三、kafka架构深入
1、Kafka的工程流程及文件存储机制


index 和 log 文件以当前 segment 的第一条消息的 offset 命名。下图为 index 文件和 log 文件的结构
示意图

“.index”文件存储大量的索引信息,“.log”文件存储大量的数据,索引文件中的元数据指向对应数据文
件中 message 的物理偏移地址
2、Kafka生产者
1)分区策略
a、方便在集群中扩展,每个 Partition 可以通过调整以适应它所在的机器,而一个 topic 又可以有多个
Partition 组成,因此整个集群就可以适应任意大小的数据了
b、可以提高并发,因为以分区为单位读写了
②、分区的原则


2)数据可靠性保证
为保证 producer 发送的数据,能可靠的发送到指定的 topic,topic 的每个 partition 收到 producer 发送的数据后,
都需要向 producer 发送 ack(acknowledgement 确认收到),如果 producer 收到 ack,就会进行下一轮的发送,
否则重新发送数据

①、副本数据同步策略

②、ISR
采用第二种方案之后,设想以下情景:leader 收到数据,所有 follower 都开始同步数据, 但有一个 follower,
因为某种故障,迟迟不能与 leader 进行同步,那 leader 就要一直等下去, 直到它完成同步,才能发送 ack。
这个问题怎么解决呢?
Leader 维护了一个动态的 in-sync replica set (ISR)(同步的副本集合),意为和 leader 保持同步的 follower
集合。当ISR中的 follower 完成数据的同步之后,leader 就会给 producer发送 ack。如果 follower 长时间未
向 leader 同 步 数 据 ,则 该 follower 将 被 踢 出 ISR , 该 时间阈值replica.lag.time.max.ms 参数设定。
Leader 发生故障之后,就会从ISR 中选举新的 leader。
③、ack应答机制
对于某些不太重要的数据,对数据的可靠性要求不是很高,能够容忍数据的少量丢失, 所以没必要等 ISR
中的 follower 全部接收成功
acks参数配置
0:producer不等待broker的ack,这一操作提供了一个最低的延时,broker一接收到还没有写入磁盘就已
经返回,当broker故障时可能会丢失数据
1:producer等待broker的ack,partition的leader落盘成功后返回ack,如果在follower同步成功之前leader
故障,那么会丢失数据
-1(all):producer等待broker的ack,partition的leader和 follower全部落盘成功后才返回ack。但是如果在follower
同步完成后,broker发送ack之前,leader发生故障,那么会造成数据重复
④、数据故障处理
==== 还没整理好====

 浙公网安备 33010602011771号
浙公网安备 33010602011771号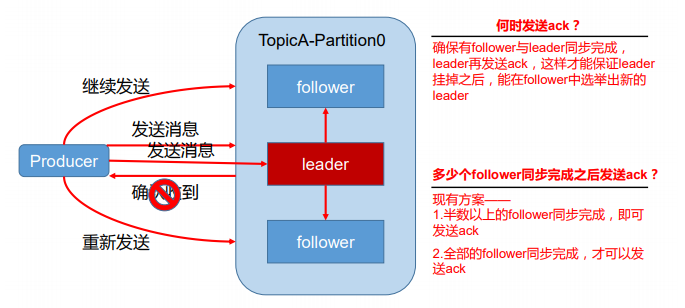{kind=link}
{kind=link}