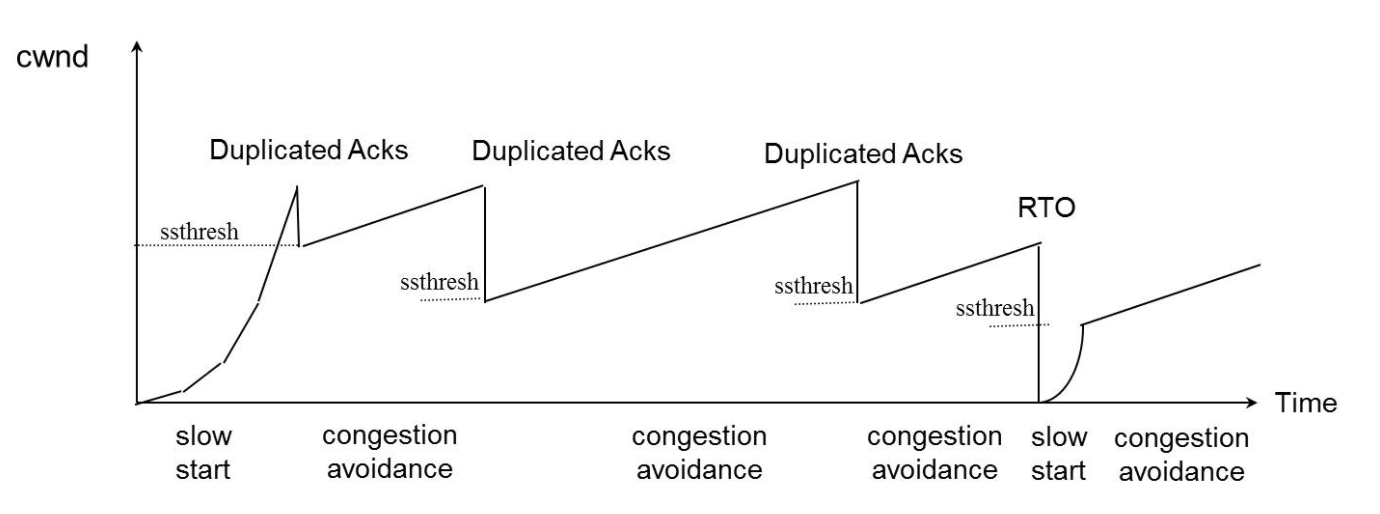
慢启动算法是一个在连接上发起数据流的算法(调节发送的数据速率),但是我们有时会达到中间路由器的极限,此时分组还是会被丢弃。拥塞避免算法是一种处理丢失分组的方法。但这两个算法通常一起实现,上一篇文章的慢启动示意图中也做了说明,cwnd指数增长期是慢启动,达到ssthresh后,每收到一个ACK,cwnd加一,进入线性增长(additive increase)。cwnd达到预设的cwnd后,慢启动又从1开始,只是这次的sshresh等于之前预设sshresh的一半。
快速重传(Fast Retransmit)和快速恢复(Fast Recover)算法
在收到一个失序的报文段时,TCP立即需要产生一个重复的ACK。这个ACK不应该被迟延。该ACK目的在于让对方知道收到一个失序的报文段,并告诉对方自己希望收到的序号。
但是我们知道一个重复的ACK有可能是一个丢包引起的,也有可能是一个失序报文段引起的。假如这是一些报文段的重新排序,则在重新排序的报文段被处理并产生一个新的ACK之前,只会产生1~2个重复ACK。如果收到一连串3个或3个以上的重复ACK,就非常可能是一个报文段丢失了。于是,发送方不需要等到超时定时器溢出,就重传丢失的报文数据段。这就是快速重传算法。快速重传做三件事情:
1)把ssthresh设置为cwnd的一半;
2)把cwnd设置为ssthresh的值(有些版本ssthresh+3);
3)重新进入拥塞避免阶段。
接下来执行的不是慢启动,而是拥塞避免算法。这就是快速恢复算法。为啥收到三个重复的ACK后没有启动慢启动算法?只有在有数据达到接收方时才会产生ACK,所以收到三个重复的ACK说明数据(非丢失数据)已经进入接收方的缓存,要是没有到达而丢包的话,会在RTO(retransmit timeout)之后发送ACK通知发送方报文丢失。也就是说连收三个ACK时,收发两端之间仍然有流动的数据,而我们不想执行慢启动算法来减少数据流。快速恢复做三件事情:
1)当收到3个重复ACK时,把ssthresh设置为cwnd的一半;把cwnd设置为ssthresh+3(因为有三个报文离开了网络),然后重传丢失的报文段。
2)再收到重复的ACK时,拥塞窗口cwnd++
3)当收到新的ACK时,把ssthresh值恢复到第一步的cwnd,因为收到新的ACK说明丢失的报文已经收到,快速恢复过程已经结束,可以恢复到之前的状态了。也即再次进入再次拥塞避免状态。
下图是各种算法的样子:
SACK(Selective acknowledgement)
以上被称为Reno拥塞控制算法,是针对一个包的重传算法,但是现实情况往往是同时有好多丢包。后来有了SACK确认机制,改变了TCP的确认机制。最初的ACK机制只确认当前已收到的连续数据段,SACK则把乱序等信息全都告诉对方,从而减少数据重传的盲目性。比如发送1,2,3,4,5,6,7个数据段,但只收到1,2,3,5,7。那么普通的ACK确认机制只会回复ACK=4,而SACK则把当前还收到5,7也放在了确认信息中,从而提高性能。使用SACK时NewReno算法可以不使用,因为SACK报文本身已经告诉发送方哪些报文需要重传,哪些不需要重传。关于SACK,wiki连接https://en.wikipedia.org/wiki/TCP_SACK

 浙公网安备 33010602011771号
浙公网安备 33010602011771号