MySQL索引
什么是索引?索引类似于清华字典上的拼音查找页和部首查找页,通过索引我们能够快速的定位到需要查找的汉字。而索引实际上也是一张表,只不过这张表记录了key以及定位记录的字段。
MySQL通过索引能够快速的找到相关的数据,而如果没有索引,MySQL只能通过全表扫描查询数据,这回带来非常大的开销。
那么MySQL如何使用索引呢?
主要包含以下情况:
- 查找符合Where条件的数据。
- 当有多个索引可以选择时,MySQL选择其中索引选择性最高的索引。
- 当表具备复合索引时,MySQL遵循最左匹配原则,使用索引进行数据的检索。
- 当存在join操作从其他表查找数据时,MySQL可以使用声明相同类型和相同大小的字段上的索引进行查找。
- 当使用MIN和MAX操作时,MySQL使用单一的索引去查找MIN或MAX
- 排序或分组时,如果被排序或分组的字段复合最左匹配原则或者是一个可使用的索引时。
- 当查询结果不需要查找原始记录时(索引覆盖)。
MySQL索引结构
大部分MySQL索引,包括主键索引、普通索引、唯一索引以及全文索引使用B+树存储。空间数据使用R树作为索引,MERMORY存储引擎同时支持使用Hash索引。InnoDB使用倒排索实现全文索引。
B+树
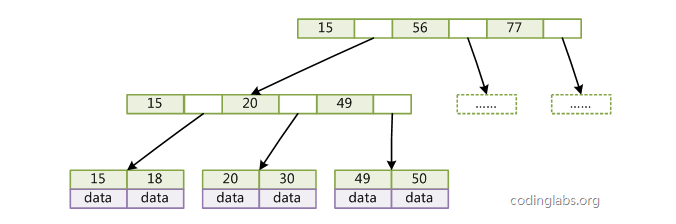
InnoDB存储引擎B+树的实现方式
MyIsam存储引擎B+树的实现方式
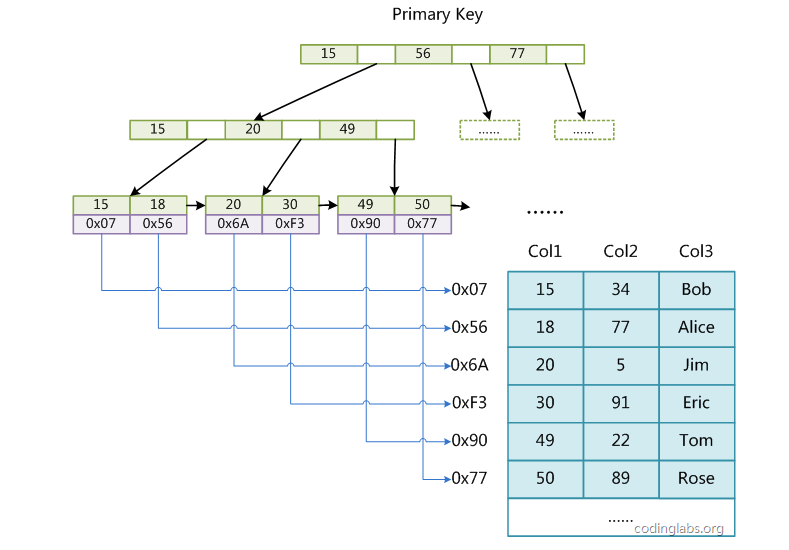
可以看到InnoDB对于主键索引采用的是聚簇索引形式的存储方式,而MyIsam对主键索引则是非聚簇索引形式。
基本概念
- 主键索引: 基于主键建立的B+树索引,对于InnoDB而言,如果没有符合的key则以6字节rowid为主键建立索引
- 二级索引(辅助索引): 除主键以外的索引,与主键索引不同二级索引的叶子节点并不存储数据而是主键索引对应的值
- 回表: 在InnoDB下,使用辅助索引进行查询,由于数据与索引存储在一起,因此实际上辅助索引所构建的B+树,记录的是主键的值,需要再通过主键的B+树进一步查询所需要的数据。
- 当数据量很少的时候,如果通过辅助索引进行查找的话,时间效率可能不如全表扫描,因为发生了回表。
- 索引覆盖: 当查询的数据恰好是二级索引存储的主键值时,并不需要通过主键的B+树搜索原数据。
- 索引下推: 与谓词下推类似,在磁盘上进行数据筛选,由于数据是排序并且是聚集存放的,所以性能并不会太受影响,但是大大降低了磁盘IO反而提升性能。
- 最左匹配: 索引建在复合字段上,形如(a,b,c)联合索引的 b+ 树,其中的非叶子节点存储的是第一个关键字的索引 a,而叶子节点存储的是三个关键字的数据。这里可以看出 a 是有序的,而 b,c 都是无序的。但是当在 a 相同的时候,b 是有序的,b 相同的时候,c 又是有序的。
- 例如:联合索引(name,age)
- where name = "asda" and age = 10 匹配到name使用索引
- where name = "asda" 匹配到name使用索引
- where age = 10 不适用索引
- where age = 10 and name = "asda" MySQL优化后 等价于1,使用索引
- 例如:联合索引(name,age)
- MRR(Multi-range-read): 当在辅助索引上进行范围查找时会产生大量随机IO,MySQL通过收集辅助索引对应主键rowid。进行排序后回表查询,随机IO转顺序IO。
- 我们知道InnoDB中叶子节点数据是按照PRIMARY KEY(ROWID)进行顺序排列的,所以我们可以认为,如果按照主键的递增顺序查询的话,对磁盘的读比较接近顺序读,能够提升读性能。这对于IO-bound类型的SQL查询语句带来性能极大的提升
- FIC(fast index creation): 针对辅助索引,创建和删除辅助索引不在需要拷贝整个表的数据。
- 创建一个新的、空的临时表,表结构为使用alter table定义的新结构
- 逐一拷贝数据到新表,插入数据行同时更新索引
- 删除原表
- 将新表的名字改为原表的名字
- 对当前表添加了share锁,读取数据时不会出现问题,但对于DML操作会出现。
- 当删除主键的时候,所有的辅助索引都会被重建。当删除辅助索引时,只会更新内部系统表和MySQL字典。
- 前缀索引: 前缀索引是用列的一部分字符去建立索引,更加节省空间(因为只使用一部分字符,索引建立时长度会降低),选择合适的话,效率也会更高
- 索引的选择性: 索引的选择性,指的是不重复的索引值和表记录数的比值。选择性是索引筛选能力的一个指标。索引的取值范围是 0—1 ,当选择性越大,索引价值也就越大。
索引失效
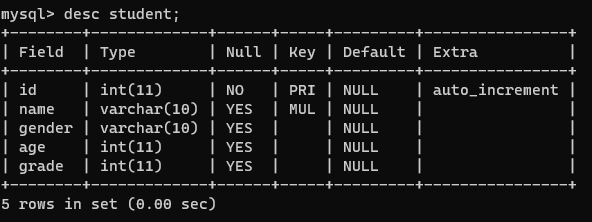
student表格属性如下:
-
不符合最左匹配

联合索引(name,gender,grade),使用不符合最左匹配的查询语句发现并没有使用索引。
-
模糊查询:错误使用模糊查询可能会导致索引失效。
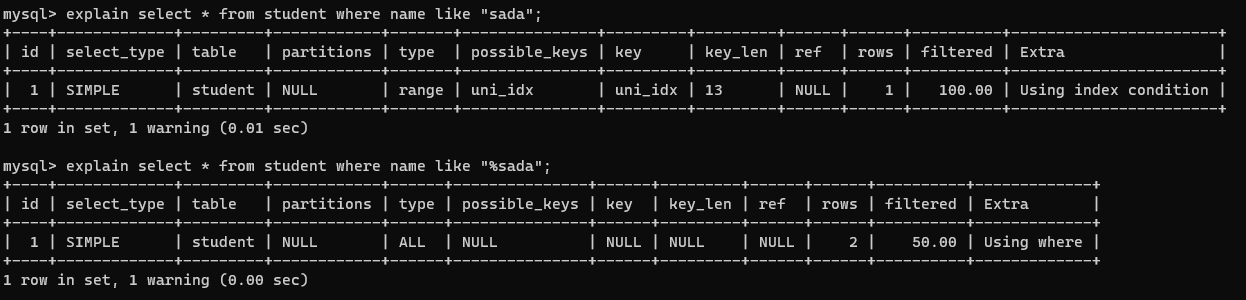
可以发现当 % 位于模糊查询的开头时会出现索引失效。 -
运算符:
- Or
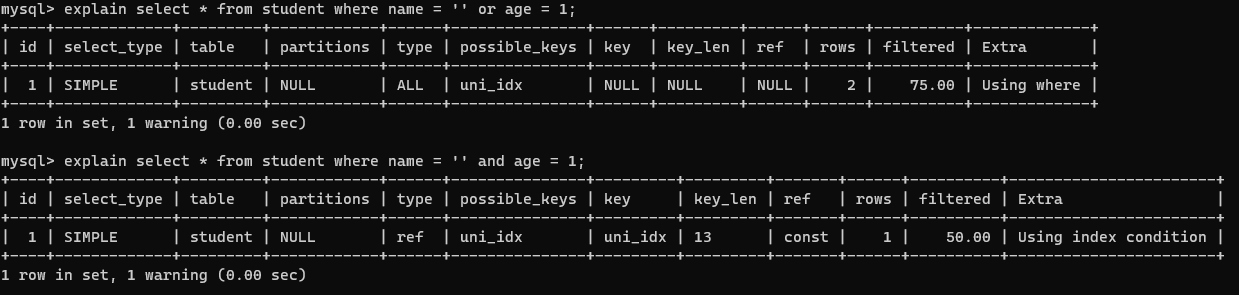
- 算术运算符(+、-,*、/、>、<、!=)

- Not In、Not Exists
- Is Null、Is Not Null
- Or
-
类型不一致:当类型不一致或者存在隐式类型转换时,索引会失效
- name的类型为varchar,发生了隐式类型准换,索引失效。

- student2表中的name类型为int,发现索引失效,而改成与student表中name相同的属性后,成功使用索引。
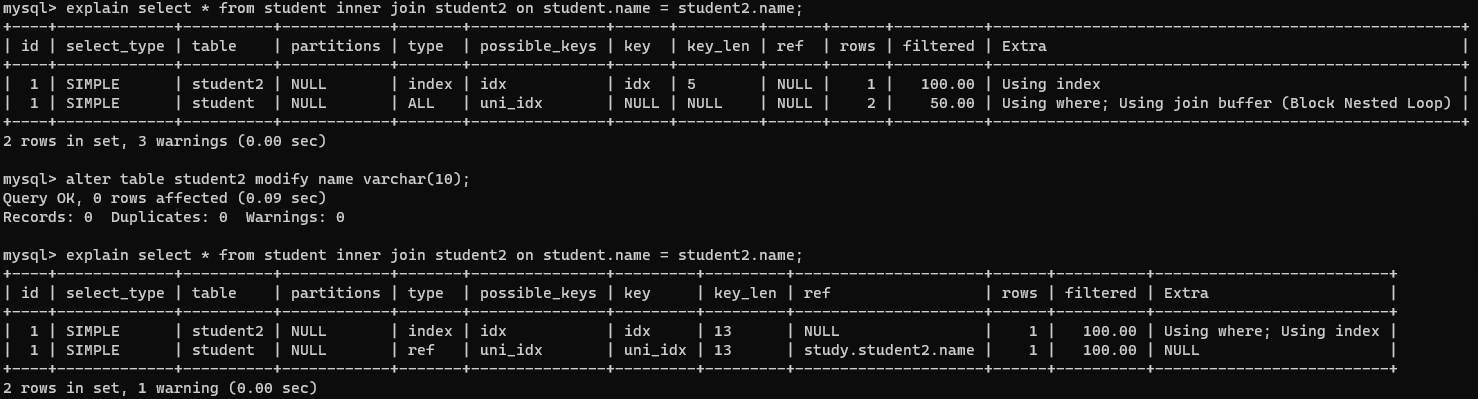
- name的类型为varchar,发生了隐式类型准换,索引失效。
-
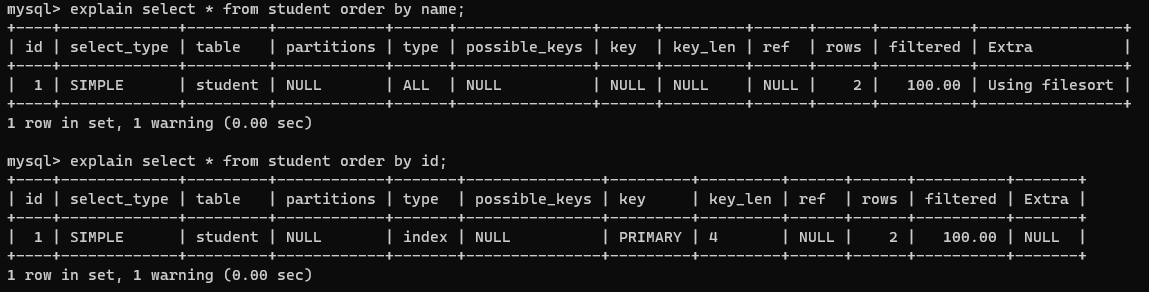
Order By
order by条件满足最左匹配可能会走索引(与MySQL的版本有关),主键order by可以正常走索引。
查询计划
具体参考官网
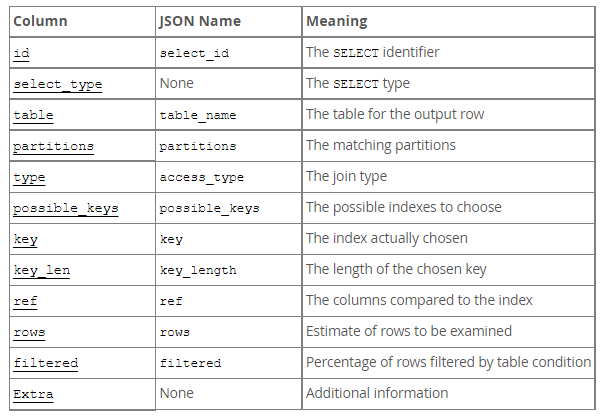
主要关注extra属性,该属性解释了MySQL如何解析查询语句。如果想要查询尽可能快的话,要避免出现Using filesort和Using temporary。
对于具体的信息(参考链接):
- Distinct:MySQL 发现第 1 个匹配行后,停止为当前的行组合搜索更多的行。
- Not exists:MySQL 能够对查询进行 LEFT JOIN 优化,发现1个匹配 LEFT JOIN 标准的行后,不再为前面的的行组合在该表内检查更多的行。
- range checked for each record:MySQL 没有发现好的可以使用的索引,但发现如果来自前面的表的列值已知。可能部分索引可以使用。
- Using filesort:看到这个的时候,查询就需要优化了。MySQL 需要进行额外的步骤来发现如何对返回的行排序。它根据连接类型以及存储排序键值和匹配条件的全部行的行指针来排序全部行。
- Using index:从只使用索引树中的信息而不需要进一步搜索读取实际的行来检索表中的列信息。
- Using temporary:为了解决查询,MySQL 需要创建一个临时表来容纳结果。看到这个就需要进行优化了,这通常发生在对不同的列集进行 order by 上,而不是 group by 上。
- Using where:WHERE 子句用于限制哪一个行匹配下一个表或发送到客户。
- Using sort_union| Using union|Using intersect:这些函数说明如何为 index_merge 联接类型合并索引扫描。
- Using index for group-by:类似于访问表的 Using index 方式,Using index for group-by 表示 MySQL 发现了一个索引,可以用来查询 GROUP BY 或 DISTINCT 查询的所有列,而不要额外搜索硬盘访问实际的表。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号