

选择判断
- 特别是对于范围在 -5 到 256 之间的整数。对于这些整数,Python 会使用缓存机制,即它们在程序的生命周期内是单例的,所有引用该值的地方都会指向同一个内存地址。
- while和for可以有else
for i in range(5):
print(i)
if i == 3:
break
else:
print("循环没有被 break 终止")
- join() 方法需要传入一个可迭代对象,如列表、元组或其他字符串序列。
- join要传入可迭代对象且里面是字符串
![image]()
- capitalize()方法是用来将字符串将字符串首字母变为大写
title()将字符串每个单词首字母变为大写 - print(str(var).rjust(10, '0'))
这是将 var 转换为字符串后,使用 rjust() 方法进行右对齐,并用零填充。
print(str(var).zfill(10))
zfill() 方法用于将字符串填充为指定宽度,并且用零填充。它会在字符串的左侧填充零,直到达到指定的宽度。
字符串去除两端字母
strip() 方法用于去除字符串两端的字符(默认去除空白字符)。
print(var.strip('bcdfa')) - split返回列表

l=list(input().split())
l=[int(num) for num in input().split()]
l=[chr(int(i)) for i in input().split()]
l=list(input().split())
s=[c for c in input().upper() if c.isalnum()]
a,b=map(int,input().split())
- //表示整除,因为py没有类型自动,所以/10要整除a//=10
- l=l.replace(i,'')
replace不会改变,需要重写赋值给l
strip也是不会改变的,所以要再赋值给s s=s.strip()
不是tolower是lower strip去除空格
编程
# l=list(input().split())
l=input().split()
# l = [input().split()]
# split默认返回列表如果加中括号会变成[['1','2']]
#输入按空格分隔
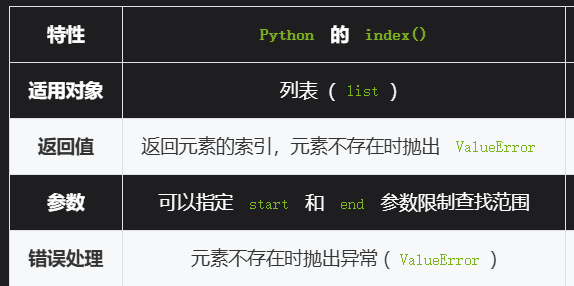
l.sort()
#字母升序排序
print(*l,sep=' ',end='')
'''
*l:使用星号操作符将列表 l 中的元素解包为独立的参数,即将列表中的每个元素作为单独的参数传递给 print() 函数。
sep=' ':指定在打印多个参数时,使用空格 ' ' 作为分隔符。
'''
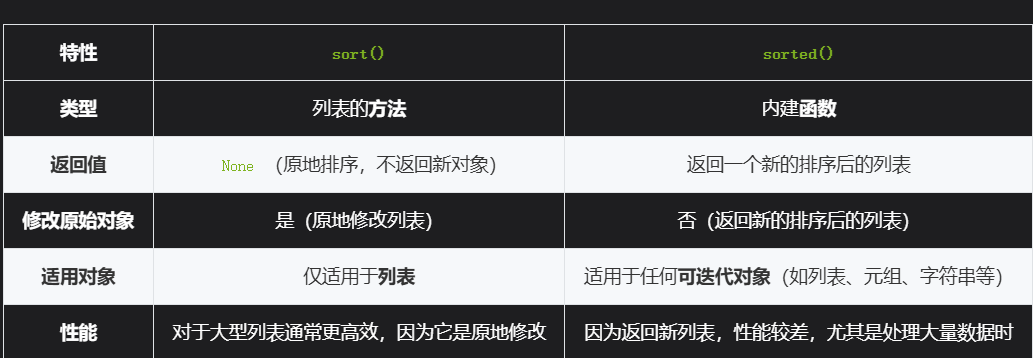
str.index(substring, start=0, end=len(str))
- 列表可以进行相加
s1=list(input().split())
s2=list(input().split())
s=s1+s2
print(*[i for i in s if i not in s1 or i not in s2])
- 特殊图案输出可以预处理
n=int(input())
s="ABCDEFGHIJK"
for i in range(n):
print(s[:i+1:])
- 当输入为列表要用eval智能读入
l=eval(input())
#因为[1,2],所以不能用list或
s=sorted(set(l),key=l.index)
#使用集合去重但是原序输出
print(*s,sep=' ')
print(*sorted(s, reverse=True), sep='\n',end='')
#从大到小
s.append(sum(l))
- 集合运算
![image]()

9,
l=eval(input())
s=[]
for i in range(1,6):
if i not in l:
s.append(i)
print(*s,sep=' ')
s=[]
for i in range(6,11):
if i not in l:
s.append(i)
print(*s,sep=' ')
- 众数
while 1:
try:
n=int(input())
l=list(map(int,input().split()))
num=max(l,key=l.count)
print(num,l.count(num))
except:
break
- 字典
dic = dict(zip(color, flower))
d1=eval(input())
d2=eval(input())
for i,j in d1.items():
d2[i]=d2.get(i,0)+j
d2=list(d2.items())
#要用d2的键值对.传入d2默认为键
d2.sort(key=lambda x: ord(x[0]) if type(x[0]) == str else x[0])
# d2 = sorted(d2, key=lambda x: ord(x[0]) if type(x[0]) == str else x[0])
#if else没有冒号
for i,j in d2:
# d2 已经是一个 列表,但列表中的每个元素仍然是一个 二元组(键值对)。
# 你可以使用 for i, j in d2 来解包每个二元组
if type(i)==str:
print("'%s':%d" %(i,j))
else:
print("%d:%d" %(i,j))
- 校验身份证
l1 = [7, 9, 10, 5, 8, 4, 2, 1, 6, 3, 7, 9, 10, 5, 8, 4, 2]
l2 = [1, 0, 'X', 9, 8, 7, 6, 5, 4, 3, 2]
n = int(input())
cnt = 0
for i in range(n):
flag = 1
sum1 = 0
s = input()
for j in range(17):
if s[j].isdigit() != 0:
sum1 += int(s[j]) * l1[j]
else:
flag=0
break
if str(l2[sum1 % 11]) != s[17] or flag == 0:
flag = 0
print(s)
if flag == 1:
cnt += 1
if cnt == n:
print("All passed")
- 数字出现次数,利用count,(字符串,元组列表)
number,digit=str(number),str(digit)
return number.count(digit)
- 标题化
def acronym(phrase):
text=""
l=phrase.split()
#写成//s+会导致错误
# str.split() 是普通的字符串方法,它只会按照单个字符进行分割
# 而不能理解正则表达式
for i in l:
text+=i[0].upper()
return text
- 全排列
from itertools import *
n=int(input())
for i in permutations(int(x) for x in range(1,n+1)):
print(*i,sep='',end='\n')
- 元组或列表里的数字和
def cycle(l):
sum=0
for i in l:
if isinstance(i,int):
sum+=i
elif isinstance(i,list) or isinstance(i,tuple):
sum+=cycle(i)
return sum
l=eval(input())
print(cycle(l))
- 指定层元素个数
dic={}
def gett(lst,n):
dic[n]=dic.get(n,0)+len(lst)
for i in lst:
if isinstance(i,list):
gett(i,n+1)
l=eval(input())
n=int(input())
gett(l,1)
print(dic.get(n,0))
- 分数
else:
l = a.split("\\")
print(f(l[0]) / f(l[1]))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号