分析ajax爬取今日头条街拍美图
一、什么是ajax
AJAX 指异步 JavaScript 及 XML(Asynchronous JavaScript And XML)
ajax不是一门编程语言,而是利用Javascript在保证页面不被刷新,页面链接不改变的情况下与服务器交换数据并更新部分网页的技术
二、抓取分析
打开今日头条,并搜索街拍
网址:https://www.toutiao.com/search/?keyword=%E8%A1%97%E6%8B%8D
切换到 network-->XHR 可以看到红笔圈出的:x-requested-with:XMLHttpRequest
可判断为ajax请求
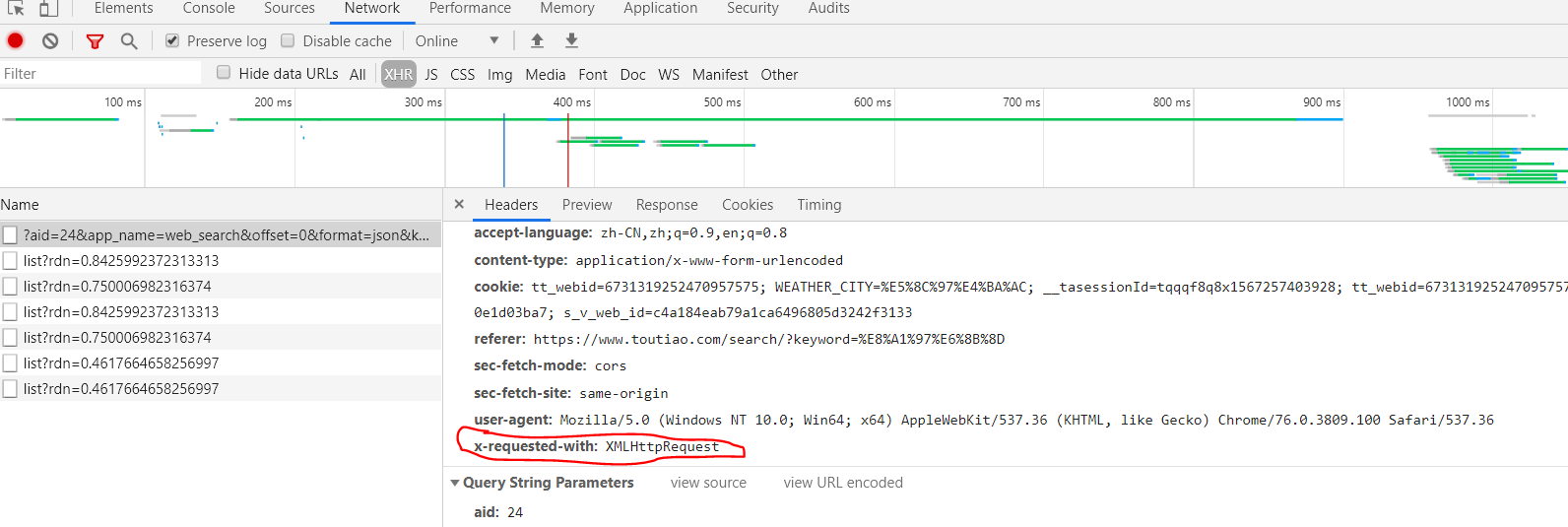
切换到preview从data中获得图片地址等信息,每条都是一一对应的
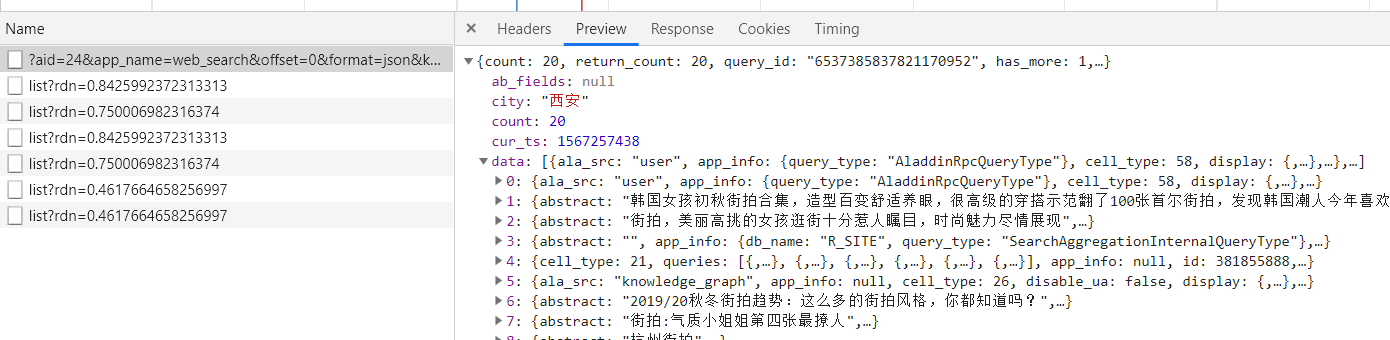
再切换到headers,可以看到请求地址的各个参数
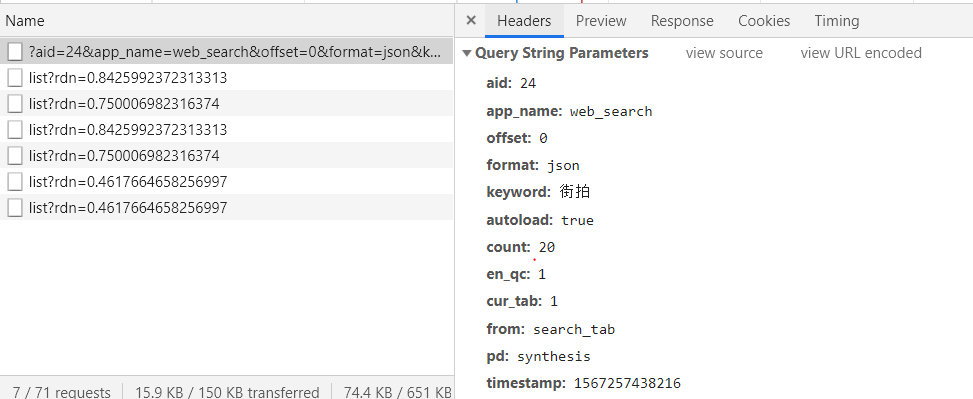
不断往下拉,发现变化的参数只有offset,每次加载一次加十
三、开始爬取
1、get_page(offset)请求页面函数:发送请求,将获得response利用json()方法转化为JSON格式,然后返回
2、get_image(json)解析函数:提取每一张图片链接,将图片链接和图片所属的标题一起返回,此时可以构造一个生成器
3、save_image(item)保存文件函数:根据item的title创建文件夹,将获得的图片以二进制的形式写入文件,图片文件名用MD5值,可以去重
4、主函数:构造一个offset数组,遍历offset,提取图片链接,并将其下载即可
1 import requestsget 2 from urllib.parse import urlencode 3 4 def get_page(offset): 5 headers = { 6 'x-requested-with': 'XMLHttpRequest', 7 'user - agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36', 8 'referer':'https://www.toutiao.com/search/?keyword=%E8%A1%97%E6%8B%8D', 9 'cookie':'__tasessionId=ma7hh1k0i1564919983167; csrftoken=a2318e2879cb7daac5e3169ac6731316; tt_webid=6721280117165032963; UM_distinctid=16c5c7fee055e9-09bb3e770de9ee-7a1437-144000-16c5c7fee0685f; CNZZDATA1259612802=745403741-1564916538-%7C1564916538; s_v_web_id=7a3ff2239d94842e143caf217478bc62' 10 } 11 params = { 12 'aid': '24', 13 'app_name': 'web_search', 14 'offset': offset, 15 'format': 'json', 16 'keyword': '街拍', 17 'autoload': 'true', 18 'count': '20', 19 'en_qc': '1', 20 'cur_tab': '1', 21 'from': 'search_tab', 22 'pd': 'synthesis', 23 } 24 base_url = 'https://www.toutiao.com/api/search/content/?' 25 url = base_url + urlencode(params) 26 try: 27 response = requests.get(url,headers=headers) 28 if response.status_code == 200: 29 return response.json() 30 except requests.ConnectionError as e: 31 return None 32 33 def get_image(json): 34 if json.get('data'): 35 for item in json.get('data'): 36 title = item.get('title') 37 images = item.get('image_list') 38 for image in images: 39 yield { 40 'image':image.get('url'), 41 'title':title 42 } 43 44 import os 45 from hashlib import md5 46 47 def save_image(item): 48 if not os.path.exists(item.get('title')): 49 os.mkdir(item.get('title')) 50 try: 51 response = requests.get(item.get('image')) 52 if response.status_code == 200: 53 file_path = '{0}/{1}.{2}'.format(item.get('title'),md5(response.content).hexdgest(),'jpg') 54 if not os.path.exists(file_path): 55 with open(file_path,'wb') as f: 56 f.write(response.content) 57 else: 58 print('Already Downloaded',file_path) 59 except Exception as e: 60 print('Failed to Save Image') 61 62 from multiprocessing.pool import Pool 63 64 def main(offset): 65 json = get_page(offset) 66 for item in get_image(json): 67 print(item) 68 save_image(item) 69 70 GROUP_START = 1 71 GROUP_END = 20 72 73 if __name__ == '__main__': 74 pool = Pool() 75 groups = ([x * 20 for x in range(GROUP_START,GROUP_END + 1)]) 76 pool.map(main,groups) 77 pool.close() 78 pool.join()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号