后缀数组(SA)学习笔记
后缀数组是一个很强的字符串算法,可以解决众多有关子串的问题。
定义
已知一个字符串 ,那么定义 表示 形成的后缀。
表示把这些后缀按字典序排序后,排名第 的串的起始下标。
表示把排序后 的排名,可以发现 。
表示 的最长公共前缀长度。
表示 ,也就是排序后相邻两个串的 。
求法
- 做法
直接暴力快拍,不讲。
- 做法。
这里要用倍增的思想,考虑枚举一个 ,然后把 重新定义为 构成的字符串,那么每次 乘 ,比较两个字符串时只需要拆成两个字符串比较即可。
给个经典图:
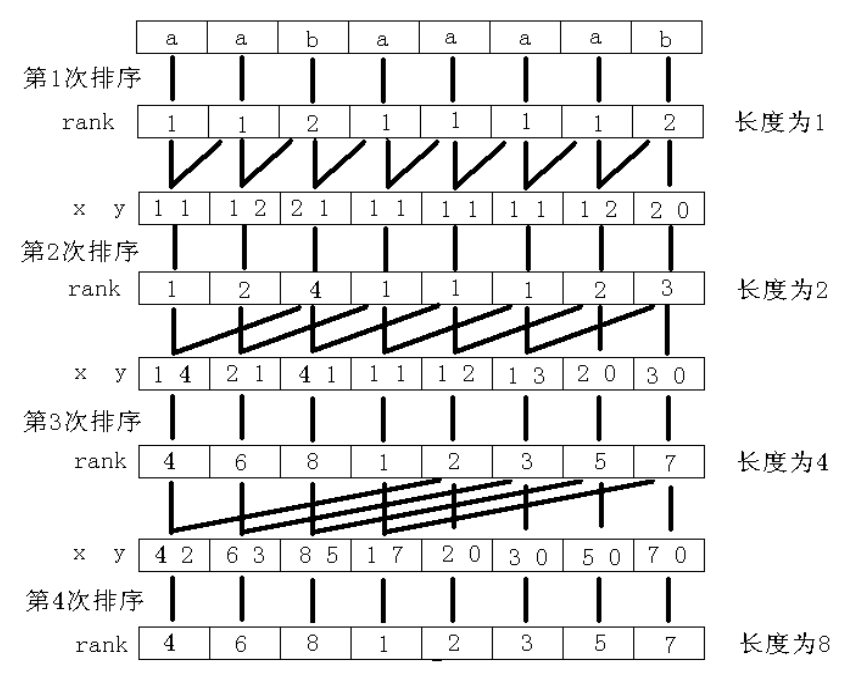
直接快排就是 的了。
考虑优化,这个东西本质上是一个双关键字排序,因此可以直接采用基数排序。
先第二关键词排序,然后第一关键字排序即可,注意需要用稳定排序,复杂度
const int N=1e6+5;
struct SA{
void get_sa(int n,int m){//长度为 n,值域为 [1,m]
m=max(n,m);for(int i=1;i<=n;i++)cnt[rk[i]=a[i]]++;//开始时排名为a[i],开桶直接统计出现多少次
for(int i=1;i<=m;i++)cnt[i]+=cnt[i-1];
for(int i=n;i;i--)sa[cnt[rk[i]]--]=i;//从大到小做,相对顺序不变
for(int w=1;w<n;w*=2){//倍增枚举长度
memset(cnt,0,sizeof(cnt));int t=0;
for(int i=n;i>n-w;i--)id[++t]=i;//这里以第二关键字排序,也就是按 rk[i+w] 排序,排序结果是 id[i]
for(int i=1;i<=n;i++)if(sa[i]>w)id[++t]=sa[i]-w;
for(int i=1;i<=n;i++)cnt[rk[i]]++;//然后按第一关键字排序,注意要使用 id[i] 保持顺序
for(int i=1;i<=m;i++)cnt[i]+=cnt[i-1];
for(int i=n;i;i--)sa[cnt[rk[id[i]]]--]=id[i];
t=0;memcpy(tmp,rk,sizeof(rk));
for(int i=1;i<=n;i++)if(tmp[sa[i]]==tmp[sa[i-1]]&&tmp[sa[i]+w]==tmp[sa[i-1]+w])rk[sa[i]]=t;else rk[sa[i]]=++t;//相同的 rk 取值一样
}
}
int a[N],cnt[N],tmp[N],rk[N],sa[N],id[N];
};
然后考虑 怎么求。
首先是一个引理:
这个证明就是考虑 和 它匹配的串,假设 为 ,这里 是一个字母, 是一个字符串,也就是 这样的形式,与其匹配的串就是 的形式。
那么考虑 ,那么与 匹配的也至少会有一个 的后缀,显然这个也会排在 的前面,又由于是按字典序排序,因此至少也会有一个 的 ,上面的得证。
那么求法也很简单,直接枚举 ,转移前面的答案,然后暴力向后看是否能扩展,复杂度容易证明为 。
for(int i=1,t=0;i<=n;i++){
if(t)t--;
while(a[i+t]==a[sa[rk[i]-1]+t])t++;
h[rk[i]]=t;
}
应用
- 查询一个串作为子串出现的位置
既然是子串,那么一定作为一个后缀的前缀出现,又因为已经按照字典序排序了,所以可以直接二分一下暴力判,单次复杂度 ,劣于 SAM。
- 查询一个串作为子串出现次数
可以发现在后缀数组上一定是一个区间,所以可以直接二分左右端点即可,同样劣于 SAM。
- 询问两个后缀的
有一个简单的二分 + hash 做法,复杂度 。
这个也比较简单,考虑以前缀方式出现的一定是一个区间,因此就相当于相邻两个做然后取 即可,也就是对区间 求 ,用 st 表,复杂度
- 不同子串个数,P2408
考虑一个串在那些地方会重复出现,显然是作为前缀出现,那么就是在一个区间中,因此直接考虑每个后缀与前面一个重复的前缀数即可。
所以答案就是 。
已知一个字符串 ,求所有出现次数至少为 的子串的长度最大值。
。
ez 题,直接考虑一个子串一定是一个区间的前缀,那么直接对于所有长度为 的区间求最小值然后找最大即可。
已知一个串 ,求有多少个子串可以表示为
AABB的形式。。
首先有一个很简单的 hash 暴力做法,复杂度 ,有 ,流汗黄豆。
考虑记录 表示 结尾的形如 AA 的串的个数,那么可以只需要倒着再做一遍两边合并就可以得到答案。
但是这个东西不会做。
正解很牛,考虑枚举 AA 串中 A 的长度为 ,然后每 个点中标记最后一个点,这样可以发现所有选子串方案一定经过两个被标记的点。
画一下图
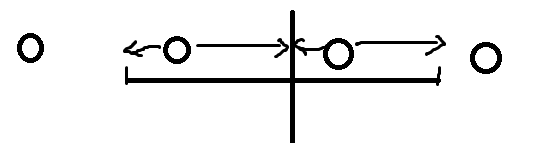
圆就是标记点,竖线是 AA 的中点,可以发现圆点向左的箭头两个子串相等,向右的也一样。
因此就是求公共前缀和公共后缀,然后算一下合法的方案,那么就是区间加即可。
有一个长度为 的串,每次可以开头取一个或者结尾取一个,求拼成的字典序最小的字符串。
。
考虑如果左右不相等显然直接取小的,但如果相等呢。
考虑对比 ,那么就是 与 翻转的结果比较字典序,也就是 与 翻转后的结果一起进行后缀排序。
考虑两个串怎么一起搞,简单的做法是接在后面,中间放一个特殊字符即可。
题比较长,自己看吧。
简单题,考虑上面 是区间的那个东西,因此相当于 递减,就是连一些边,答案直接用并查集维护即可,我用了暴力启发式合并。
已知一个串 ,求对于所有 ,求 。
。
相当于只需要算后面那个东西,也就是区间 求和,这个东西可以用单调栈简单维护即可。
ABC268Ex *2560
有一个字符串 ,求最少把多少个字符变成
*,使得 都没有在 中出现过。
简单题,考虑一个 出现的所有位置,这些位置对应着一个个区间,相当于区间中至少选一个,因此直接考虑设 表示以 为左端点,右端点最小是多少,然后就有 个区间直接贪心即可,求这个 可以直接建 SA,相当于只在一个区间中出现,那么直接线段树维护即可。
更加简单的做法是考虑每个区间一定贪心向后选,因此直接 AC 自动机,匹配上了就把最后一个改掉就可以了。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通