01-scrapy框架
1.Scrapy图例:
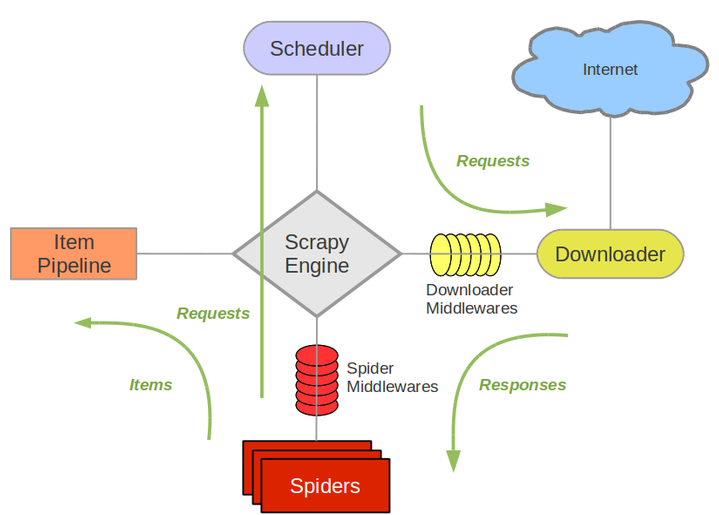
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
Downloader Middlewares(下载中间件):一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
************************上述内容是对scrapy框架的一个简单介绍,内容摘自网络****************************
*****************************************************************************************
*********************下述内容为scrapy命令信息,以及爬虫起送后的信息做一简单的整理和描述********************
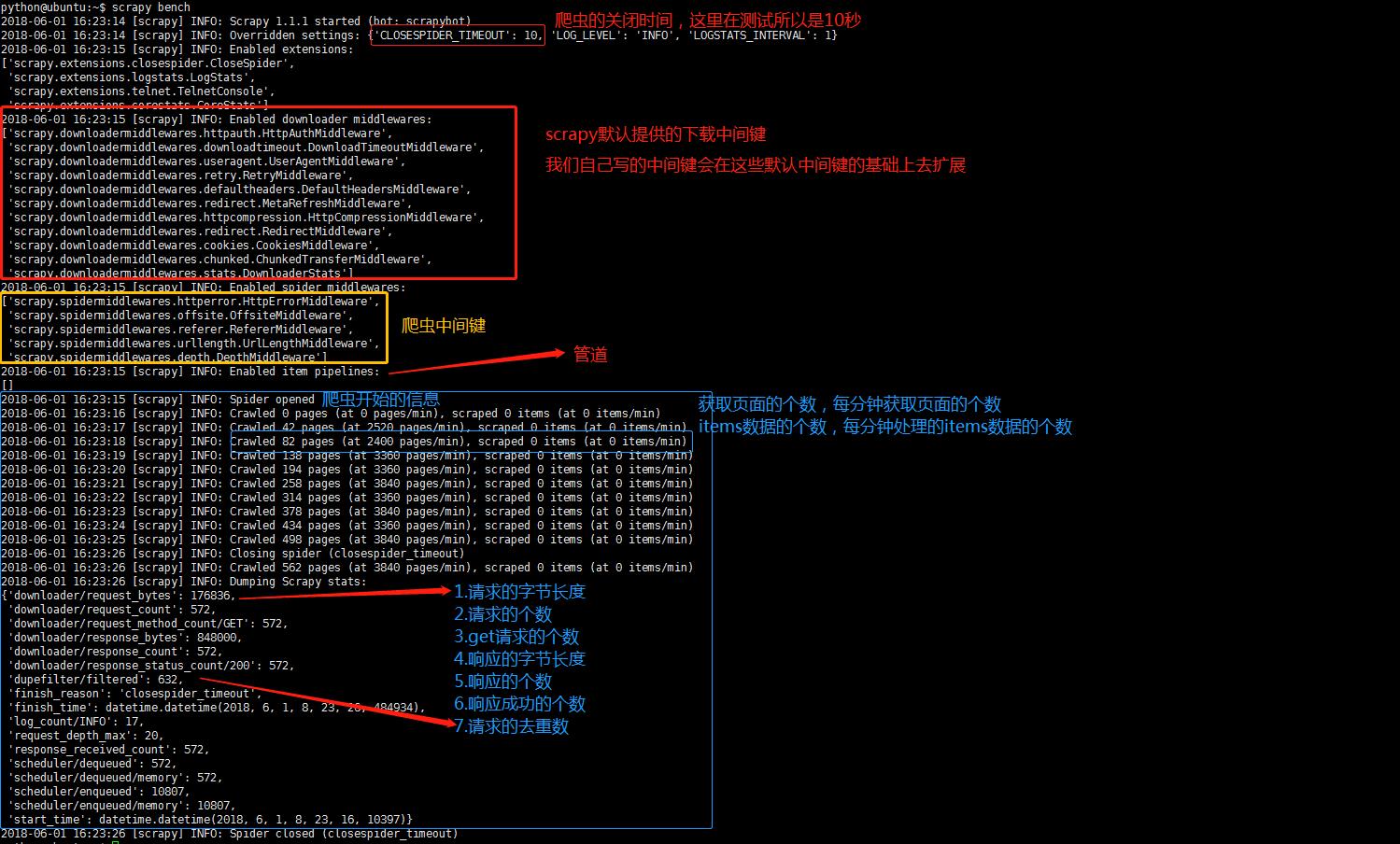
1、我们通过pip install scrapy安装好scrapy以后在终端键入scrapy,就会显示如下信息:
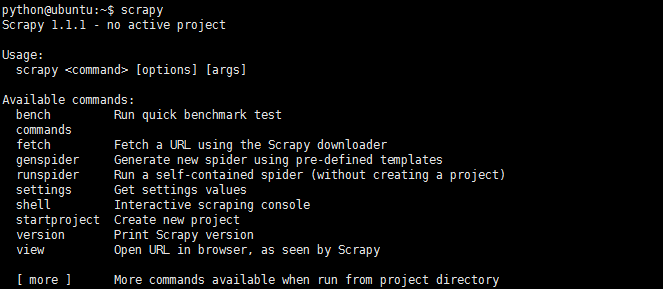
1).bench:快速测试当前硬件环境的性能,对于爬虫来说我们可以主要关注两个方面,一个是IO性能,一方面cpu的性能,IO主要取决于请求发送和相应的接收,cpu性能越强我们解析数据的速度就会越快
2).fetch:快速测试一个url地址是否能够使用,scrapy fetch 'http://www.baidu.com'
3).genspider:创建爬虫文件
4).runspider:运行爬虫
5).获取settings.py中某个字段的信息
6).shell终端界面,可用shell对我们设定的页面提取规则进行调试
以scrapy bench为例,展示一下爬虫启动后的预加载信息以及具体的爬虫信息