8.5 高速缓存的工作原理
计算机组成
8 存储层次结构
8.5 高速缓存的工作原理

因为CPU的速度和内存的速度差距越来越大,计算机整体系统的性能,就受到了巨大的影响。而高速缓存技术的出现,则挽救了这个局面。
那在这一节,我们就来看一看高速缓存是如何工作的。
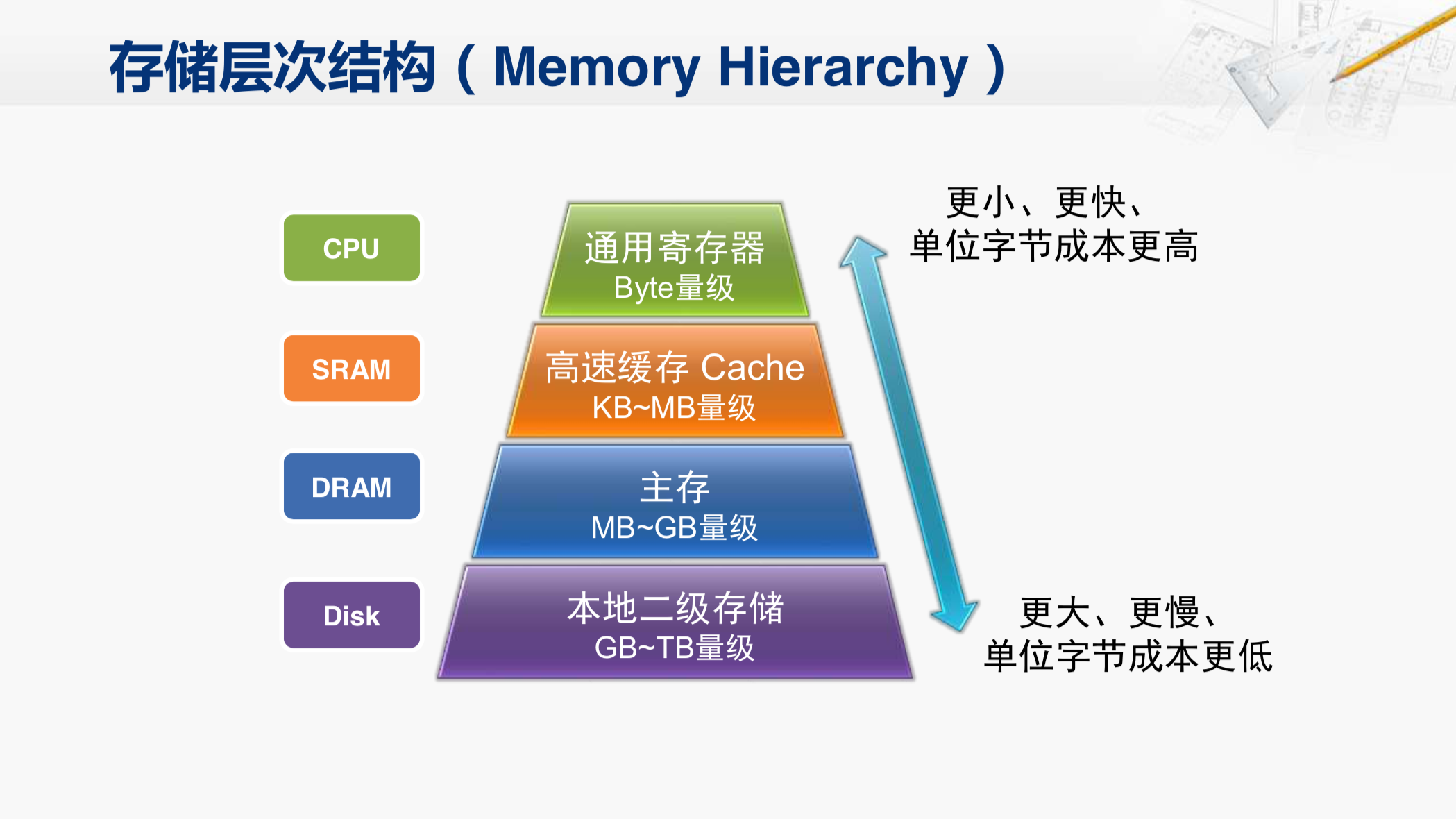
这是计算机的存储层次结构。高速缓存,也就是Cache位于CPU和主存之间。相比于主存,它的容量要小的多,但是速度也快很多。
为什么在CPU和主存之间,增加这么一个速度很快,但是容量很小的存储部件,就可以提升整个计算机系统的性能呢?这就要得益于计算机中运行程序的一个特点,这个特点被称为程序的局部性原理。
我们通过一个例子来进行说明。
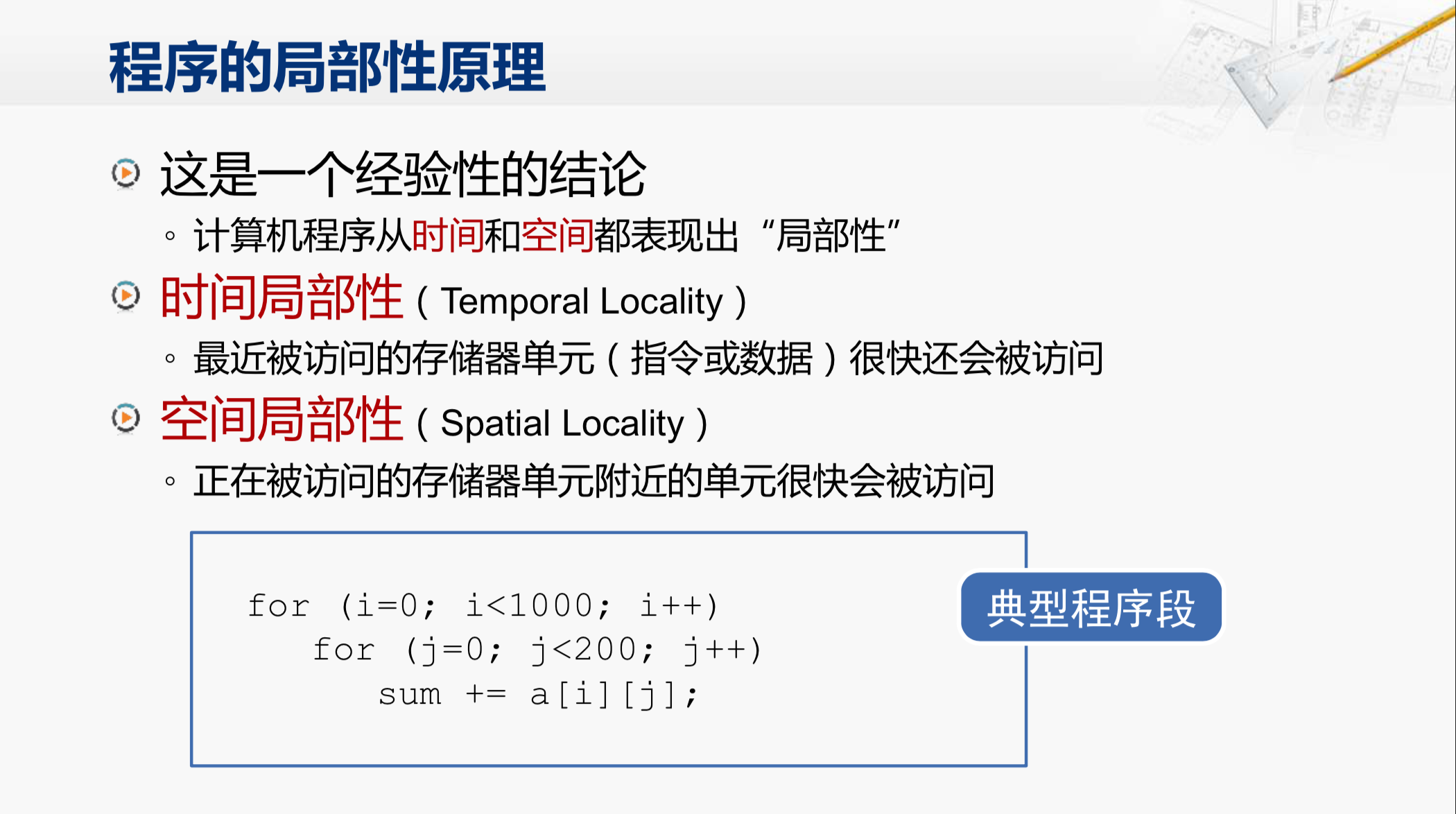
这是一段很常见的程序,有两层循环。对一个二维数组进行累加,如果sum这个变量是保存在内存中的,那它所在的这个存储单元就会不断的被访问,这就称为时间局部性。这些对循环变量进行判断和对循环变量进行递增的指令,也都会被反复执行。而另一点,叫作空间局部性,指的是正在被访问的存储器单元附近的那些数据,也很快会被访问到。
那么就来看这个数组。它在内存当中是连续存放的,从 \(a_{[0][0]}\) \(a_{[0][1]}\) \(a_{[0][2]}\) \(a_{[0][3]}\) ... ... 这样一个接一个的存放下去。那么在这段循环访问它的时候,访问了 \(a_{[0][0]}\) 之后,很快就会访问 \(a_{[0][1]}\),然后很快会访问 \(a_{[0][2]}\),这样的特征就被称为空间局部性。
Cache就是利用了程序的局部性原理,而设计出来的。
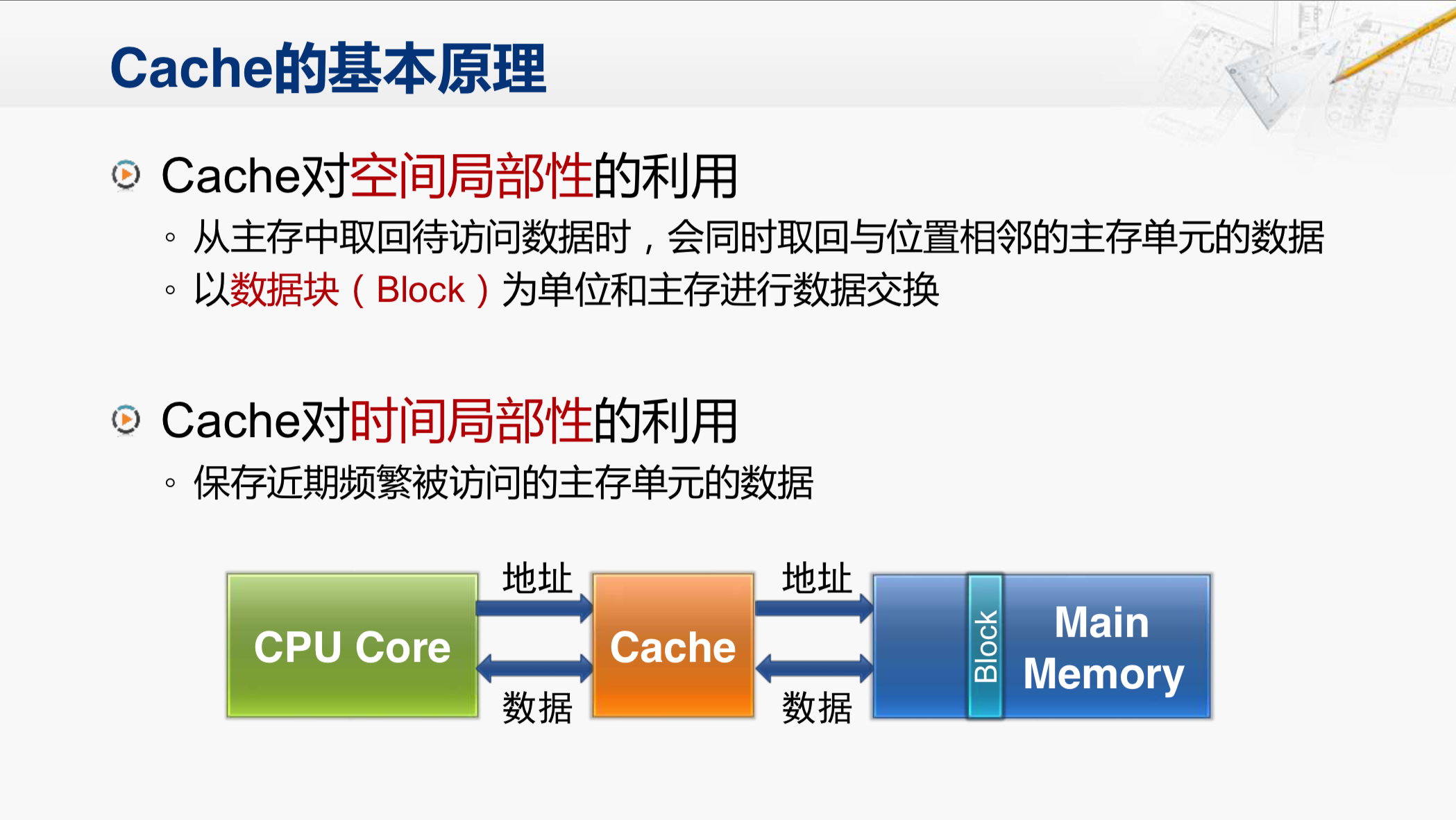
首先,我们来看Cache对空间局部性的利用。当CPU要访问主存时,实际上是把地址发给了Cache,最开始,Cache里面是没有数据的。所以,Cache会把地址再发给主存,然后从主存中取得对应的数据,但Cache并不会只取回CPU当前需要的那个数据,而是会把与这个数据位置相邻的主存单元里的数据一并取回来,这些数据就称为一个数据块。那么Cache会从主存里,取回这么一个数据块,存放在自己内部。然后,再选出CPU需要的那个数据送出去,那过一会儿,CPU很可能就会需要刚才那个数据附近的其它数据,这时候,这些数据已经在Cache当中了,就可以很快的返回,从而提升了访存的性能。第二种情况,是Cache对时间局部性的利用。因为这个数据块暂时会保存在Cache当中,CPU如果要再次用到刚才用过的那个存储单元,Cache也可以很快的提供这个单元的数据,这就是Cache对程序局部性的利用。
我们要注意,这些操作都是由硬件完成的。对于软件编程人员来说,他编写的程序代码当中,只是访问了主存当中的某个地址,而并不知道这个地址对应的存储单元到底是放在主存当中,还是在Cache当中。
如果这个不太好理解的话,那我来打个比方。我们可以把主存看作一个图书馆,里面可能有几千万册的藏书。CPU就像一个来借书的人,他给出了一个书号,希望借到这本书。管理员可能要花几个小时,才能找到这本书,拿出来交给借书的人。过一会儿,借书的人把这本书还了以后,管理员又把它放回到仓库当中去。再过一会儿,这个人又要借这本书,管理人员又要花几个小时,从仓库里再找到这本书拿出来。后来,管理员发现这样的工作实在是太低效了,于是就在这个仓库的外面,借阅的柜台旁边准备了一个柜子,把刚才借过的书暂时先存放在这个柜子里。有些书在很短的时间内会被多次借阅。所以,这本书放在这个临时柜子里的时候,经常就会被借阅到,那管理员就可以很快的把这本书交给借阅的人,而不用去大库里面,花几个小时去寻找。与此同时,管理员还发现了另一个现象,那就是有一个人来借了一本明朝的故事,然后过一会儿,就会再来借清朝的故事,再过一会儿,可能又来借宋朝的故事。而这些书在仓库里面都是紧挨着排放的。所以,他干脆这么做,当要从仓库里取出一本书的时候,就把和这个书在同一层书架上的所有的书都一次性拿出来。这样并不会比取一本书多花多少时间,而对于借书的人来说,他并不会知道管理员做了这件事情。对他来说,还是给出了一个书号,然后过一会儿得到这本书。他只会发现借书的速度变快了。这个类比差不多就是Cache所做的事情。
那我们再来整理一下Cache的访问过程。
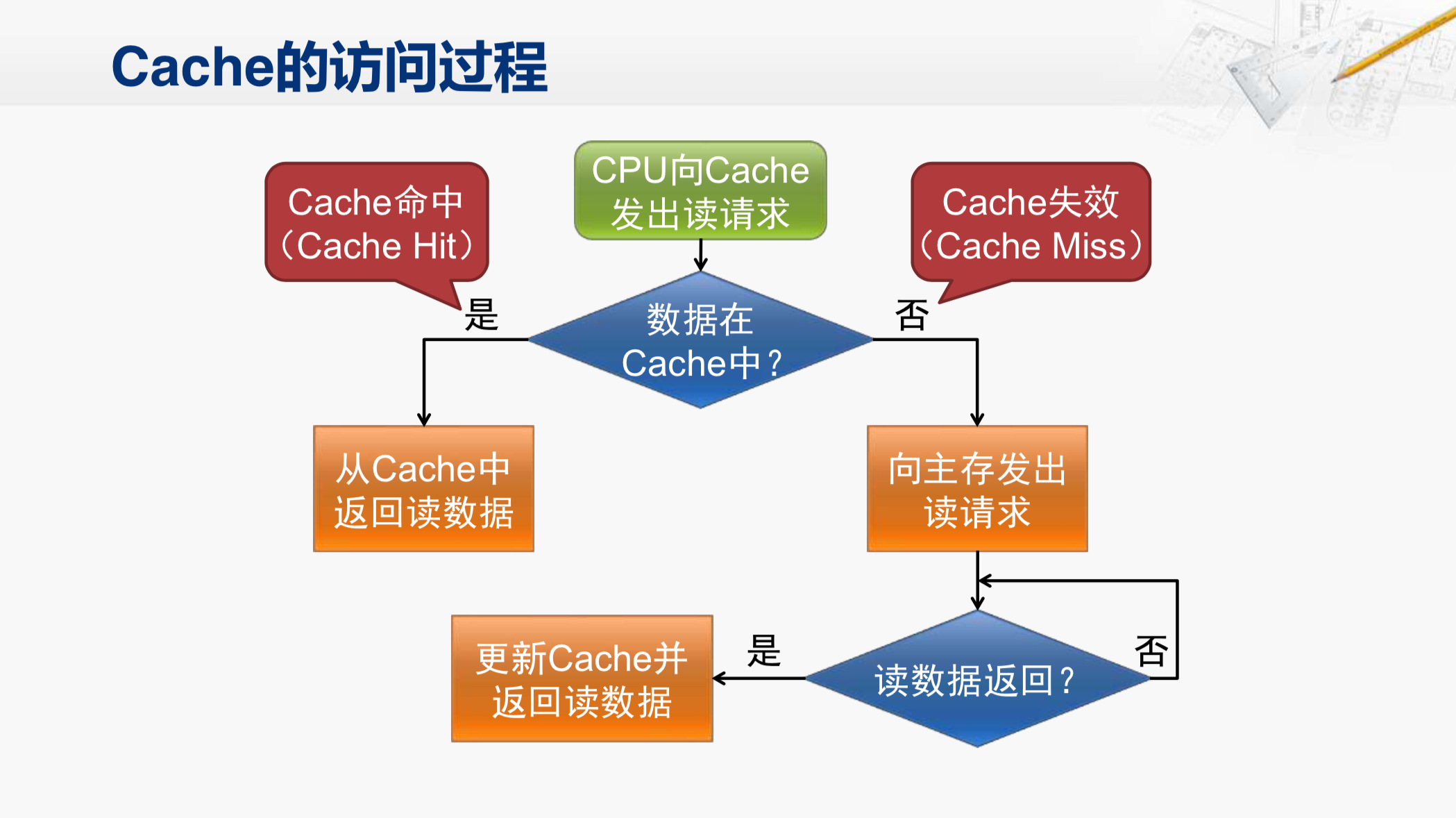
那现在CPU发出读请求,都是直接发给Cache了。然后,Cache这个硬件的部件,会检查这个数据是否在Cache当中。如果是,就称为Cache命中,然后从Cache当中取出对应的数据,返回给CPU就可以了。但是如果这个数不在Cache中,我们就称为Cache失效,这时候,就要由Cache这个部件,向主存发起读请求,这个过程CPU是不知情的,它仍然是在等待Cache返回数据。Cache向主存发出读请求之后,就会等待主存将数据返回,这个过程会很长。那么当包含这个数据的一整个数据块返回之后,Cache就会更新自己内部的内容,并将CPU需要的那个数据返回给CPU。这样就完成了一次Cache读的操作。
那么Cache这个部件内部是如何组织的呢?
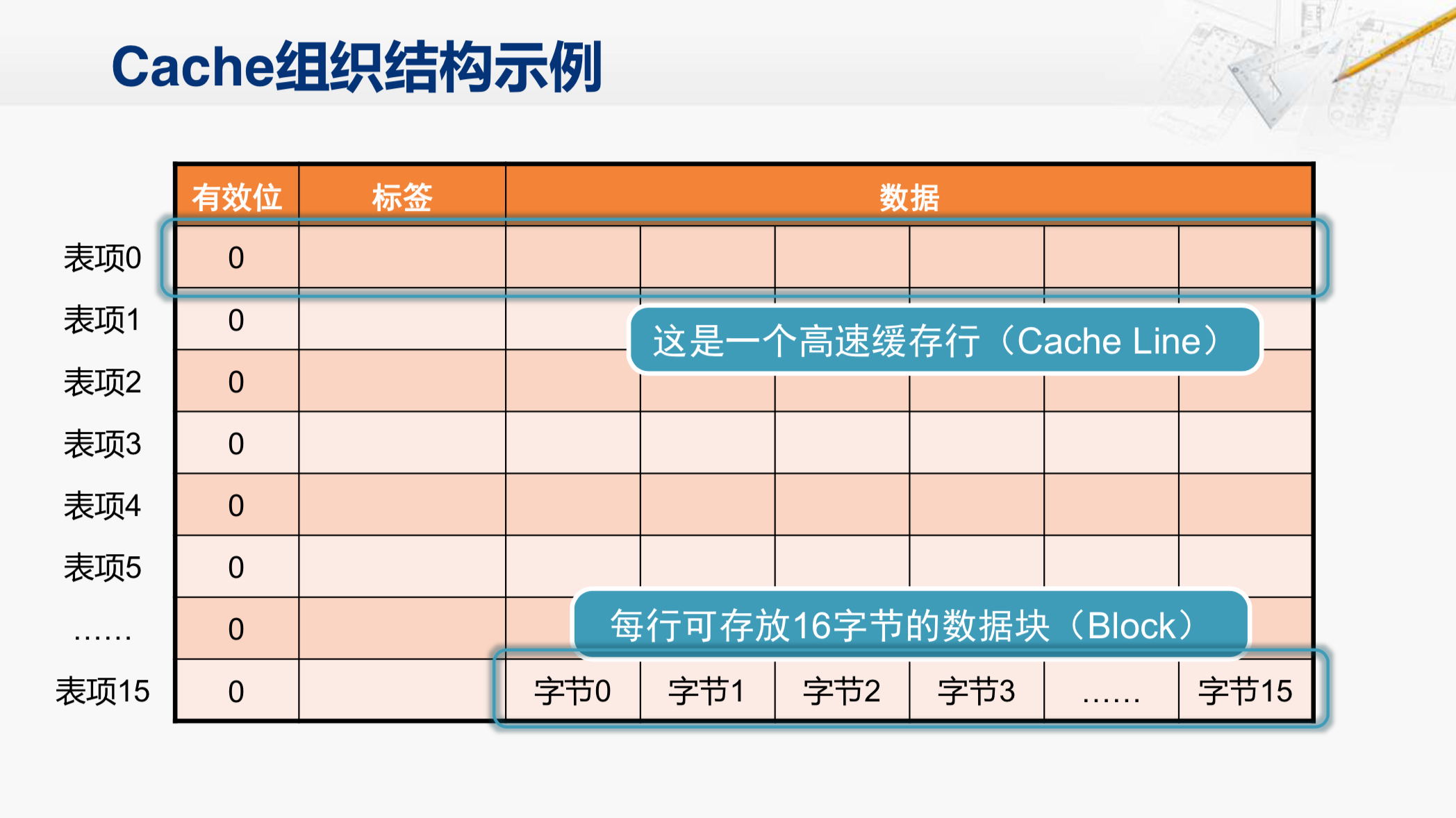
Cache主要组成部分是一块SRAM,当然还有配套的一些控制逻辑电路。
这个SRAM的组织形式就像这个表格,它会分为很多行。那么在这个示例的结构当中,一共有16行。每一行当中有一个比特,是有效位,还有若干个比特是标签,然后其它的位置都是用来存放从内存取回来的数据块。在这个例子当中,一个数据块是16个字节。
那么还是通过一个例子,来看一看这个Cache是如何运行的。
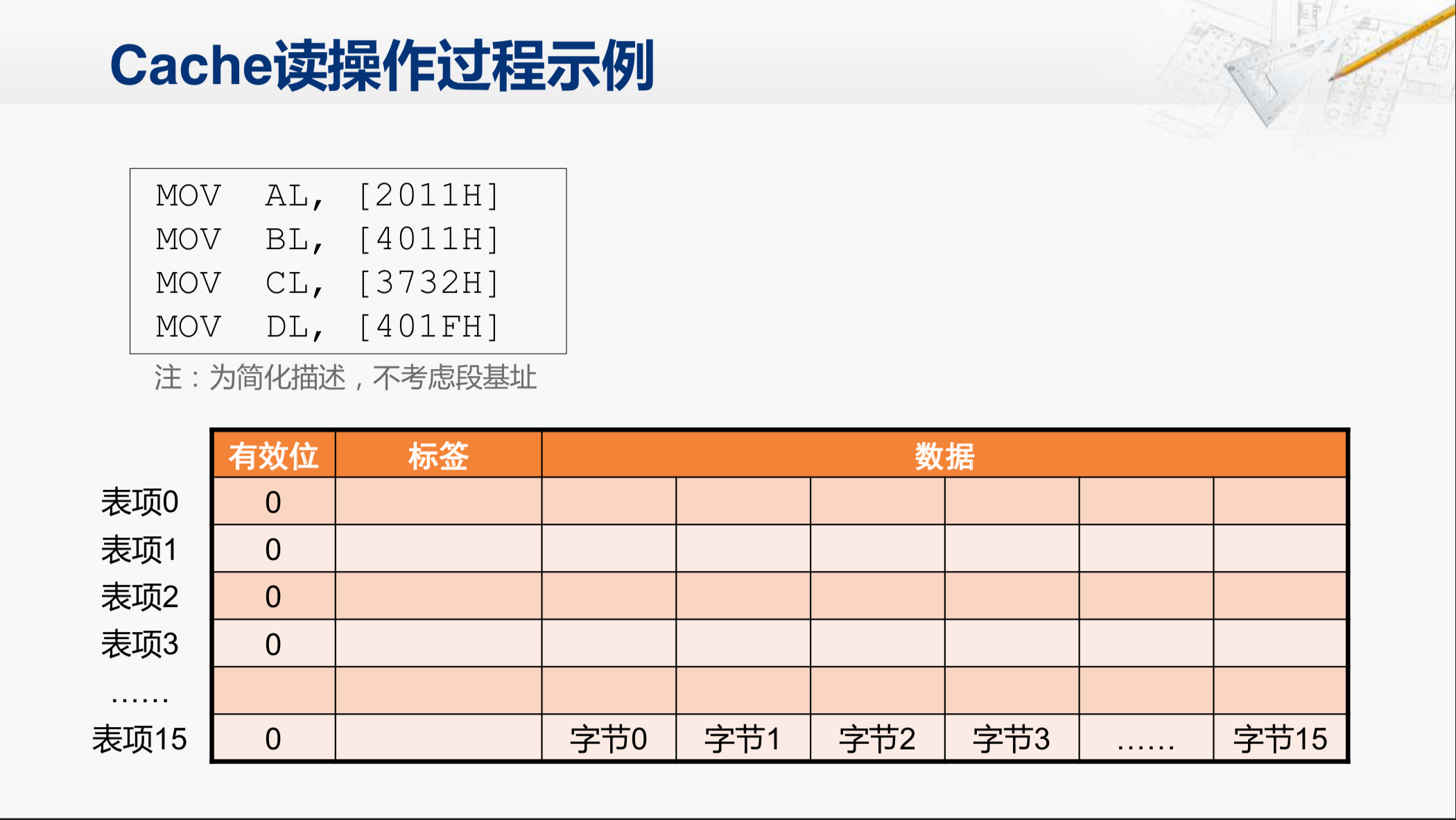
我们就用这个表格来代表Cache。假设现在这个Cache里面全是空的,有效位为0,代表它对应的这一行没有数据。
那么现在来执行这四条指令。
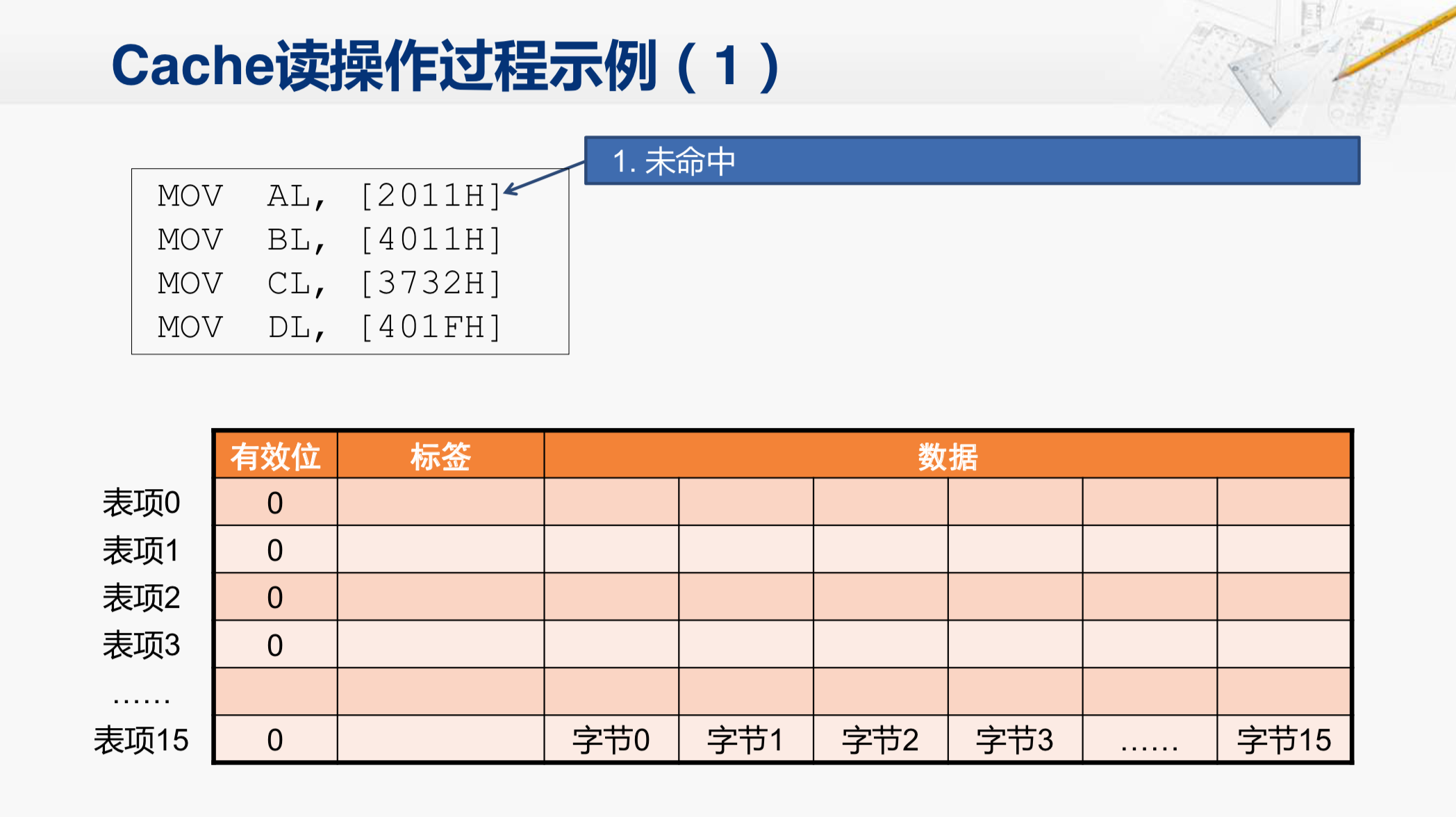
第一步,我们要访问2011H这个内存地址,并取出对应的字节,放在AL寄存器当中去。那CPU就会把这个地址发给Cache,因为现在Cache全是空的,所以,显然没有命中,Cache就会向内存发起一次读操作的请求。
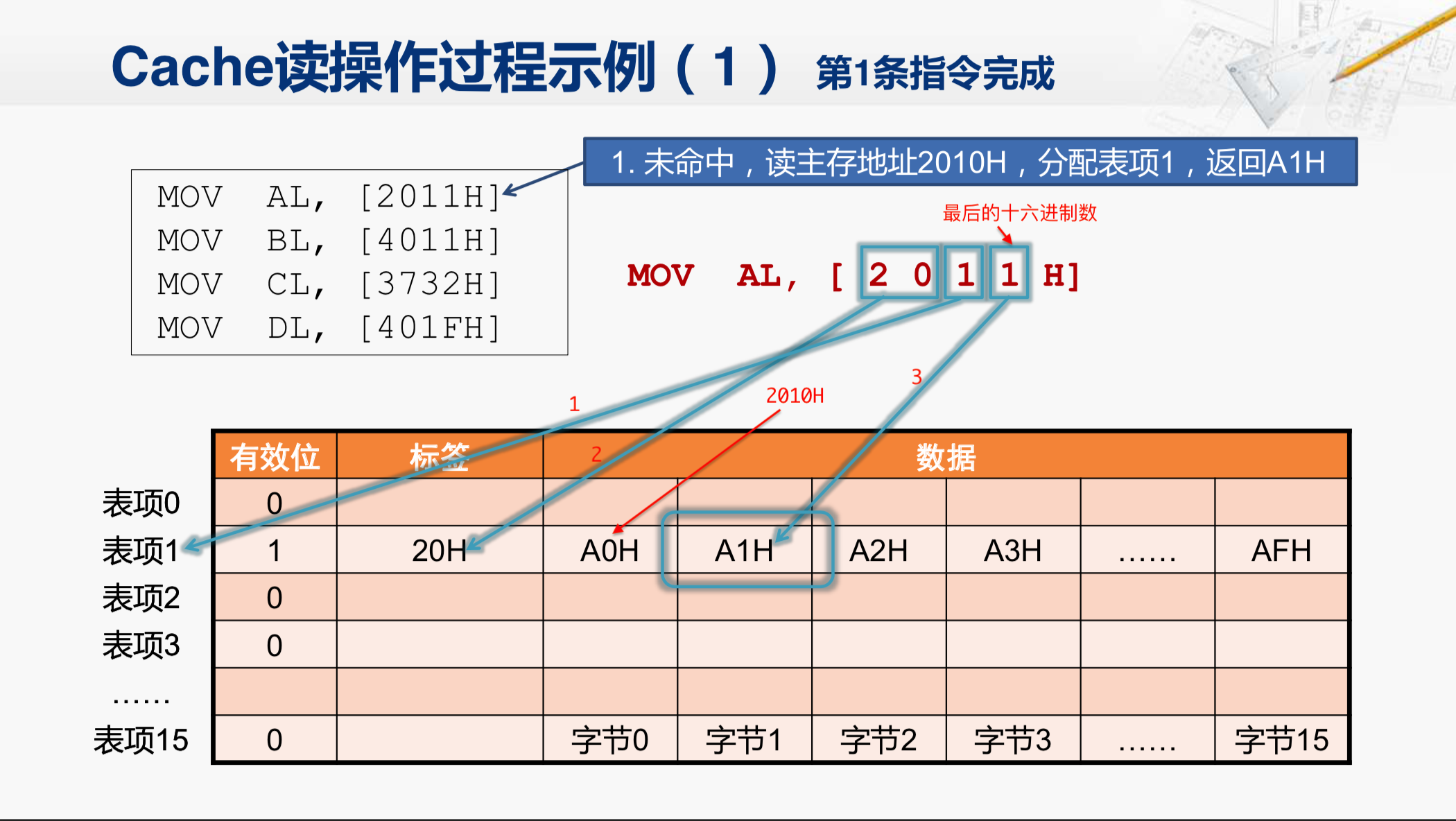
但我们要注意,因为Cache一次要从内存中读出一个数据块。而现在这个Cache的结构,一个数据块是16个字节。所以,它发出的地址都是16个字节对齐的。所以,这时Cache向主存发出的地址是2010H这个地址,是16个字节对齐的,而且从它开始的16个字节的这个数据块当中,包含了2011H这个地址单元。当Cache把这个数据块读回来之后,会分配到表项1中。那么在这个表项(表项1)当中,这个字节(字节0)就是2010所对应的数据;这个字节(字节1)就是2011所对应的数据。所以,Cache会将这个字节返回给CPU。
但是Cache为什么要把这个数据块放在了表项1当中呢?我们详细来看一看。CPU在执行 MOV AL,[2011H] 这条指令的时候,Cache收到的地址实际上是2011H,因为现在一个数据块当中,包括16个字节,最后的这个16进制数,正好用来指定这16个字节当中的哪一个字节是当前所需的。因此,我们取回的这个数据块,要放在哪一个表项当中,就要靠前面的一个地址来决定。那么在现在的Cache设计当中,一般来说,都是用剩下的这些地址当中,最低的那几位来决定到底把这个数据块放在哪一个Cache行中,那我们现在有16个表项,所以也需要4位的地址来决定,那因此,现在剩下的最低的4位地址,就正好是这个16进制数了(红色标号1处),这个数是1。所以,Cache就决定把这个数据块放在表项1的Cache行里。那现在还剩下8位的地址(红色标号2处),我们也必须记录下来,不然以后就搞不清楚这个Cache行里存放的数据到底是对应哪一个地址的。所以,剩下的地址不管有多少都要存放在标签这个域当中。当然,在把数据块取回之后,还需要把有效位置为1。
这样,我们通过这个表格,就可以明确的知道当前的这个数据块是从2010这个地址读出来的。在这个Cache行中的第一个字节(字节1),就是CPU现在所需要的那个字节了,把这个字节取出来,交给CPU,这条指令对应的读操作就完成了。
然后,我们再来看第二条指令。
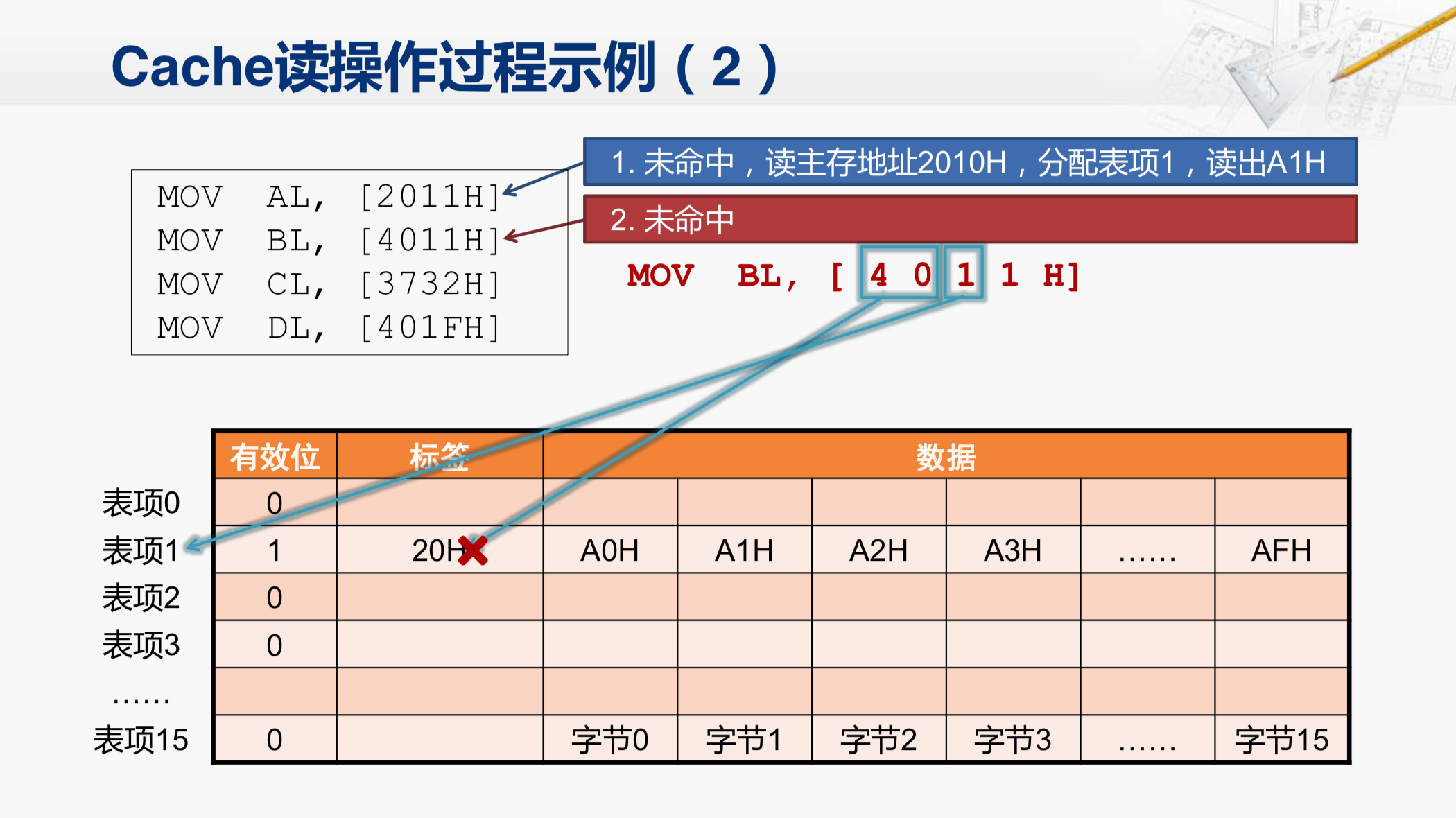
这条指令要读取4011H这个地址。这次我们就来看一看,Cache在收到这个地址后,会做哪些操作。
开始收到4011这个地址后,首先应该找到这个地址对应的Cache行在哪里。它会用这一部分的地址(第二个小蓝矩形中的1)来索引行。所以,找到的还是表项1。然后,检查有效位是1,代表这一行当中的数据是有效的。但这并不能说明它所需要的数据就在这一行里面,接下来还需要比较标签位,把地址当中的高位40H和这个标签位进行比较,结果发现不相等,那就说明这行当中的数据不是4011对应的那个数据块。因此,Cache还是需要向主存发出访存请求。发出的访存地址应该是什么呢?你先考虑一下。
还有一点要注意的就是等会儿取回的这个数据块,也还是需要放在这个表项1当中。所以,会覆盖现在Cache当中的这个数据块,而且等会儿还会把这个标签位也改成40H。
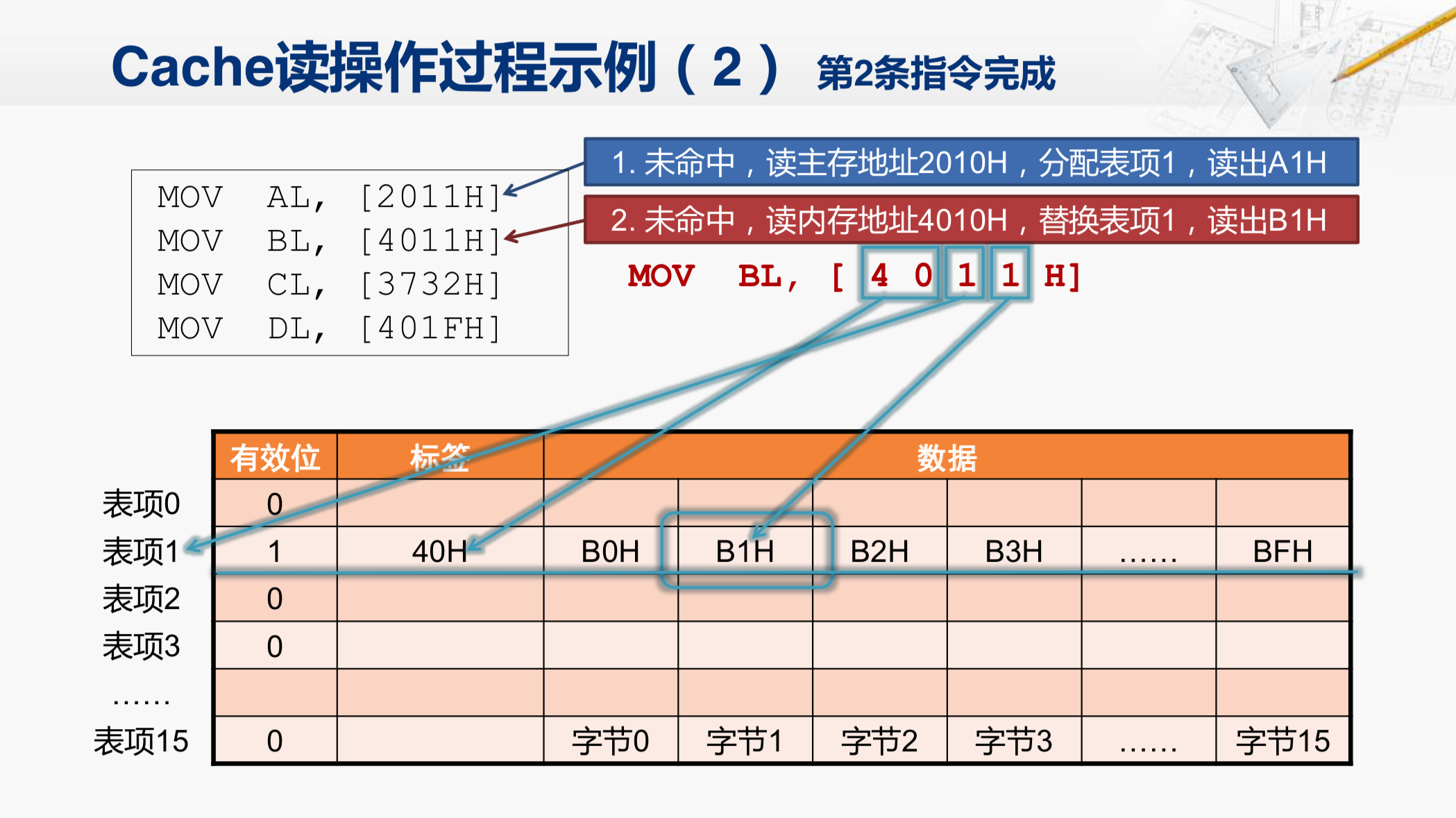
那假设现在Cache已经把对应的数据块从储存当中读回来了,并且完成了对这个Cache行的替换操作。那之后Cache就可以根据地址当中的最低四位找到对应的字节,现在还是第一个字节,把这个字节B1H返回给CPU就完成了这条指令的读操作了。
然后我们再来看第三条指令。
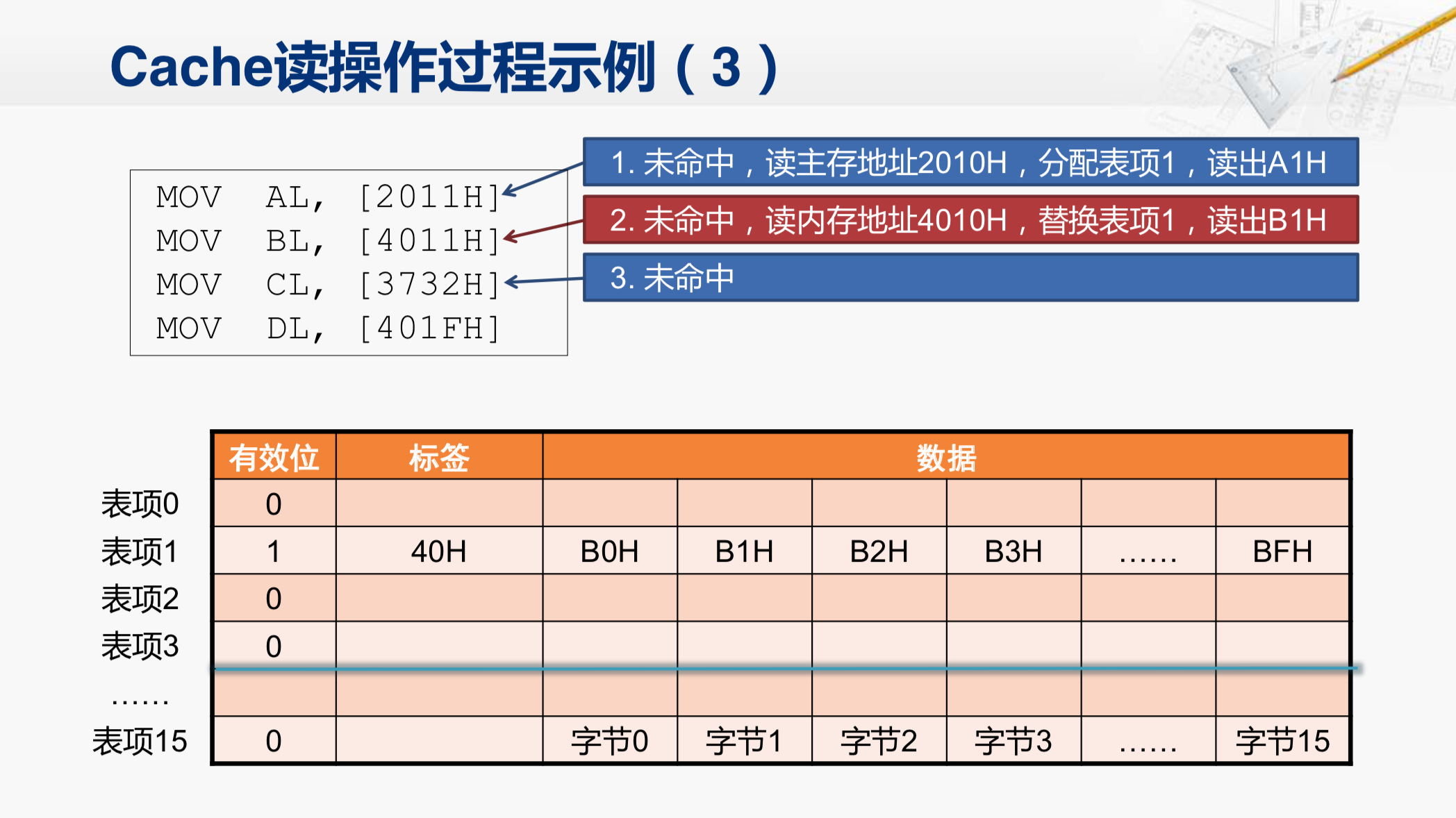
那请先想一想访问这个地址的时候,Cache会去检查哪一个表项,又会进行什么样的操作呢?请先思考一下。然后,我会快速地给出结果,就不再详细地解释了。其实这一次会访问表项3,然后是不命中的。
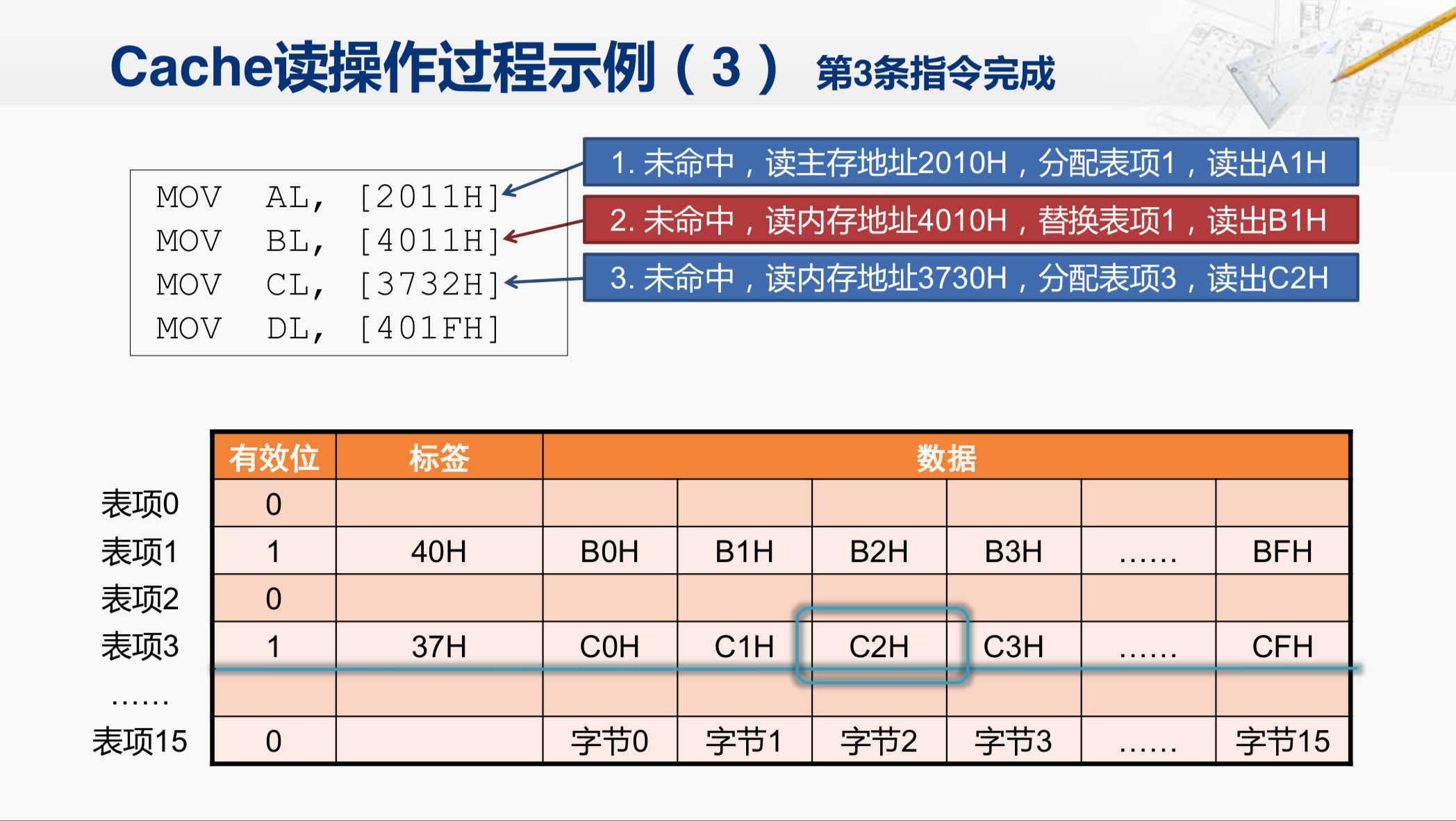
然后读取内存地址3730的数据块,并填到表项3中。然后,返回其中第二个字节C2H给CPU。这样就完成了第三条指令。
然后我们再来看第四条指令。
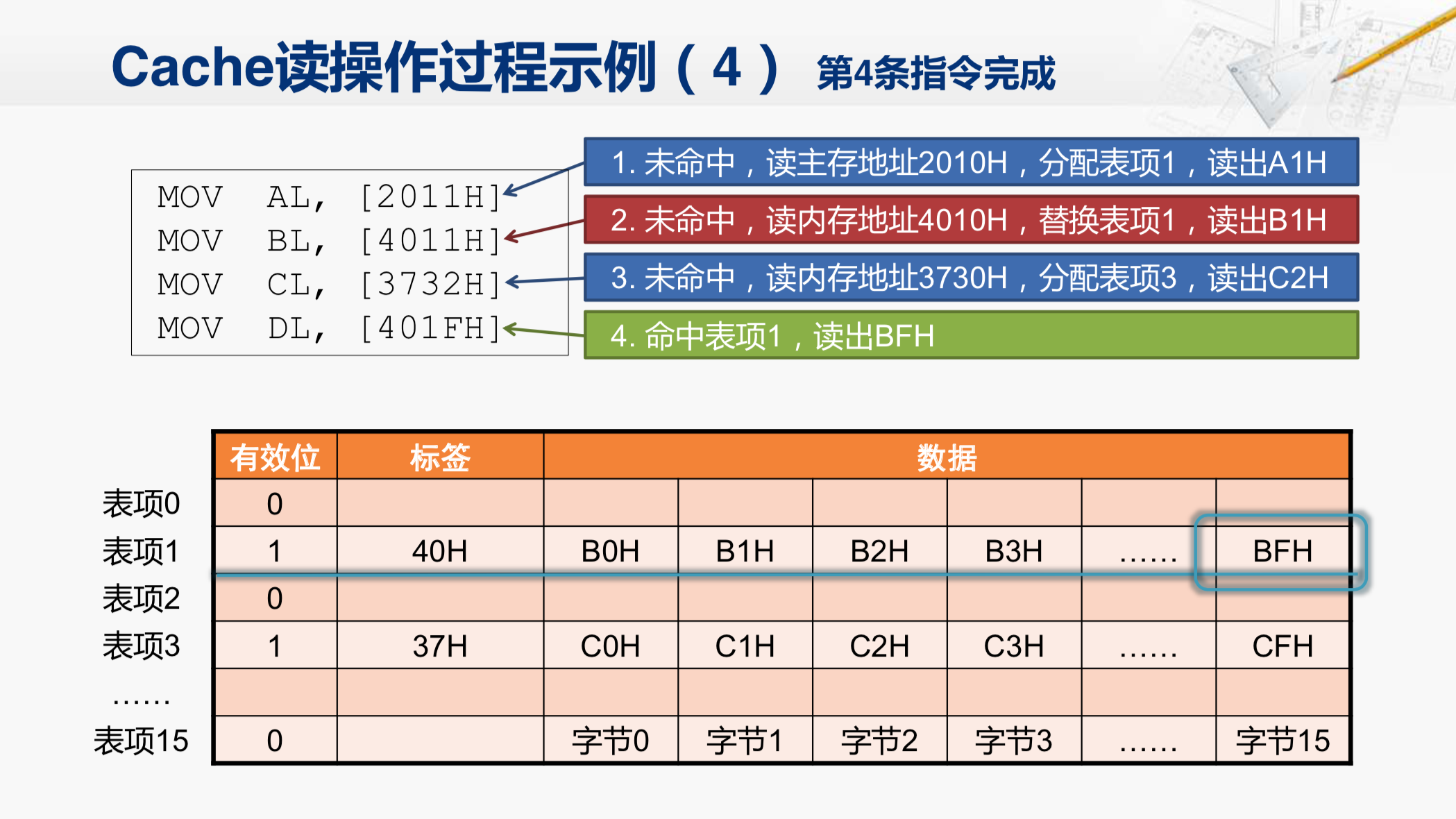
这条指令的地址是401F,那么Cache会首先找到对应的行,因为这部分地址(十六进制数401F第三位)是1。所以,索引到的还是表项1。然后,查看有效位,确定这一行的数据是有效的。下一步是比较标签,那么都是40。所以,标签也是匹配的。这样就可以确认这个地址对应的数据就在这个Cache行当中,那我们就称为Cache命中。最后再根据地址的最低几位(对应十六进制最低位),找到对应的字节,那这个BFH就是CPU需要的这个数据了,把这个数据返回之后,这条指令也就完成了。
那现在我们就了解了Cache读操作的几种典型的情况。一种是没有命中,而且对应的表项是空的时候;第二是没有命中,但是对应的表项已经被占用的情况;还有就是命中了的情况。
那看完了读,我们再来看一看写的情况。

当CPU要写一个数据的时候,也会先送到Cache。这时也会有命中和失效两种情况。
如果Cache命中。我们可以采用一种叫写穿透的策略,把这个数据写入Cache中命中的那一行的同时,也写入主存当中对应的单元。这样就保证了Cache中的数据和主存中的数据始终是一致的。但是因为访问主存比较慢,这样的操作效率是比较低的。所以,我们还可以用另一种策略叫做写返回,这时只需要把数据写到Cache当中,而不写回主存,只有当这个数据块被替换的时候,才把数据写回主存。那这样做的性能显然会好一些,因为有可能会对同一个单元连续进行多次的写,这样只用将最后一次写的结果在替换时,写回主存就可以了,大大减少了访问主存的次数。但是要完成这样的功能,Cache这个部件就会变得复杂得多。
那同样地,在Cache失效的时候,也有两种写策略。一种叫做写不分配。因为Cache失效,所以,要写的那个存储单元不在Cache当中。写不分配的策略就是直接将这个数据写到对应的主存单元里;而另一种策略叫写分配,那就是先将这个数据所在的数据块读到Cache里以后,再将数据写到Cache里。写不分配的策略实现起来是很简单的,但是性能并不太好;而写分配的策略,虽然第一次写的时候操作复杂一些——还是要将这个块读到Cache里以后再写入,看起来比写不分配要慢一点。但是根据局部性的原理,现在写过的这个数据块过一会很可能会被使用。所以,提前把它分配到Cache当中后,会让后续的访存性能大大提升。因此,在现代的Cache设计当中,写穿透和写不分配这两种比较简单的策略往往是配套使用的,用于那些对性能要求不高,但是希望设计比较简单的系统;而大多数希望性能比较好的Cache,都会采用写返回和写分配这一套组合的策略。
那除此之外,在对Cache进行写的过程中,如何去查找分配和替换Cache中的表项,都是和刚才介绍过的读操作的情形是一样的,就不再重复描述了。

高速缓存的基本原理并不复杂,现在我们就可以构造出能够正常工作的高速缓存了。但是如果希望高速缓存能够高效地工作,真正提升计算机的性能,就还需要解决很多的细节问题,之后我们一一探索。
