
Faster RCNN算法训练代码解析(1)
这周看完faster-rcnn后,应该对其源码进行一个解析,以便后面的使用。
那首先直接先主函数出发py-faster-rcnn/tools/train_faster_rcnn_alt_opt.py
我们在后端的运行命令为
python ./py-faster-rcnn/tools/train_faster_rcnn_alt_opt.py
--gpu
0
--net_name
ZF
--weights
data/imagenet_models/ZF.v2.caffemodel
--imdb
voc_2007_trainval
--cfg
experiments/cfgs/faster_rcnn_alt_opt.yml
从这条命令就可以看出,我们是使用0id的GPU,使用ZF网络,预训练模型使用ZF.v2.caffemodel,数据集使用voc_2007_trainval,配置文件cfg使用faster_rcnn_alt_opt.yml。
先进入主函数:
if __name__ == '__main__': args = parse_args() #获取命令行参数 #Namespace(cfg_file='experiments/cfgs/faster_rcnn_alt_opt.yml', gpu_id=0, imdb_name='voc_2007_trainval',
#net_name='ZF', pretrained_model='data/imagenet_models/ZF.v2.caffemodel', set_cfgs=None)
print('Called with args:') print(args) if args.cfg_file is not None: ##配置文件存在,则加载配置文件 cfg_from_file(args.cfg_file) ##进入config.py文件,通过yaml加载后使用edict转化格式,然后通过_merge_a_into_b(a, b)迭代融合成一个config if args.set_cfgs is not None: cfg_from_list(args.set_cfgs) cfg.GPU_ID = args.gpu_id ##设置使用的GPU的id,一般直接为0 # -------------------------------------------------------------------------- # Pycaffe doesn't reliably free GPU memory when instantiated nets are # discarded (e.g. "del net" in Python code). To work around this issue, each # training stage is executed in a separate process using # multiprocessing.Process. # -------------------------------------------------------------------------- # queue for communicated results between processes mp_queue = mp.Queue() ##创建一个多线程的对象 # solves, iters, etc. for each training stage solvers, max_iters, rpn_test_prototxt = get_solvers(args.net_name) ##获得solvers等信息
进入get_solvers()函数:
def get_solvers(net_name): ##ZF net # Faster R-CNN Alternating Optimization n = 'faster_rcnn_alt_opt' ##采取alt_opt训练方式 # Solver for each training stage solvers = [[net_name, n, 'stage1_rpn_solver60k80k.pt'], [net_name, n, 'stage1_fast_rcnn_solver30k40k.pt'], [net_name, n, 'stage2_rpn_solver60k80k.pt'], [net_name, n, 'stage2_fast_rcnn_solver30k40k.pt']] solvers = [os.path.join(cfg.MODELS_DIR, *s) for s in solvers] ##记录该训练方式的各阶段的solver(训练参数),即rpn训练和整体faster_rcnn训练的slover # Iterations for each training stage max_iters = [80000, 40000, 80000, 40000] # max_iters = [100, 100, 100, 100] # Test prototxt for the RPN rpn_test_prototxt = os.path.join( cfg.MODELS_DIR, net_name, n, 'rpn_test.pt') ##记录rpn测试的prototext,即rpn测试时的网络结构 return solvers, max_iters, rpn_test_prototxt
接着回到主函数里面,开始第一阶段的训练:
print '~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~' print 'Stage 1 RPN, init from ImageNet model' print '~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~' cfg.TRAIN.SNAPSHOT_INFIX = 'stage1' mp_kwargs = dict( queue=mp_queue, imdb_name=args.imdb_name, ##'voc_2007_trainval' init_model=args.pretrained_model, ##使用预训练模型'data/imagenet_models/ZF.v2.caffemodel' solver=solvers[0], ##'py-faster-rcnn/models/pascal_voc/ZF/faster_rcnn_alt_opt/stage1_rpn_solver60k80k.pt' max_iters=max_iters[0], ##最大迭代次数80000 cfg=cfg) p = mp.Process(target=train_rpn, kwargs=mp_kwargs) ##设置进程对象,进程执行train_rpn函数,使用mp_kwargs参数 p.start() rpn_stage1_out = mp_queue.get() ##获取线程中的数据,这里属于进程间的通信 p.join() ##等待子线性结束
接着进入train_rpn()函数来看看:
def train_rpn(queue=None, imdb_name=None, init_model=None, solver=None, max_iters=None, cfg=None): """Train a Region Proposal Network in a separate training process. """ ##注意,第一阶段的训练没有使用任何的建议框,而是使用gt_boxes来训练 cfg.TRAIN.HAS_RPN = True cfg.TRAIN.BBOX_REG = False # 只针对 Fast R-CNN bbox regression来开启该选项 cfg.TRAIN.PROPOSAL_METHOD = 'gt' #默认使用gt来进行区域建议 cfg.TRAIN.IMS_PER_BATCH = 1 print 'Init model: {}'.format(init_model) print('Using config:') pprint.pprint(cfg) ##pprint专门打印python数据结构类 import caffe _init_caffe(cfg) ##初始化caffe,设置了随机数种子,以及使用caffe训练时的模式(gpu/cpu) roidb, imdb = get_roidb(imdb_name) print 'roidb len: {}'.format(len(roidb)) output_dir = get_output_dir(imdb) print 'Output will be saved to `{:s}`'.format(output_dir) model_paths = train_net(solver, roidb, output_dir, pretrained_model=init_model, max_iters=max_iters) # Cleanup all but the final model for i in model_paths[:-1]: os.remove(i) rpn_model_path = model_paths[-1] # Send final model path through the multiprocessing queue queue.put({'model_path': rpn_model_path})
pprint.pprint(cfg)打印出来的config的配置项:
Using config: {'DATA_DIR': '/home/home/FRCN_ROOT/py-faster-rcnn/data', 'DEDUP_BOXES': 0.0625, 'EPS': 1e-14, 'EXP_DIR': 'faster_rcnn_alt_opt', 'GPU_ID': 0, 'MATLAB': 'matlab', 'MODELS_DIR': '/home/home/FRCN_ROOT/py-faster-rcnn/models/pascal_voc', 'PIXEL_MEANS': array([[[ 102.9801, 115.9465, 122.7717]]]), 'RNG_SEED': 3, 'ROOT_DIR': '/home/home/FRCN_ROOT/py-faster-rcnn', 'TEST': {'BBOX_REG': True, 'HAS_RPN': True, 'MAX_SIZE': 1000, 'NMS': 0.3, 'PROPOSAL_METHOD': 'selective_search', 'RPN_MIN_SIZE': 16, 'RPN_NMS_THRESH': 0.7, 'RPN_POST_NMS_TOP_N': 300, 'RPN_PRE_NMS_TOP_N': 6000, 'SCALES': [600], 'SVM': False}, 'TRAIN': {'ASPECT_GROUPING': True, 'BATCH_SIZE': 128, 'BBOX_INSIDE_WEIGHTS': [1.0, 1.0, 1.0, 1.0], 'BBOX_NORMALIZE_MEANS': [0.0, 0.0, 0.0, 0.0], 'BBOX_NORMALIZE_STDS': [0.1, 0.1, 0.2, 0.2], 'BBOX_NORMALIZE_TARGETS': True, 'BBOX_NORMALIZE_TARGETS_PRECOMPUTED': False, 'BBOX_REG': False, 'BBOX_THRESH': 0.5, 'BG_THRESH_HI': 0.5, 'BG_THRESH_LO': 0.0, 'FG_FRACTION': 0.25, 'FG_THRESH': 0.5, 'HAS_RPN': True, 'IMS_PER_BATCH': 1, 'MAX_SIZE': 1000, 'PROPOSAL_METHOD': 'gt', 'RPN_BATCHSIZE': 256, 'RPN_BBOX_INSIDE_WEIGHTS': [1.0, 1.0, 1.0, 1.0], 'RPN_CLOBBER_POSITIVES': False, 'RPN_FG_FRACTION': 0.5, 'RPN_MIN_SIZE': 16, 'RPN_NEGATIVE_OVERLAP': 0.3, 'RPN_NMS_THRESH': 0.7, 'RPN_POSITIVE_OVERLAP': 0.7, 'RPN_POSITIVE_WEIGHT': -1.0, 'RPN_POST_NMS_TOP_N': 2000, 'RPN_PRE_NMS_TOP_N': 12000, 'SCALES': [600], 'SNAPSHOT_INFIX': 'stage1', 'SNAPSHOT_ITERS': 10000, 'USE_FLIPPED': True, 'USE_PREFETCH': False}, 'USE_GPU_NMS': True}
继续,现在我们进入函数 roidb, imdb = get_roidb(imdb_name):
def get_roidb(imdb_name, rpn_file=None): imdb = get_imdb(imdb_name) print 'Loaded dataset `{:s}` for training'.format(imdb.name) ##加载数据完毕 imdb.set_proposal_method(cfg.TRAIN.PROPOSAL_METHOD) ##设置区域建议所使用的方法gt,具体使用eval融合字符串再赋值 print 'Set proposal method: {:s}'.format(cfg.TRAIN.PROPOSAL_METHOD) if rpn_file is not None: imdb.config['rpn_file'] = rpn_file roidb = get_training_roidb(imdb) return roidb, imdb
进入imdb = get_imdb(imdb_name)函数,该文件在/py-faster-rcnn/lib/datasets/factory.py,其实主要是运用工厂模式来适配不同的数据集:
for year in ['2007', '2012']:
for split in ['train', 'val', 'trainval', 'test']:
name = 'voc_{}_{}'.format(year, split)
__sets[name] = (lambda split=split, year=year: pascal_voc(split, year))
def get_imdb(name): """Get an imdb (image database) by name.""" if not __sets.has_key(name): raise KeyError('Unknown dataset: {}'.format(name)) return __sets[name]() ##执行该函数,该函数对应上面的lambda,适配pascal_voc来建造数据
这里其实也是调用了pascal_voc()函数来创建imdb数据,pascal_voc类见py-faster-rcnn/lib/datasets/pascal_voc.py文件中,如下:
class pascal_voc(imdb): def __init__(self, image_set, year, devkit_path=None): imdb.__init__(self, 'voc_' + year + '_' + image_set) ##进入基类imdb来进行初始化 self._year = year self._image_set = image_set self._devkit_path = self._get_default_path() if devkit_path is None \ else devkit_path self._data_path = os.path.join(self._devkit_path, 'VOC' + self._year) self._classes = ('__background__', # always index 0 该数据集加上背景一共有21类 'aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor') self._class_to_ind = dict(zip(self.classes, xrange(self.num_classes))) ##将各个类随机转化成对应的数字,比如sheep=17 self._image_ext = '.jpg' self._image_index = self._load_image_set_index() ##读取py-faster-rcnn/data/VOCdevkit2007/VOC2007/ImageSets/Main/trainval.txt
##为每个图片标注index,不如000005.jpg=0000
# Default to roidb handler self._roidb_handler = self.selective_search_roidb self._salt = str(uuid.uuid4()) self._comp_id = 'comp4' # PASCAL specific config options self.config = {'cleanup' : True, 'use_salt' : True, 'use_diff' : False, 'matlab_eval' : False, 'rpn_file' : None, 'min_size' : 2} assert os.path.exists(self._devkit_path), \ 'VOCdevkit path does not exist: {}'.format(self._devkit_path) assert os.path.exists(self._data_path), \ 'Path does not exist: {}'.format(self._data_path)
这里只截取了一部分,可以发现,pascal_voc这个类主要用来组织输入的图片数据,存储图片的相关信息,但并不存储图片;而实际上,pascal_voc类是imdb类的一个子类;进入imdb的类:
class imdb(object): """Image database.""" def __init__(self, name): self._name = name self._num_classes = 0 self._classes = [] self._image_index = [] self._obj_proposer = 'selective_search' ##先前的fast rcnn默认使用ss方法进行区域建议 self._roidb = None self._roidb_handler = self.default_roidb # Use this dict for storing dataset specific config options self.config = {} @property def name(self): ##基类属性在子类(pascal类)创建时若有赋值操作则自动生成 return self._name @property def num_classes(self): return len(self._classes) @property def classes(self): return self._classes @property def image_index(self): return self._image_index @property ##把方法装饰成该类的属性 def roidb_handler(self): return self._roidb_handler @roidb_handler.setter ##对roidb_handler产生另外一个装饰器,使用setter属性进行赋值 def roidb_handler(self, val): self._roidb_handler = val def set_proposal_method(self, method): ##运用setter来设置训练方法 method = eval('self.' + method + '_roidb') self.roidb_handler = method @property def roidb(self): # A roidb is a list of dictionaries, each with the following keys: # boxes # gt_overlaps # gt_classes # flipped if self._roidb is not None: return self._roidb self._roidb = self.roidb_handler() return self._roidb @property def cache_path(self): cache_path = osp.abspath(osp.join(cfg.DATA_DIR, 'cache')) if not os.path.exists(cache_path): os.makedirs(cache_path) return cache_path @property def num_images(self): return len(self.image_index)
此时我们看看现在的变量值:
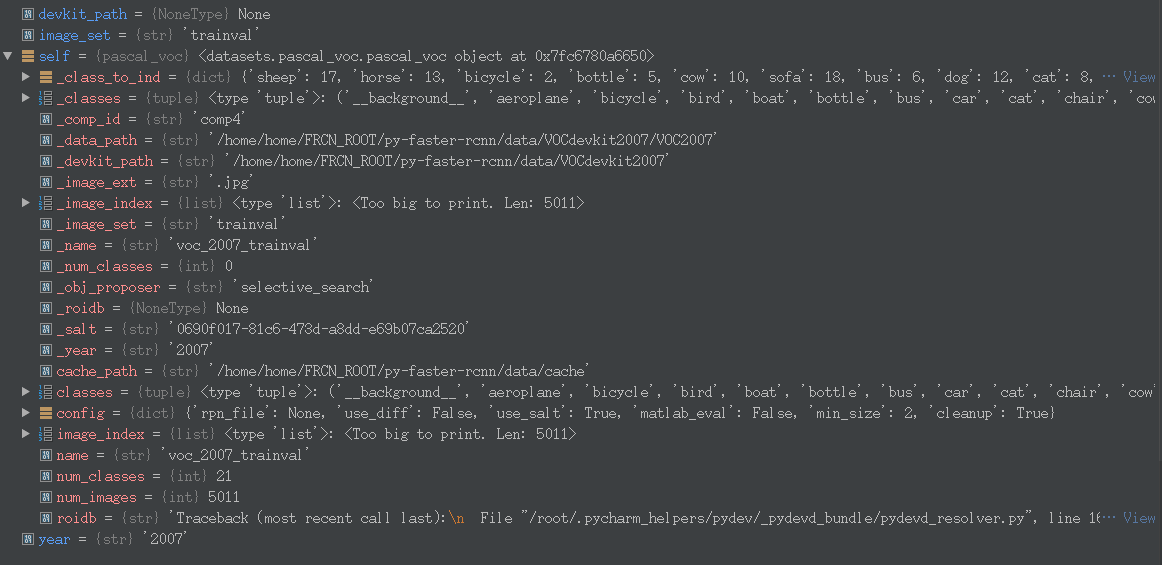
好了现在imdb数据已经获得了,再回到get_roidb()里面的imdb = get_imdb(imdb_name)函数中,紧接着set_proposal_method()函数设置了产生proposal的方法,实际也是向imdb中添加roidb数据:
def set_proposal_method(self, method): method = eval('self.' + method + '_roidb') self.roidb_handler = method ##method=self.gt_roidb,这里其实是调用了pascal_voc.py文件里面的gt_roidb()函数
首先用eval()对这个方法进行解析,使其有效,再传入roidb_handler中,这里就要回到之前的train_rpn()函数中了,它里面设置了cfg.TRAIN.PROPOSAL_METHOD='gt'(默认值是selective search,先前用于fast rcnn的),先进入gt_roidb()函数中:
def gt_roidb(self): """ Return the database of ground-truth regions of interest. This function loads/saves from/to a cache file to speed up future calls. """ cache_file = os.path.join(self.cache_path, self.name + '_gt_roidb.pkl') ##如果存在gt框的位置文件则加载并返回gt框的信息(roidb) if os.path.exists(cache_file): with open(cache_file, 'rb') as fid: roidb = cPickle.load(fid) print '{} gt roidb loaded from {}'.format(self.name, cache_file) return roidb gt_roidb = [self._load_pascal_annotation(index) ##如果不存在则直接读取文件的 for index in self.image_index] with open(cache_file, 'wb') as fid: cPickle.dump(gt_roidb, fid, cPickle.HIGHEST_PROTOCOL) print 'wrote gt roidb to {}'.format(cache_file) return gt_roidb
这里的gt_roidb = [self._load_pascal_annotation(index)函数为:
def _load_pascal_annotation(self, index): """ Load image and bounding boxes info from XML file in the PASCAL VOC format. """ filename = os.path.join(self._data_path, 'Annotations', index + '.xml') tree = ET.parse(filename) ##从硬盘导入xml文件 objs = tree.findall('object') ##找到object的tag if not self.config['use_diff']: ##取出tag为difficult的object # Exclude the samples labeled as difficult non_diff_objs = [ obj for obj in objs if int(obj.find('difficult').text) == 0] # if len(non_diff_objs) != len(objs): # print 'Removed {} difficult objects'.format( # len(objs) - len(non_diff_objs)) objs = non_diff_objs num_objs = len(objs) boxes = np.zeros((num_objs, 4), dtype=np.uint16) ##boxes的存储坐标,4个,所以为四列 gt_classes = np.zeros((num_objs), dtype=np.int32) ##gt框的类 overlaps = np.zeros((num_objs, self.num_classes), dtype=np.float32) ##重叠率矩阵 # "Seg" area for pascal is just the box area seg_areas = np.zeros((num_objs), dtype=np.float32) ##面积 # Load object bounding boxes into a data frame. for ix, obj in enumerate(objs): bbox = obj.find('bndbox') # Make pixel indexes 0-based x1 = float(bbox.find('xmin').text) - 1 y1 = float(bbox.find('ymin').text) - 1 x2 = float(bbox.find('xmax').text) - 1 y2 = float(bbox.find('ymax').text) - 1 cls = self._class_to_ind[obj.find('name').text.lower().strip()] boxes[ix, :] = [x1, y1, x2, y2] gt_classes[ix] = cls overlaps[ix, cls] = 1.0 seg_areas[ix] = (x2 - x1 + 1) * (y2 - y1 + 1) overlaps = scipy.sparse.csr_matrix(overlaps) return {'boxes' : boxes, 'gt_classes': gt_classes, 'gt_overlaps' : overlaps, 'flipped' : False, 'seg_areas' : seg_areas}
由上面可以看出roidb的结构是一个包含有5个key的字典。
这个时候就从imdb获得了最初的roidb格式的数据,但这还不是训练时的roidb数据,再回到get_roidb()函数中,通过get_training_roidb(imdb)函数得到最终用于训练的roidb数据,进入该函数:
def get_training_roidb(imdb): """Returns a roidb (Region of Interest database) for use in training.""" if cfg.TRAIN.USE_FLIPPED: print 'Appending horizontally-flipped training examples...' imdb.append_flipped_images() ##如果设置了翻转项,则对图片进行水平翻转后添加,原来5000张图片,加入翻转后为10000左右,这里可以理解成数据增强 print 'done' print 'Preparing training data...' rdl_roidb.prepare_roidb(imdb) ##对roidb加入额外的信息,方便训练 print 'done' return imdb.roidb
进入翻转函数append_flipped_images():
def append_flipped_images(self): num_images = self.num_images widths = self._get_widths() ##具体里面是使用PIL库来获取width for i in xrange(num_images): boxes = self.roidb[i]['boxes'].copy() oldx1 = boxes[:, 0].copy() oldx2 = boxes[:, 2].copy() boxes[:, 0] = widths[i] - oldx2 - 1 boxes[:, 2] = widths[i] - oldx1 - 1 assert (boxes[:, 2] >= boxes[:, 0]).all() entry = {'boxes' : boxes, 'gt_overlaps' : self.roidb[i]['gt_overlaps'], 'gt_classes' : self.roidb[i]['gt_classes'], 'flipped' : True} self.roidb.append(entry) self._image_index = self._image_index * 2
进入rdl_roidb.prepare_roidb(imdb)函数:
def prepare_roidb(imdb): """Enrich the imdb's roidb by adding some derived quantities that are useful for training. This function precomputes the maximum overlap, taken over ground-truth boxes, between each ROI and each ground-truth box. The class with maximum overlap is also recorded. """ sizes = [PIL.Image.open(imdb.image_path_at(i)).size for i in xrange(imdb.num_images)] roidb = imdb.roidb for i in xrange(len(imdb.image_index)): ##加入位置,宽,高等信息 roidb[i]['image'] = imdb.image_path_at(i) roidb[i]['width'] = sizes[i][0] roidb[i]['height'] = sizes[i][1] # need gt_overlaps as a dense array for argmax gt_overlaps = roidb[i]['gt_overlaps'].toarray() # max overlap with gt over classes (columns) max_overlaps = gt_overlaps.max(axis=1) # gt class that had the max overlap max_classes = gt_overlaps.argmax(axis=1) roidb[i]['max_classes'] = max_classes ##加入最大概率类 roidb[i]['max_overlaps'] = max_overlaps ##加入最大重叠率 # sanity checks # max overlap of 0 => class should be zero (background) zero_inds = np.where(max_overlaps == 0)[0] assert all(max_classes[zero_inds] == 0) # max overlap > 0 => class should not be zero (must be a fg class) nonzero_inds = np.where(max_overlaps > 0)[0] assert all(max_classes[nonzero_inds] != 0)
查看此时roidb的结构:
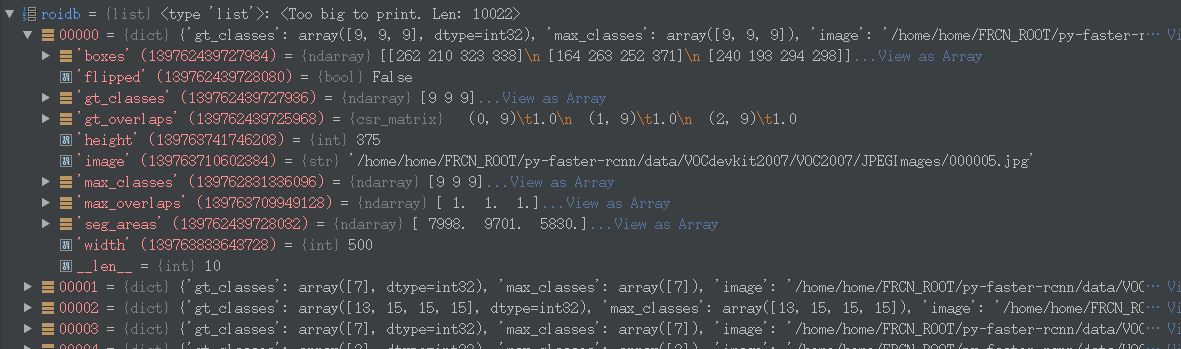
此时roidb的图片000005.jpg的,也即index为00000的图片的数据结构下有:boxes、flipped(是否翻转过)、gt_classes、gt_overlaps、height、image、max_classes、max_overlaps、seg_areas(boxes的面积)、width、__len__
到这里为止,我们已经成功利用工厂模式适配pascal_voc的数据集,并读取xml文件来获取数据集的gt框(roisdb),第一部分介绍完毕。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号