ElasticSearch — 分词
1、简介
一个tokenizer(分词器)接收一个字符流,将之分隔为独立的tokens(词元,通常是独立的单词),然后输出tokens流
2、如何查看一句话的分词结果:
POST _analyze { "analyzer":"standard" //指定分词器:现在使用的是标准分词器 "text":"我爱北京天安门" }
不得不说啊:标准分词器真是low爆了:

3、安装ik分词器 (可以对中文进行分词)
ik分词器的github地址:

我的es是 7.4.2版本

1)由于elasticsearch容器启动时,指定了文件挂载:-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins
所以,只需要将ik分词器下载到 /mydata/elasticsearch/plugins,并进行解压

2)进入elasticsearch容器内部
docker exec -it fe25cc93c122 /bin/bash

3)使用ik分词器,查看分词结果

4、自定义扩展词库
1)随便启动一个nginx容器,只是为了复制出配置
如果本地没有该镜像,则自动远程下载镜像
docker run -p 80:80 --name nginx -d nginx:1.10
2)将nginx容器内的所有文件拷贝到当前目录: /mydata/nginx
docker container cp nginx:/etc/nginx .
【注意后面有个点】

3)在/mydata/nginx下创建conf文件夹,将原来nginx中的内筒拷贝到conf
4)停止原来的nginx容器
docker stop 79ca00c49e19
删除容器
docker rm 79ca00c49e19
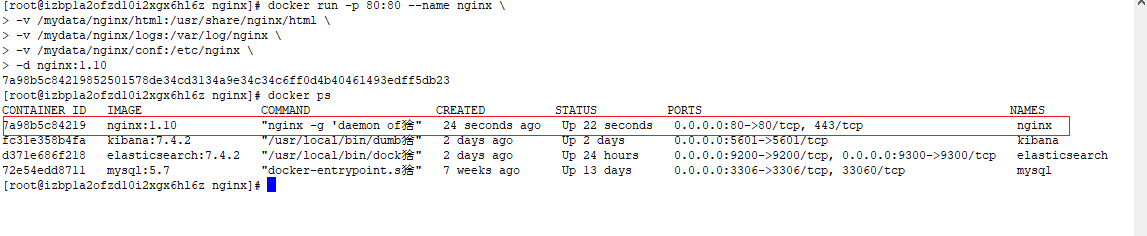
5)以挂载的方式创建新的nginx容器
docker run -p 80:80 --name nginx \
-v /mydata/nginx/html:/usr/share/nginx/html \
-v /mydata/nginx/logs:/var/log/nginx \
-v /mydata/nginx/conf:/etc/nginx \
-d nginx:1.10
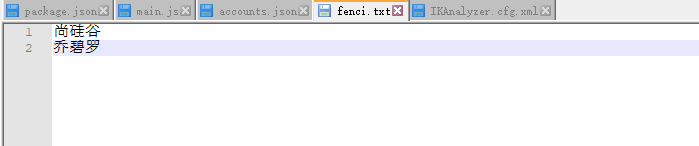
6) 在nginx下的html中创建 es文件夹,并创建 fenci.txt
fenci.txt 里面记录的是词库
7) 在 ik文件夹下 /coonfig/IKAnalyzer.cfg.xml 可以配置远程词典的地址
(此时远程词典应该在nginx的静态资源文件夹下)
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict"></entry> <!--用户可以在这里配置自己的扩展停止词字典--> <entry key="ext_stopwords"></entry> <!--用户可以在这里配置远程扩展字典 --> <entry key="remote_ext_dict">http://121.40.182.123/es/fenci.txt</entry> <!--用户可以在这里配置远程扩展停止词字典--> <!-- <entry key="remote_ext_stopwords">words_location</entry> --> </properties>
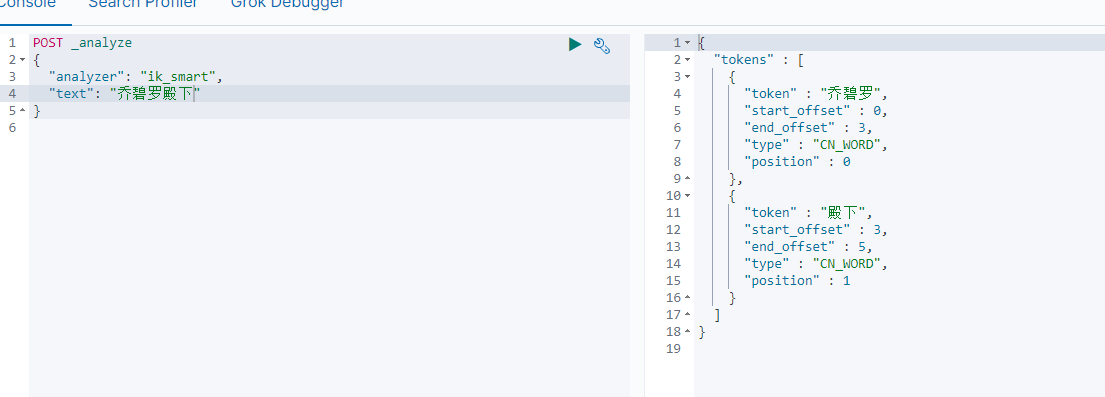
8)重启es服务
重新分词,可以看到乔碧罗被识别成一个单词了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号