

scrapy项目2:爬取智联招聘的金融类高端岗位(spider类)
---恢复内容开始---
今天我们来爬取一下智联招聘上金融行业薪酬在50-100万的职位。
第一步:解析解析网页

当我们依次点击下边的索引页面是,发现url的规律如下:
第1页:http://www.highpin.cn/zhiwei/ci_180000_180100_as_50_100.html
第2页:http://www.highpin.cn/zhiwei/ci_180000_180100_as_50_100_p_2.html
第3页:http://www.highpin.cn/zhiwei/ci_180000_180100_as_50_100_p_3.html
看到第三页时,用我小学学的数据知识,我便已经找到了规律,哈哈,相信大家也是!
接下来说说我要爬取的目标吧:
如下图:我想要得到的是:职位名称、薪资范围、工作地点、发布时间
借助谷歌的xpath我就着手解析和提取这些数据了,这里不做分析,在代码中体现

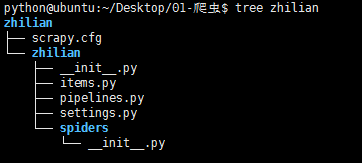
第二步:项目实现 通过 scrapy startproject zhilian创建项目,结构如下:
1. items.py
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # http://doc.scrapy.org/en/latest/topics/items.html import scrapy class ZhilianItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() # 职位 position = scrapy.Field() # 公司名称 company = scrapy.Field() # 薪资 salary = scrapy.Field() # 工作地点 place = scrapy.Field() # 发布时间 time = scrapy.Field()
2.爬虫文件:highpin.py 通过命令scrapy genspider highpin 'highpin.cn'创建
# -*- coding: utf-8 -*- import scrapy from zhilian.items import ZhilianItem class HighpinSpider(scrapy.Spider): # 爬虫名,创建文件时给定 name = "highpin" allowed_domains = ["highpin.cn"] url = 'http://www.highpin.cn/zhiwei/ci_180000_180100_as_50_100' # 用于构造url的参数 offset = 1 start_urls = [url + '.html'] def parse(self, response): # 用xpath对网页内容进行解析,返回的是一个选择器列表 position_list = response.xpath('//div[@class="c-list-box"]/div/div[@class="clearfix"]') item = ZhilianItem() print '------------------------------' print len(position_list) print '-----------------------------------' for pos in position_list: # 这里的item对应于items.py文件中的字段 item['position'] = pos.xpath('./div/p[@class="jobname clearfix"]/a/text()').extract()[0] item['company'] = pos.xpath('./div/p[@class="companyname"]/a/text()').extract()[0] item['salary'] = pos.xpath('./div/p[@class="s-salary"]/text()').extract()[0] item['place'] = pos.xpath('./div/p[@class="s-place"]/text()').extract()[0] item['time'] = pos.xpath('./div[@class="c-list-search c-wid122 line-h44"]/text()').extract()[0] yield item if self.offset < 150: self.offset += 1 # 构建下一个要爬取的url url = self.url + '_p_' + str(self.offset) + '.html' print url # 发送请求,并调用parse进行数据的解析处理 yield scrapy.Request(url,callback=self.parse)
3.pipelines.py管道文件用于将数据存于本地
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html import json class ZhilianPipeline(object): def __init__(self): # 初始化是创建本地文件 self.filename = open('position.json','w') def process_item(self, item, spider): 将python数据通过dumps转换成json数据 text = json.dumps(dict(item),ensure_ascii=False) + '\n' # 将数据写入文件 self.filename.write(text.encode('utf-8')) return item def close_spider(self,spider): # 关闭文件 self.filename.close()
4.settings.py文件
说明1:在settings.py中首先要配置管道文件,如下图:

说明2:USER_AGENT,起初我在settings中所使用的user-agent为:Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Mobile Safari/537.36
运行爬虫后,如下图:

如上图所示,服务器对我要访问的url做了重定向,复制重定向后的url到浏览器如下图:
显然,这个页面并没有我们想要的信息,这就是一种反扒策略
为了解决这个问题,我就试着将USER_AGENT 更换为:Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.

再次通过 scrapy crawl highpin启动爬虫,发现爬虫程序已可以正常爬取
5.启动爬虫 命令:scrapy crawl highpin

数据文件内容

---恢复内容结束---
